史上最全的C++ STL 容器大礼包
为什么(C++)比(C)更受人欢迎呢?除了(C++) 的编译令人感到更舒适,(C++)的标准模板库((STL))也占了很重要的原因。当你还在用手手写快排、手写二叉堆,挑了半天挑不出毛病的时候,(C++)党一手(STL)轻松(AC),想不嫉妒都难。
所以这篇随笔就带大家走进博大精深的(C++STL),系统讲解各种(STL)容器及其用法、作用。在学习(STL)的时候认真体会(STL)语法及功能,提升自己在算法竞赛及程序设计中解题、码代码的能力。
话不多说,现在开始:
浅谈C++ STL vector 容器
本篇随笔简单介绍一下(C++STL)中(vector)容器的使用方法和常见的使用技巧。(vector)容器是(C++STL)的一种比较基本的容器。我们在学习这个容器的时候,不仅要学到这个容器具体的使用方法,更要从中体会(C++STL)的概念。
vector容器的概念
(vector)在英文中是矢量的意思。如果学过高中数学必修四的平面向量或者高中物理必修一的第一节课对其会有一个直观的认识。但是在(STL)中,(vector)和物理、几何等东西没有任何关系。
我们知道,一个数组必须要有固定的长度,在开一个数组的时候,这个长度也就被静态地确定下来了。但是(vector)却是数组的“加强版”,对于一组数据来讲,你往(vector)里存多少数据,(vector)的长度就有多大。也就是说,我们可以将其理解为一个“变长数组”。
事实上,(vector)的实现方式是基于倍增思想的:假如(vector)的实际长度为(n),(m)为(vector)当前的最大长度,那么在加入一个元素的时候,先看一下,假如当前的(n=m),则再动态申请一个(2m)大小的内存。反之,在删除的时候,如果(nge frac{m}{2}),则再释放一半的内存。
vector容器的声明
(vector)容器存放在模板库:#include<vector>里,使用前需要先开这个库。
(vector)容器的声明遵循(C++STL)的一般声明原则:
容器类型<变量类型> 名称
例:
#include<vector>
vector<int> vec;
vector<char> vec;
vector<pair<int,int> > vec;
vector<node> vec;
struct node{...};
vector容器的使用方法
(vector)容器的使用方法大致如下表所示:
| 用法 | 作用 |
|---|---|
vec.begin(),vec.end() |
返回vector的首、尾迭代器 |
vec.front(),vec.back() |
返回vector的首、尾元素 |
vec.push_back() |
从vector末尾加入一个元素 |
vec.size() |
返回vector当前的长度(大小) |
vec.pop_back() |
从vector末尾删除一个元素 |
vec.empty() |
返回vector是否为空,1为空、0不为空 |
vec.clear() |
清空vector |
除了上面说过的那些之外,我们的(vector)容器是支持随机访问的,即可以像数组一样用([\,\,])来取值。请记住,不是所有的(STL)容器都有这个性质!在(STL)的学习过程中,一定要清楚各个容器之间的异同!
