VQA简单综述
https://zhuanlan.zhihu.com/p/59530688
最近对VQA (Visual Question Answering,视觉问答) 问题产生了一定的兴趣,于是,参考吴琦等人的综述性论文Visual Question Answering: A Survey of Methods and Datasets对该领域进行了大致的了解,虽然是浅尝辄止,但也收获了不少,整理如下。
概述
VQA指的是,给定一张图片和一个与该图片相关的自然语言问题,计算机能产生一个正确的回答。 显然,这是一个典型的多模态问题,融合了CV与NLP的技术,计算机需要同时学会理解图像和文字。正因如此,直到相关技术取得突破式发展的2015年,VQA的概念才被正式提出。
可见,VQA仍然是一个非常新颖的研究方向,但它很容易让人联想到其他两个已经被研究较久的领域:文本QA和Image Captioning。
文本QA即纯文本的回答,计算机根据文本形式的材料回答问题。与之相比,VQA把材料换成了图片形式,从而引入了一系列新的问题:
- 图像是更高维度的数据,比纯文本具有更多的噪声。
- 文本是结构化的,也具备一定的语法规则,而图像则不然。
- 文本本身即是对真实世界的高度抽象,而图像的抽象程度较低,可以展现更丰富的信息,同时也更难被计算机“理解”。
与Image Captioning这种看图说话的任务相比,VQA的难度也显得更大。因为Image Captioning更像是把图像“翻译”成文本,只需把图像内容映射成文本再加以结构化整理即可,而VQA需要更好地理解图像内容并进行一定的推理,有时甚至还需要借助外部的知识库。 然而,VQA的评估方法更为简单,因为答案往往是客观并简短的,很容易与ground truth对比判断是否准确,不像Image Captioning需要对长句子做评估。
总之,VQA是一个非常具有挑战性的问题,正处于方兴未艾的阶段,有许多“坑”正等着未来的研究者去填。
常用方法
吴琦等人的综述发表于2016年,所以仅能对2015至2016年的相关工作进行总结。即便如此,我们还是能看到,短短两年的时间,VQA领域就涌现了不少的成果。 吴琦等人把这些方法分为四大类,分别是Joint embedding approaches、Attention mechanisms、Compositional Models和Models using external knowledge base 。
Joint embedding approaches
Joint embedding是处理多模态问题时的经典思路,在这里指对图像和问题进行联合编码。该方法的示意图为:
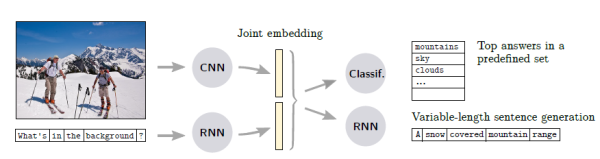
首先,图像和问题分别由CNN和RNN进行第一次编码得到各自的特征,随后共同输入到另一个编码器中得到joint embedding,最后通过解码器输出答案。 值得注意的是,有的工作把VQA视为序列生成问题,而有的则把VQA简化为一个答案范围可预知的分类问题。在前者的设定下,解码器是一个RNN,输出长度不等的序列;后者的解码器则是一个分类器,从预定义的词汇表中选择答案。
Attention mechanisms
