import numpy as np
为提高运算效率,ndarray数组值的类型默认相同,创建时自动指定默认数据类型(内存占用最大的值类型)
默认浮点类型(float)
| numpy方法 | 解释 |
|---|---|
| np.dtype | 指定当前numpy对象的整体数据, 见下一个表格 |
| np.itemsize | 对象中每个元素的大小, 单位字节 |
| np.size | 对象元素的个数, 相当于np.shape中的n*m值 |
| np.shape | 轴, 查看数组形状, 对于矩阵, n行m列 |
| np.ndim | 秩 |
| np.isnan(list) | 筛选出nan值 |
| np.iscomplex(list) | 筛选出非复数 |
| ~ | 取补运算符 |
| np.array(数组, dtype=np.bool) | 自定义数组类型 |
| np.astype(np.bool) | 转换数组类型 |
| np.mat() | 将python 列表转化成矩阵 |
| np.mat().getA() | 将matrix对象转成ndarray对象 |
| np.matrix() | 同上 |
| np.asmatrix() | 将ndarray对象转成matrix对象 |
| np.tile() | 重复某个数组。比如tile(A,n),功能是将数组A重复n次,构成一个新的数组传送门 |
| np.I | 矩阵求逆 |
| np.T | 矩阵转置, 行变列, 列变行, 对角线翻转矩阵 |
| np.tolist() | 转换成python列表, 用于和python原生结合写程序 |
| np.multiply(x, y) | 矩阵x 矩阵y相乘 |
| np.unique() | 数组驱虫, 并且从小到大生成一个新的数组 |
| np.arange | 同python range() |
| np.arange(24).reshape((2, 3, 4)) | 创建一个2维3行4列的数组, 必须能被给定的长度除开, 可以索引和切片 |
| np.arange(24).resize((2, 3, 4)) | 同上, 会修改原值 |
| np.linspace(x, y, z) | 等间距生成, x起始, y截止, z步长 |
| np.ones(x) | 生成都是x的数组, 可传递三维数组, 几行几列, 具体的个数 |
| np.zeros(x) | 生成都是0的数组 |
| np.full([x, y], z) | 自定义模板数组, 生成x行y列都是z的数组 |
| np.eye(x) | 创建一个正方的x*x单位的矩阵, 对角线为1, 其余为0 |
| np.flatten() | 数组降维, 不改变 原值 |
| np.random.rand(x, y, z) | 生成一个一维x随机数或生成x*y的随机数组 |
| np.random.randn(x, y) | 正态分布随机数 |
| np.random.randint(low, high, (shape)) | 整数随机数 |
| np.random.normal(loc, scale, (size)) | 从指定正态分布中抽取样本, loc为概率分布的均匀值, 标准差scale |
| np.random.seed(s) | 给一个随机数字固定 |
| np.randomunifrom(low, high, (size)) | 均匀分布的数组, 有小数 |
| np.random.shuffle(a) | 将数组a的第0轴(最外维度)进行随机排列(洗牌), 改变数组a, 行边列不变 |
| np.random.permutation(a) | 同上, 不改变数组a |
| np.random.choice(a, size=None, replace=False, p=数组a/np.sum(b)) | 从一维数组a中以概率p抽取元素,形成size形状新数组,replace表示是否可以重用元素,默认为False,p为抽取概率,本位置越高,抽取概率越高 |
| np.sum(axis=None) | 求和, axis=0为列, 1为行 |
| np.argsort() | 矩阵每个元素坐标排序 |
| np.sort(axix=None) | 从小打大排序 |
| -np.sort(axis=None) | 从大到小排序 |
| np.sort_values(‘字段’, ascending=False) | 排序,升序排列 |
| np.mean(axis=None) | 平均数 |