浅谈C++ STL queue 容器
本篇随笔简单介绍一下(C++STL)中(queue)容器的使用方法和常见的使用技巧。(queue)容器是(C++STL)的一种比较基本的容器。我们在学习这个容器的时候,不仅要学到这个容器具体的使用方法,更要从中体会(C++STL)的概念。
queue容器的概念
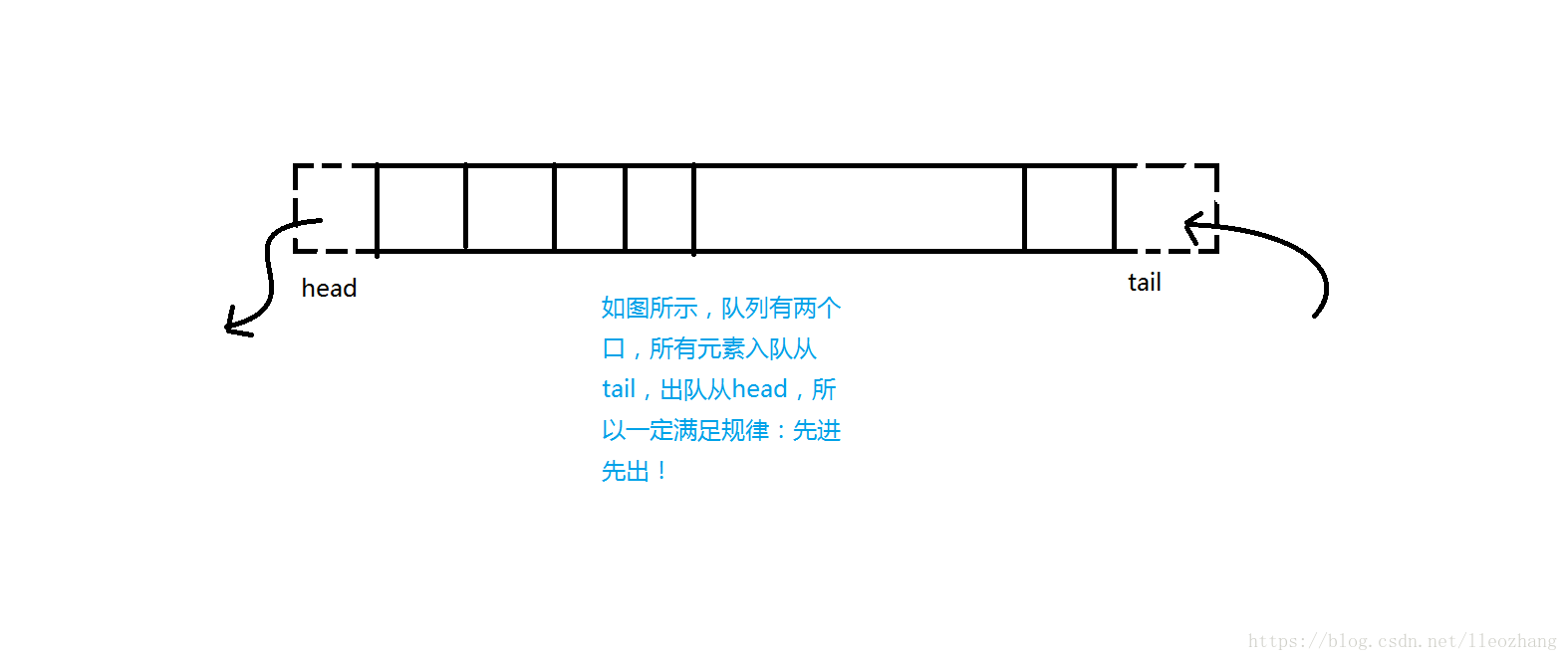
(queue)在英文中是队列的意思。队列是一种基本的数据结构。而(C++STL)中的队列就是把这种数据结构模板化了。我们可以在脑中想象买票时人们站的排队队列。我们发现,在一个队列中,只可以从队首离开,从队尾进来(没有插队,想啥呢)。即一个先进先出的数据结构。
上图理解:
queue容器的声明
(queue)容器存放在模板库:#include<queue>里,使用前需要先开这个库。
(queue)容器的声明遵循(C++STL)的一般声明原则:
容器类型<变量类型> 名称
例:
#include<queue>
queue<int> q;
queue<char> q;
queue<pair<int,int> > q;
queue<node> q;
struct node{...};
queue容器的使用方法
(queue)容器的使用方法大致如下表所示:
| 用法 | 作用 |
|---|---|
q.front(),q.back() |
返回queue的首、尾元素 |
q.push() |
从queue末尾加入一个元素 |
q.size() |
返回queue当前的长度(大小) |
q.pop() |
从queue末尾删除一个元素 |
q.empty() |
返回queue是否为空,1为空、0不为空 |
注意,虽然(vector)和(queue)是两种最基本的(STL)容器,但请记住它们两个不是完全一样的。就从使用方法来讲:
(queue)不支持随机访问,即不能像数组一样地任意取值。并且,(queue)并不支持全部的(vector)的内置函数。比如(queue)不可以用(clear())函数清空,清空(queue)必须一个一个弹出。同样,(queue)也并不支持遍历,无论是数组型遍历还是迭代器型遍历统统不支持,所以没有(begin(),end();)函数,使用的时候一定要清楚异同!
