Hadoop集群管理
Hadoop是大数据通用处理平台,提供了分布式文件存储以及分布式离线并行计算,由于Hadoop的高拓展性,在使用Hadoop时通常以集群的方式运行,集群中的节点可达上千个,能够处理PB级的数据。
Hadoop各个模块剖析:https://www.cnblogs.com/funyoung/p/9889719.html
1.搭建HDFS集群
一个HDFS集群由一个NameNode节点和多个DataNode节点组成。
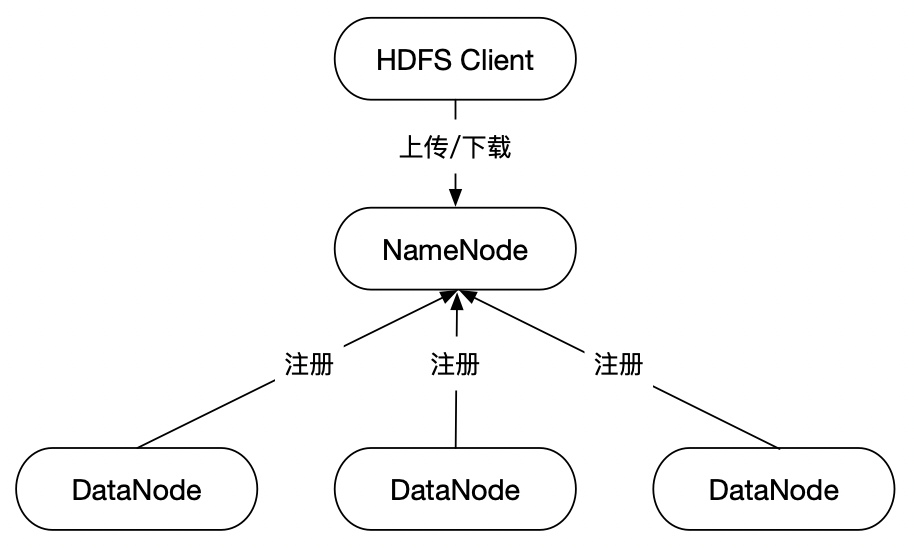
1.1 修改配置
1.配置SSH以及hosts文件
由于在启动HDFS时需要对用户的身份进行验证,且集群中的NameNode节点在启动时会通过SSH的方式通知其他节点,使其启动相应的进程,因此需要相互配置SSH设置免密码登录并且关闭防火墙。
//生成秘钥 ssh-keygen -t rsa //复制秘钥到本机和其他受信任的主机中,那么在本机可以直接通过SSH免密码登录到受信任的主机中. ssh-copy-id 192.168.1.80 ssh-copy-id 192.168.1.81 ssh-copy-id 192.168.1.82
编辑/etc/hosts文件,添加集群中主机名与IP的映射关系。

2.配置Hadoop公共属性(core-site.xml)
<configuration> <!-- Hadoop工作目录,用于存放Hadoop运行时产生的临时数据 --> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/hadoop-2.9.0/data</value> </property> <!-- NameNode的通信地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.1.80</value> </property> <!-- 开启Hadoop的回收站机制,当删除HDFS中的文件时,文件将会被移动到回收站(/usr/<username>/.Trash),在指定的时间过后再对其进行删除,此机制可以防止文件被误删除 --> <property> <name>fs.trash.interval</name> <!-- 单位是分钟 --> <value>1440</value> </property> </configuration>
3.配置HDFS(hdfs-site.xml)
<configuration> <!-- 文件在HDFS中的备份数(小于等于DataNode) --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 关闭HDFS的访问权限 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <!-- 设置NameNode的可视化管理界面的地址(主机地址需要与core-site.xml中fs.defaultFS配置的一致) --> <property> <name>dfs.namenode.http-address</name> <value>192.168.1.80:50070</value> </property> <!-- 设置SecondaryNameNode的HTTP访问地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.1.80:50090</value> </property> </configuration>
4.在NameNode节点中配置Slave文件
#配置要运行DataNode的节点,值可以是主机名或IP地址。
192.168.1.80
192.168.1.81
192.168.1.82
1.2 启动HDFS集群
1.分别格式化NameNode
bin/hdfs namenode -format
2.在任意一台Hadoop节点中启动HDFS,那么整个HDFS集群将会一起启动。