| np.average(axis=None,weights=None) | 加权平均,weights加权值,不设为等权重,例子[10, 5, 1],每列分别X10,X5,X1在/(10+5+1) |
| np.var(axis=None) | 方差:各数与平均数之差的平方的平均数 |
| np.std(axis=None) | 标准差:方差平方根 |
| np.min(axis=None) | 最小值 |
| np.argmin(axis=None) | 求数组中最小值的坐标 |
| np.median(axis=None) | 中位数 |
| np.ptp(axis=None) | 元素最大值与最小值的差 |
| np.cumsum() | 累加,cumsum和cumprod之类的方法不聚合,产生一个中间结果组成的数组,默认一维数组,1为按原样 |
| np.cumprod() | 累乘 |
| np.count_nonzero(arr > 0) | 计数非0值个数,布尔值会被强制转换为1和0,可以使用sum()对布尔型数组中的True值计数 |
| np.bools.any() | 测试数组中是否存在一个或多个True |
| np.bools.all() | 数组中所有值是否都是True, 测试有没有空值 |
| np.bools.all() | 数组中所有值是否都是True, 测试有没有空值 |
| np.bools.all() | 数组中所有值是否都是True, 测试有没有空值 |
| np.dtype类型 | |
|---|---|
| np.bool | 布尔值 |
| np.int | 整型 |
| np.float | 浮点型 |
| np.complex | 复数 |
| np.object | 对象 |
| np.string_ | ASCII字符 |
| np.unicode_ | Unicode所有字符, 字节数平台决定 |
nparray索引和切片
# 创建0-23, 共2个三行四列的数组 a = np.arange(24).reshape((2,3,4)) """ array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) """ # 一个三维数组,提取12的话,python list是a[1][0][0], ndarange可以是a[1,0,0],也可以是[1][0][0] # 可以用负数 # a[1,:] 选取第一维数组里面所有 # a[:,1] 选取所有维度,第一行 # a[1,:,3] 选取第一维度数组所有行里的第三个值 # a[:,0:2,1:3] 选取所有维度的第0行到第2行, 取元素第1个到第3个 # a[:,:,::2] 选取所有维度, 所有行, 步长为2的所有行 # ------------------------------------------------------------------------- # 例子,布尔型索引 names = np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe']) data = np.arange(28).reshape(7,4) names[names == 'Bob'] # array(['Bob', 'Bob'], dtype='<U4') names == 'Bob' # array([ True, False, False, True, False, False, False], dtype=bool) # 姓名数组可以跟数字数字一一对应 data[names == 'Bob'] # array([[ 0, 1, 2, 3], # [12, 13, 14, 15]]) # 可以将布尔型数组跟切片、整数、整数序列混合使用 data[names == 'Bob',2:] # array([[ 2, 3], # [14, 15]]) # 组合多个布尔型索引,进行逻辑运算 # 组合条件,逻辑运算符:& 且,| 或,非(!