浅谈C++ STL stack 容器
本篇随笔简单介绍一下(C++STL)中(stack)容器的使用方法和常见的使用技巧。
stack容器的概念
(stack)在英文中是栈的意思。栈是一种基本的数据结构。而(C++STL)中的栈就是把这种数据结构模板化了。
栈的示意图如下:这是一个先进后出的数据结构。这非常重要!!
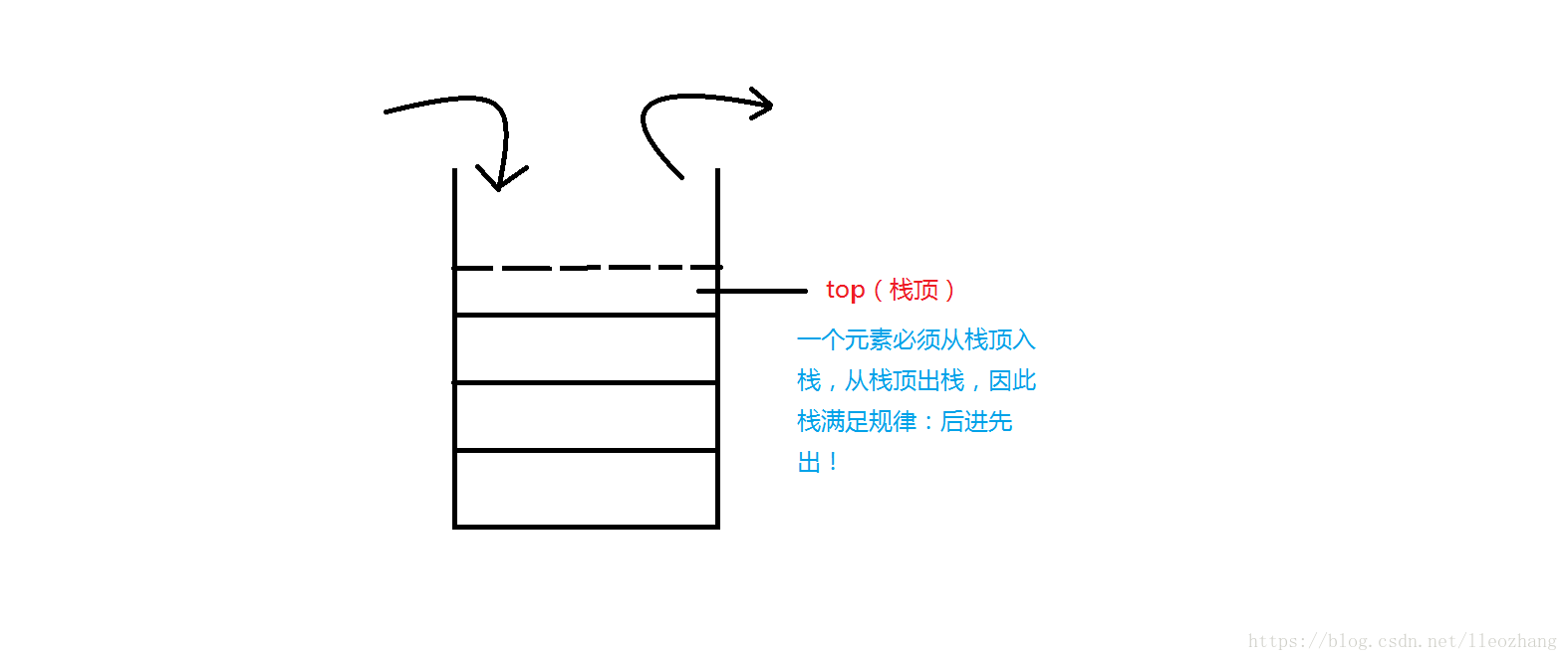
事实上,(stack)容器并不是一种标准的数据结构,它其实是一个容器适配器,里面还可以存其他的(STL)容器。但那种使用方法过于高深而且不是很常用,所以在此不与介绍。请有兴趣的读者自行查询资料。
stack容器的声明
(stack)容器存放在模板库:#include<stack>里,使用前需要先开这个库。
(stack)容器的声明遵循(C++STL)的一般声明原则:
容器类型<变量类型> 名称
例:
#include<stack>
stack<int> st;
stack<char> st;
stack<pair<int,int> > st;
stack<node> st;
struct node{...};
stack容器的使用方法
(stack)容器的使用方法大致如下表所示:
| 用法 | 作用 |
|---|---|
st.top() |
返回stack的栈顶元素 |
st.push() |
从stack栈顶加入一个元素 |
st.size() |
返回stack当前的长度(大小) |
st.pop() |
从stack栈顶弹出一个元素 |
st.empty() |
返回stack是否为空,1为空、0不为空 |
浅谈C++ STL string容器
本篇随笔简单讲解一下(C++STL)中(string)容器的使用方法及技巧。
string容器的概念
其实(string)并不是(STL)的一种容器,但是由于它的使用方法等等和(STL)容器很像,所以就把它当作(STL)容器一样介绍。
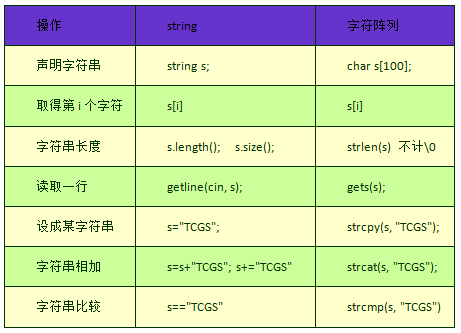
其实(string)容器就是个字符串,这通过它的英文译名就能看得出来。但是对于字符串以及字符串的相关操作,可能读者还是对普通的(C/C++)的#include<cstring>,#include<string.h>库更熟悉一些。我丝毫不否认这些传统字符操作的经典性和实用性,但是由于它们函数定义的局限,有些时候对于一些特殊的读入、输出、遍历等要求,它的操作并不如(string)容器好用。
比如,要求读入一群中间可能带空格的字符串,如果用传统方式进行读入,可能就会很麻烦,但是如果使用(string)的话,一个读入函数就可以完全搞定。
string容器的使用方法及与传统字符读入的对比
一张图解决问题。
详解C++ STL priority_queue 容器
本篇随笔简单介绍一下(C++STL)中(priority_queue)容器的使用方法和常见的使用技巧。
priority_queue容器的概念
(priority_queue)在英文中是优先队列的意思。
队列是一种基本的数据结构。其实现的基本示意图如下所示:
而(C++STL)中的优先队列就是在这个队列的基础上,把其中的元素加以排序。其内部实现是一个二叉堆。所以优先队列其实就是把堆模板化,将所有入队的元素排成具有单调性的一队,方便我们调用。
priority_queue容器的声明
(priority_queue)容器存放在模板库:#include<queue>里,使用前需要先开这个库。
这里需要注意的是,优先队列的声明与一般(STL)模板的声明方式并不一样。事实上,我认为其是(C++STL)中最难声明的一个容器。
大根堆声明方式:
大根堆就是把大的元素放在堆顶的堆。优先队列默认实现的就是大根堆,所以大根堆的声明不需要任何花花肠子,直接按(C++STL)的声明规则声明即可。
#include<queue>
priority_queue<int> q;
priority_queue<string> q;
priority_queue<pair<int,int> > q;
(C++)中的(int,string)等类型可以直接比较大小,所以不用我们多操心,优先队列自然会帮我们实现。但是如果是我们自己定义的结构体,就需要进行重载运算符了。关于重载运算符的讲解,请参考这篇博客:
小根堆声明方式
大根堆是把大的元素放堆顶,小根堆就是把小的元素放到堆顶。
实现小根堆有两种方式:
第一种是比较巧妙的,因为优先队列默认实现的是大根堆,所以我们可以把元素取反放进去,因为负数的绝对值越小越大,那么绝对值较小的元素就会被放在前面,我们在取出的时候再取个反,就瞒天过海地用大根堆实现了小根堆。
第二种:
小根堆有自己的声明方式,我们记住即可(我也说不明白道理):
priority_queue<int,vector<int>,greater<int> >q;
注意,当我们声明的时候碰到两个"<"或者">"放在一起的时候,一定要记得在中间加一个空格。这样编译器才不会把两个连在一起的符号判断成位运算的左移/右移。
priority_queue容器的使用方法
(priority_queue)容器的使用方法大致如下表所示:
| 用法 | 作用 |
|---|---|
q.top() |
返回priority_queue的首元素 |
q.push() |
向priority_queue中加入一个元素 |
q.size() |
返回priority_queue当前的长度(大小) |
q.pop() |
从priority_queue末尾删除一个元素 |
q.empty() |
返回priority_queue是否为空,1为空、0不为空 |
注意:priority_queue取出队首元素是使用(top),而不是(front),这点一定要注意!!
浅谈C++ STL deque 容器
本篇随笔简单介绍一下(C++STL)中(deque)容器的使用方法及常见使用技巧。
deque容器的概念
(deque)的意义是:双端队列。队列是我们常用而且必须需要掌握的数据结构。(C++STL)中的确有模拟队列的模板:#include<queue>中的(queue)和(priority\_queue)。队列的性质是先进先出,即从队尾入队,从队首出队。而(deque)的特点则是双端进出,即处于双端队列中的元素既可以从队首进/出队,也可以从队尾进/出队。