attention机制起源于机器翻译问题,目的是让模型动态地调整对输入项各部分的关注度,从而提升模型的“专注力”。而自从Xu等人将attention机制成功运用到Image Captioning中,attention机制在视觉任务中受到越来越多的关注,应用到VQA中也是再自然不过。下面就是将attention机制应用到上个方法中的示意图。
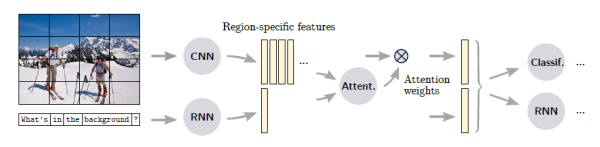
相关的工作表明,加入attention机制能获得明显的提升,从直观上也比较容易理解:在attention机制的作用下,模型在根据图像和问题进行推断时不得不强制判断“该往哪看”,比起原本盲目地全局搜索,模型能够更有效地捕捉关键图像部位。
Compositional Models
Compositional Models的核心思想是将设计一种模块化的模型。
这方面的一个典型代表是Andreas等人的Neural Module Networks。其最大的特点是根据问题的类型动态组装模块来产生答案。
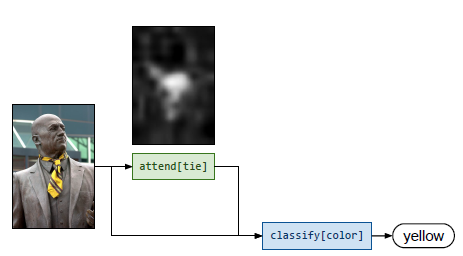
比如,在上面的例子中,当面对 What color is his tie? 这个问题时,模型首先利用parser对问题进行语法解析,接着判断出需要用到attend和classify这两个模块,然后判断出这两个模块的连接方式。最终,模型的推理过程是,先把注意力集中到tie上,然后对其color进行分类,得出答案。
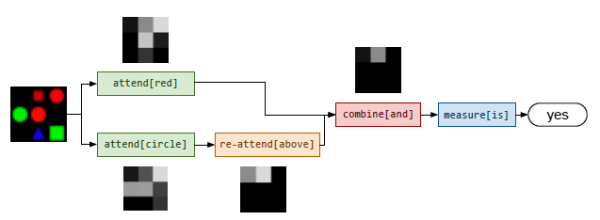
而在另一个例子中,当面对 Is there a red shape above a circle? 这种更为复杂的问题时,模型选择的模块也自动变得复杂了许多。
吴琦等人列举的另一个典型代表是Xiong等人的Dynamic Memory Networks。该网络由四个主要的模块构成,分别是表征图像的input module、表征问题的question module、作为内存的episodic memory module和产生答案的answer module。 模型运作过程如下图。
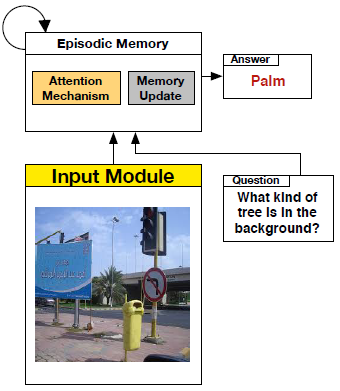
Models using external knowledge base
虽然VQA要解决的是看图回答问题的任务,但实际上,很多问题往往需要具备一定的先验知识才能回答。例如,为了回答“图上有多少只哺乳动物”这样的问题,模型必须得知道“哺乳动物”的定义,而不是单纯理解图像内容。因此,把知识库加入VQA模型中就成了一个很有前景的研究方向。 这方面做得比较好的工作是吴琦作为一作发表的另一篇论文Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources。 该工作的模型框架如下。
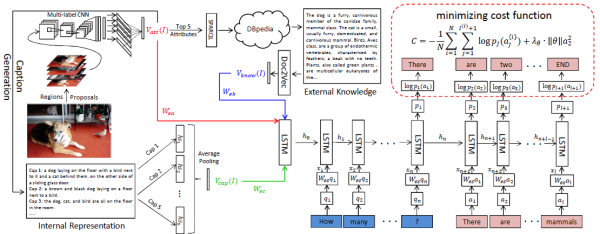
模型虽然看似复杂,但理解起来不外乎以下几个要点:
- 红色部分表示,对图像进行多标签分类,得到图像标签(attribute)。
- 蓝色部分表示,把上述图像标签中最明显的5个标签输入知识库DBpedia中检索出相关内容,然后利用Doc2Vec进行编码。
- 绿色部分表示,利用上述图像标签生成多个图像描述(caption),将这一组图像描述编码。
- 以上三项同时输入到一个Seq2Seq模型中作为其初始状态,然后该Seq2Seq模型将问题进行编码,解码出最终答案,并用MLE的方法进行训练。