= 或 ~) # 并集,交集 (names == 'Bob') | (names == 'Will') # array([ True, False, True, True, True, False, False], dtype=bool) # 且,没有交集 (names == 'Bob') & (names == 'Will') # array([False, False, False, False, False, False, False], dtype=bool) -------------------------------------------------------------------------- // 数组修改 a[:,0:2] = 1 # 切片批量修改 a[:,0:2] = [[11,12],[13,14]] # 切片批量修改 names[names == 'Bob'] = 'aaa' # 修改单个 a为数组,a > 1 返回为true的索引 np.where(a > 2) # 返回索引 # (array([0, 0], dtype=int64), # array([0, 1], dtype=int64), # array([1, 0], dtype=int64)) # 也可以用作三元表达式,满足条件,返回x,不满足返回y np.where(条件,x, y)
import pandas as pd s = pd.Series(np.random.randint(0, 7, size=10)) # 统计出现的个数,左边是下标,右边是出场的次数 s.value_counts() # 统计个数
// Numpy数据存取
- numpy提供了便捷的内部文件存取,将数据存为np专用的npy(二进制格式)或npz(压缩打包格式)格式
- npy格式以二进制存储数据的,在二进制文件第一行以文本形式保存了数据的元信息(维度,数据类型),可以用二进制工具查看查看内容
- npz文件以压缩打包文件存储,可以用压缩软件解压
a = np.array([['张三','李四','王五','赵六'],['11','12','13','14','15']]) b = np.arange(24).reshape((2,3,4)) np.save('a.npy',a) # 存为.npy文件 np.savez("a.npz", ar0 = a, ar1 = b) # 多个数组存入一个.npz压缩包 c = np.load('x.npy') # .npy文件读入数组 d = np.load("y.npz") # .npz压缩包读入 #d["ar0"] # 单独输出数组
// Numpy存储CSV文件
# 存储csv文件,本身是ASCII字符,不能存储非ASCII字符串,csv文件只能存储一维、二维数据,不能存储多维数据 np.savetxt(frame,array,fmt='%.18e',delimiter=None)

// 读取csv文件
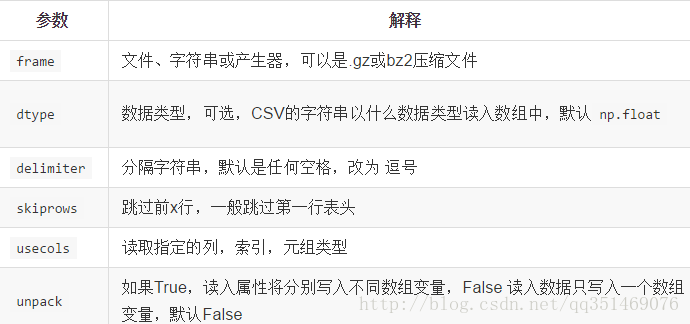
# 读取csv文件 np.loadtxt(frame,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False) # 去掉b'0.00'中的b np.loadtxt('a.csv', dtype=bytes, delimiter=',').astype(str)
// ndarray-数组操作
# axis=0行 1列 np.sort(a,axis=None) # 从小到大 -np.sort(-a, axis=None) # 从大到小 # ndarray转为python list,用于和Python原生结合编写程序 .tolist() # 数组去重,把重复去掉,并且按从小到大生成一个新的数组 .unique(a)
// 数组拼接(数组合并)
ndarray是保存在内存中的一段连续值,增加值操作会重新分配内存,一般不推荐,可以用合并数组的方式模拟增加值
将两个或多个数组合并成一个新数组
# 数组合并, 如果数组不对应,需要先转置,在axis=1进行拼接 np.concatenate((a1,a2,...), axis=0)
// 数组删除
删除操作不能精确选取元素,常被索引和切片查询赋值新变量代替
np.delete(arr, obj, axis=None) # 删除多列,会把没有被选中的其他值也删掉,有损失 b3 = np.delete(a, [1,2], axis=1)
// Numpy-数据运算
矢量化运算也叫向量化运算,
- 标量:一个数值
- 广播机制:自动补齐,数组与标量之间的运算作用于数组的每一个元素
# 三维数组除以标量运算,列表中每一个值都会返回 # 两个不同维度进行计算,维度小的会变成大的维度在进行运算,然后每个值单独做计算 a/a.mean()
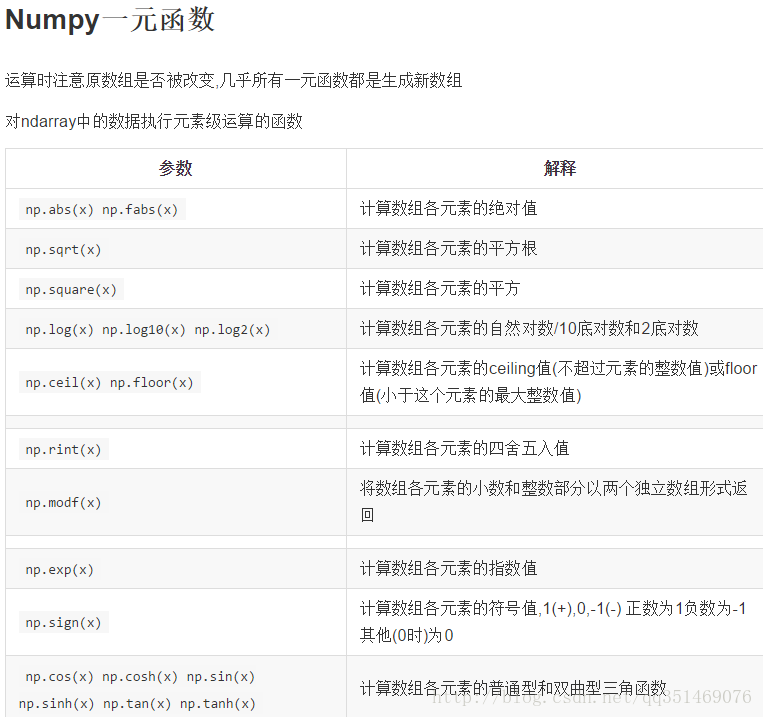

// Numpy矩阵运算
- NumPy有两种不同的数据类型:数组ndarray和矩阵matrix
- matrix是array的分支,用于矩阵计算
# 转换成矩阵对象 m = np.matrix(x) # 每个数值+5 m + 5 # 有复杂的运算体系,但不是相加那么简单 m * 5