即:(deque)是一个支持在两端高效插入、删除元素的线性容器。
(deque)模板存储在(C++STL)的#include<deque>中。
deque容器的使用方法
因为(deque)容器真的和(queue)容器大体相同,其使用方式也大体一致。下面把(deque)容器的使用方式以列表的方式放在下面:
| 用法 | 作用 |
|---|---|
q.begin(),q.end() |
返回deque的首、尾迭代器 |
q.front(),q.back() |
返回deque的首、尾元素 |
q.push_back() |
从队尾入队一个元素 |
q.push_front() |
从队头入队一个元素 |
q.pop_back() |
从队尾出队一个元素 |
q.pop_front() |
从队头出队一个元素 |
q.clear() |
清空队列 |
除了这些用法之外,(deque)比(queue)更优秀的一个性质是它支持随机访问,即可以像数组下标一样取出其中的一个元素。
即:q[i]。
deque的一些用途
由于本蒟蒻水平有限,暂时想不出deque应用的一些实例。但有一点是肯定的:(deque)容器可以被应用到(SPFA)算法的(SLF)优化。其具体应用方式可见这篇博客:
详解C++ STL set 容器
本篇随笔简单介绍一下(C++STL)中(set)容器的使用方法及常见使用技巧。
set容器的概念和性质
(set)在英文中的意义是:集合。(set)容器也的确“人如其名”,实现了这个集合的功用。
高中数学必修一集合那章(高一以下的小伙伴不用慌,不讲数学只讲概念),关于集合的性质,给出了三个概念:无序性、互异性、确定性。
那么,(set)容器的功用就是维护一个集合,其中的元素满足互异性。
我们可以将其理解为一个数组。这个数组的元素是两两不同的。
这个两两不同是指,如果这个(set)容器中已经包含了一个元素(i),那么无论我们后续再往里假如多少个(i),这个(set)中还是只有一个元素(i),而不会出现一堆(i)的情况。这就为我们提供了很多方便。
但是,需要额外说明的是,刚刚说集合是有无序性的,但是(set)中的元素是默认排好序(按升序排列)的。(稍微说一句,(set)容器自动有序和快速添加、删除的性质是由其内部实现:红黑树(平衡树的一种)。这个东西过于高深我不会,所以不予过多介绍,有兴趣的小伙伴可以自行浏览相关内容。)
set容器的声明
(set)容器的声明和大部分(C++STL)容器一样,都是:容器名<变量类型> 名称的结构。前提需要开#include
#include<set>
set<int> s;
set<char> s;
set<pair<int,int> > s;
set<node> s;
struct node{...};
set容器的使用
其实,(C++STL)容器的使用方式都是差不多的。我们完全可以举一反三地去类比。与(bitset)重定义了许多奇形怪状新的函数之外,其他都是大致相同的。所以笔者在此不再做幼稚的介绍,大家都是竞赛狗,应该都能自己看明白。
s.empty();
