以下内容参考 cousera 吴恩达 机器学习课程
1. Bias 和 Variance 的定义
Bias and Variance 对于改进算法具有很大的帮助作用,在bias和Variance的指引之下,我们可以有方向性的对算法进行改进。
模型较简单时,可能导致Bias,相反模型较为复杂的时候,容易导致high Variance。

如下图所示,随着模型复杂度的增加,训练数据集上的误差将会减小,而交叉验证集上的误差是先减小后增大。所以根据在训练集和交叉验证集上的误差大小就可以判断模型是除了bias问题还是variance问题。

2. 正则化与Bias和Variance
正则化的时候,如果lamda特别大,容易导致欠拟合,high bias
如果lamda较小,或者说没有引入正则化,容易导致过拟合high variance
所以可以画出学习曲线来表征正则化参数lamda和Error的关系:
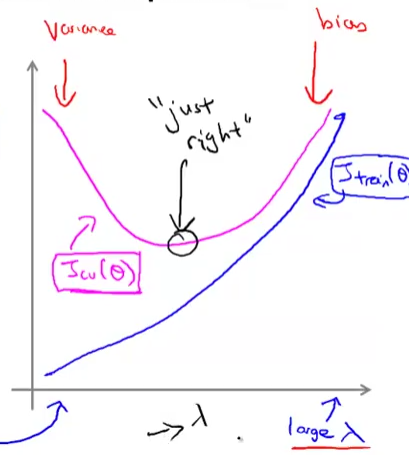
如上图所示,lamda较小的时候,容易产生过拟合,high variance,当lamda较大的时候,容易产生欠拟合high variance。我们的目标是找到途中测试集上Error最小的点。
3. 绘制学习曲线
绘制样本数量与 Error 的关系,得到不同的虚线,暗示了模型可能存在的Bias和Variance的问题。



4. Debuging Learning Model