(empty())函数返回当前集合是否为空,是返回1,否则返回0.
s.size();
(size())函数返回当前集合的元素个数。
s.clear();
(clear())函数清空当前集合。
s.begin(),s.end();
(begin())函数和(end())函数返回集合的首尾迭代器。注意是迭代器。我们可以把迭代器理解为数组的下标。但其实迭代器是一种指针。这里需要注意的是,由于计算机区间“前闭后开”的结构,(begin())函数返回的指针指向的的确是集合的第一个元素。但(end())返回的指针却指向了集合最后一个元素后面一个元素。
s.insert(k);
(insert(k))函数表示向集合中加入元素(k)。
s.erase(k);
(erase(k))函数表示删除集合中元素(k)。这也反映了(set)容器的强大之处,指哪打哪,说删谁就删谁,完全省略了遍历、查找、复制、还原等繁琐操作。更不用像链表那种数据结构那么毒瘤。直接一个函数,用(O(logn))的复杂度解决问题。
s.find(k);
(find(k))函数返回集合中指向元素(k)的迭代器。如果不存在这个元素,就返回(s.end()),这个性质可以用来判断集合中有没有这个元素。
其他好用的函数
下面介绍一些不是很常用,但是很好用的(set)容器的内置函数
s.lower_bound(),s.upper_bound();
熟悉(algorithm)库和二分、离散化的小伙伴会对这两个函数比较熟悉。其实这两个函数比较常用。但是对于(set)集合来讲就不是很常用。其中(lower\_bound)返回集合中第一个大于等于关键字的元素。(upper\_bound)返回集合中第一个严格大于关键字的元素。
s.equal_range();
这个东西是真的不常用...可能是我太菜了。
这个东西返回一个(pair)(内置二元组),分别表示第一个大于等于关键字的元素,第一个严格大于关键字的元素,也就是把前面的两个函数和在一起。如果有一个元素找不到的话,就会返回(s.end())。
详解C++ STL multiset 容器
本篇随笔简单介绍一下(C++STL)中(multiset)容器的使用方法及常见使用技巧。
multiset容器的概念和性质
(set)在英文中的意义是:集合。而(multi-)前缀则表示:多重的。所以(multiset)容器就叫做:有序多重集合。
(multiset)的很多性质和使用方式和(set)容器差不了多少。而(multiset)容器在概念上与(set)容器不同的地方就是:(set)的元素互不相同,而(multiset)的元素可以允许相同。
所以,关于一些(multiset)容器和(set)容器的相同点,本篇博客就不加以赘述了。需要学习的小伙伴推荐进入本蒟蒻的这篇博客:
与set容器不太一样的地方:
s.erase(k);
(erase(k))函数在(set)容器中表示删除集合中元素(k)。但在(multiset)容器中表示删除所有等于(k)的元素。
时间复杂度变成了(O(tot+logn)),其中(tot)表示要删除的元素的个数。
那么,会存在一种情况,我只想删除这些元素中的一个元素,怎么办呢?
可以妙用一下:
if((it=s.find(a))!=s.end())
s.erase(it);
(if)中的条件语句表示定义了一个指向一个(a)元素迭代器,如果这个迭代器不等于(s.end()),就说明这个元素的确存在,就可以直接删除这个迭代器指向的元素了。
s.count(k);
(count(k))函数返回集合中元素(k)的个数。(set)容器中并不存在这种操作。这是(multiset)独有的。
C++ STL bitset 容器详解
本篇随笔讲解(C++STL)中(bitset)容器的用法及常见使用技巧。
(bitset)容器概论
(bitset)容器其实就是个(01)串。可以被看作是一个(bool)数组。它比(bool)数组更优秀的优点是:节约空间,节约时间,支持基本的位运算。在(bitset)容器中,(8)位占一个字节,相比于(bool)数组(4)位一个字节的空间利用率要高很多。同时,(n)位的(bitset)在执行一次位运算的复杂度可以被看作是(n/32),这都是(bool)数组所没有的优秀性质。
(bitset)容器包含在(C++)自带的(bitset)库中。
#include<bitset>
(bitset)容器的声明
因为(bitset)容器就是装(01)串的,所以不用在< >中装数据类型,这和一般的(STL)容器不太一样。< >中装(01)串的位数。
如:(声明一个(10^5)位的(bitset))
bitset<100000> s;
对(bitset)容器的一些操作
1、常用的操作函数
和其他的(STL)容器一样,对(bitset)的很多操作也是由自带函数来实现的。下面,我们来介绍一下(bitset)的一些常用函数及其使用方法。
- (count())函数
(count),数数的意思。它的作用是数出(1)的个数。即(s.count())返回(s)中有多少个(1).
s.count();
- (any()/none())函数
(any),任何的意思。(none),啥也没有的意思。这两个函数是在检查(bitset)容器中全(0)的情况。
如果,(bitset)中全都为(0),那么(s.any())返回(false),(s.none())返回(true)。
反之,假如(bitset)中至少有一个(1),即哪怕有一个(1),那么(s.any())返回(true),(s.none())返回(false).
s.any();
s.none();
- (set())函数
(set())函数的作用是把(bitset)全部置为(1).
特别地,(set())函数里面可以传参数。(set(u,v))的意思是把(bitset)中的第(u)位变成(v,vin 0/1)。
s.set();
s.set(u,v);
- (reset())函数
与(set())函数相对地,(reset())函数将(bitset)的所有位置为(0)。而(reset())函数只传一个参数,表示把这一位改成(0)。
s.reset();
s.reset(k);
- (flip())函数
(flip())函数与前两个函数不同,它的作用是将整个(bitset)容器按位取反。同上,其传进的参数表示把其中一位取反。
s.flip();
s.flip(k);
2、位运算操作在(bitset)中的实现
(bitset)的作用就是帮助我们方便地实现位运算的相关操作。它当然支持位运算的一些操作内容。我们在编写程序的时候对数进行的二进制运算均可以用在(bitset)函数上。
比如:
~:按位取反
&:按位与
|:按位或
^:按位异或
<< >>:左/右移
==/!=:比较两个(bitset)是否相等。
关于位运算的相关知识,不懂的小伙伴请戳这里:
另外,(bitset)容器还支持直接取值和直接赋值的操作:具体操作方式如下:
s[3]=1;
s[5]=0;
这里要注意:在(bitset)容器中,最低位为(0)。这与我们的数组实现仍然有区别。
(bitset)容器的实际应用
(bitset)可以高效率地对(01)串,(01)矩阵等等只含(0/1)的题目进行处理。其中支持的许多操作对我们处理数据非常有帮助。如果碰到一道(0/1)题,使用(bitset)或许是不错的选择。
详解C++ STL map 容器
本篇随笔简单讲解一下(C++STL)中的(map)容器的使用方法和使用技巧。
map容器的概念
(map)的英语释义是“地图”,但(map)容器可和地图没什么关系。(map)是“映射容器”,其存储的两个变量构成了一个键值到元素的映射关系。
比如下图:
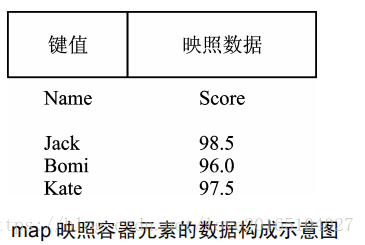
我们可以根据键值快速地找到这个映射出的数据。
(map)容器的内部实现是一棵红黑树(平衡树的一种),因为比较复杂而且与理解并无多大关系,所以不予介绍,有兴趣的读者可以自己查阅相关的资料。
map容器的声明
(map)容器存在于(STL)模板库#include<map>中。使用的时候需要先开这个库。
比如:
#include<map>
map<int,char> mp;
这就建立了一个从一个整型变量到一个字符型变量的映射。
map容器的用法
因为(map)容器和(set)容器都是使用红黑树作为内部结构实现的。所以其用法比较相似。但由于二者用途大有不同,所以其用途还有微妙的差别。对于初学者来讲,其更容易涉及到的应该是(vector)容器、(queue)容器等,但是对于大佬们,经常用个(set)、(map),没事再用(bitset)压一压状态这都是家常便饭。
如果有想学习(set,bitset)容器的,请参考下面两篇博客,讲的比较详细:
其实,(C++STL)容器的使用方式都是差不多的。我们完全可以举一反三地去类比。与(bitset)重定义了许多奇形怪状新的函数之外,其他都是大致相同的。所以笔者在此不再做幼稚的介绍,大家都是竞赛狗,应该都能自己看明白。
常规操作
如其他(C++STL)容器一样,(map)支持基本相同的基本操作:
比如清空操作,函数(clear()),返回容器大小(size()),返回首尾迭代器(begin(),end())等。
插入操作
(map)容器的插入操作大约有两种方法,第一种是类似于数组类型,可以把键值作为数组下标对(map)进行直接赋值:
mp[1]='a';
当然,也可以使用(insert())函数进行插入:
mp.insert(map<int,char>::value_type(5,'d'));
删除操作
可以直接用(erase())函数进行删除,如:
mp.erase('b');
遍历操作
和其他容器差不多,(map)也是使用迭代器实现遍历的。如果我们要在遍历的时候查询键值(即前面的那个),可以用it->first来查询,那么,当然也可以用it->second查询对应值(后面那个)
查找操作
查找操作类比(set)的查找操作。但是(map)中查找的都是键值。
比如:
mp.find(1);
即查找键值为(1)的元素。
map和pair的关系
我们发现,(map)和(C++)内置二元组(pair)特别相似。那是不是(map)就是(pair)呢?(当然不是)
那么(map)和(pair)又有什么关系呢?
@JZYShruraK大佬
首先,(map)构建的关系是映射,也就是说,如果我们想查询一个键值,那么只会返回唯一的一个对应值。但是如果使用(pair)的话,不仅不支持(O(log))级别的查找,也不支持知一求一,因为(pair)的第一维可以有很多一样的,也就是说,可能会造成一个键值对应(n)多个对应值的情况。这显然不符合映射的概念。