3.分别通过jps命令查看当前正在运行的JAVA进程。



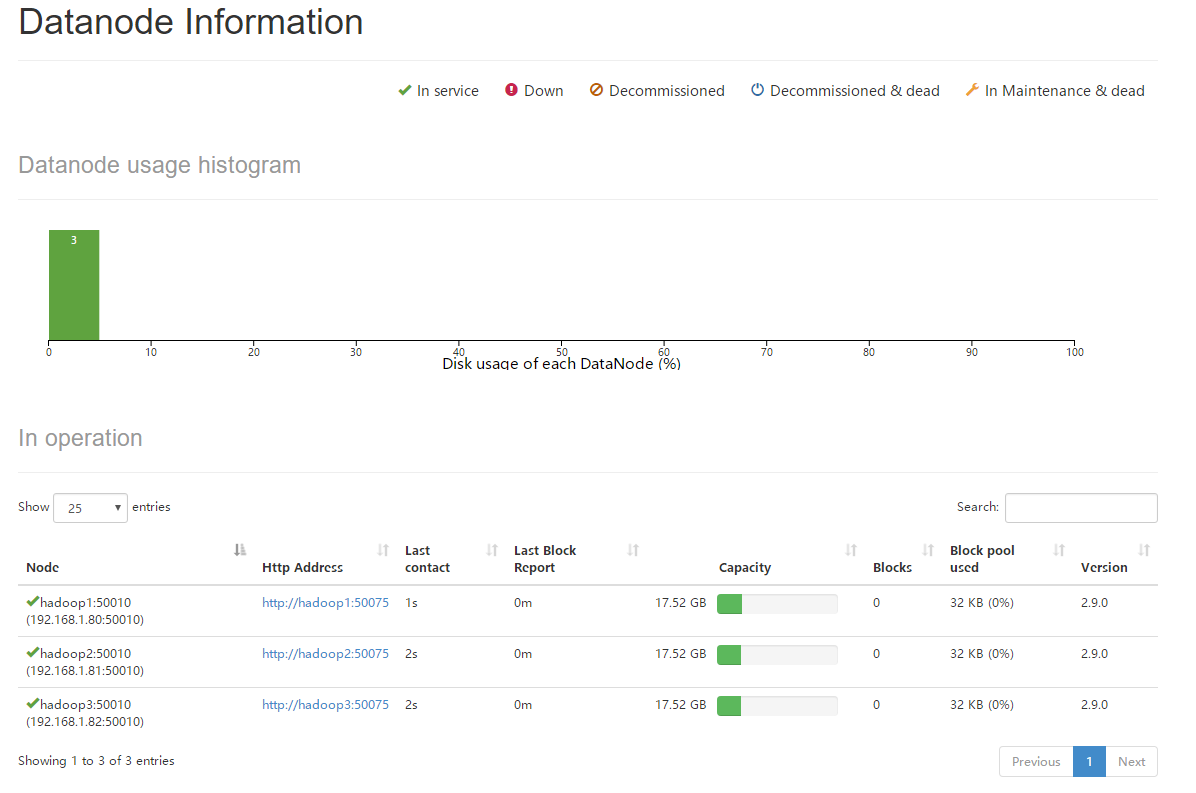
4.当HDFS集群启动完毕后,由于NameNode部署在hadoop1机器上,因此可以访问http://192.168.1.80:50070进入HDFS的可视化管理界面,可以查看到当前HDFS集群中有3个存活的DataNode节点。
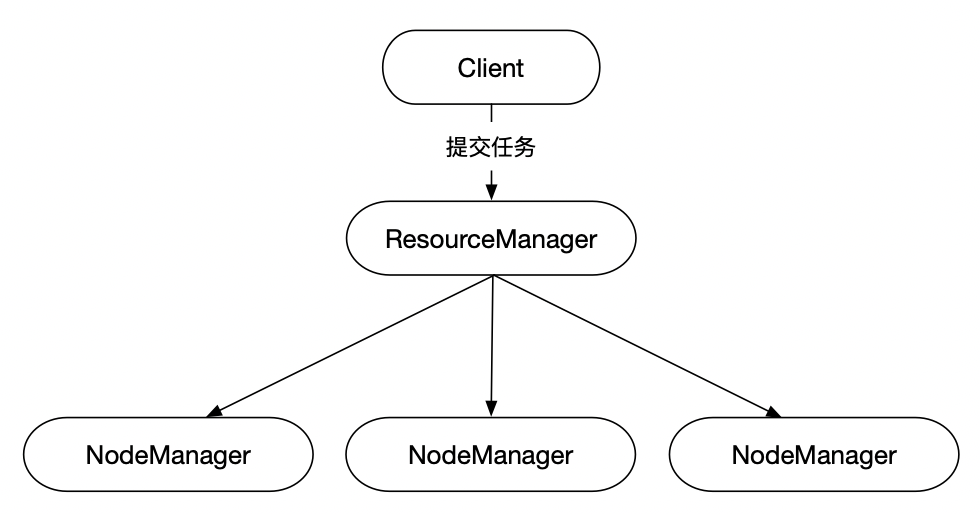
2.搭建YARN集群
一个Yarn集群由一个ResourceManager节点和多个NodeManager节点组成。
2.1 修改配置
1.配置SSH以及hosts文件
由于在启动YARN时需要对用户的身份进行验证,且集群中的ResourceManager节点在启动时会通过SSH的方式通知其他节点,使其启动相应的进程,因此需要相互配置SSH设置免密码登录并且关闭防火墙。
//生成秘钥
ssh-keygen -t rsa
//复制秘钥到本机和其他受信任的主机中,那么在本机可以直接通过SSH免密码登录到受信任的主机中.
ssh-copy-id 192.168.1.80
ssh-copy-id 192.168.1.81
ssh-copy-id 192.168.1.82
编辑/etc/hosts文件,添加集群中主机名与IP的映射关系。
2.配置YARN(yarn-site.xml)
<configuration> <!-- 配置Reduce取数据的方式是shuffle(随机) --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 设置ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.1.80</value> </property> <!-- Web Application Proxy安全任务 --> <property> <name>yarn.web-proxy.address</name> <value>192.168.1.80:8089</value> </property> <!-- 开启日志 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志的删除时间 -1:禁用,单位为秒 --> <property> <name>yarn.log-aggregation。retain-seconds</name> <value>864000</value> </property> <!-- 设置yarn的内存大小,单位是MB --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> <!-- 设置yarn的CPU核数 --> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>8</value> </property> </configuration>
3.配置MapReduce(mapred-site.xml)
<configuration> <!-- 让MapReduce任务使用YARN进行调度 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 设置JobHistory的服务地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.1.80:10020</value> </property> <!-- 指定JobHistory的Web访问地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.1.80:19888</value> </property> <!-- 开启Uber运行模式 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property> </configuration>
JobHistory记录了已经完成的MapReduce任务信息并存放在HDFS指定的目录下,默认未开启。
Uber运行模式对小作业进行优化,不会给每个任务分别申请Container资源,这些小任务将统一在一个Container中按照先执行map任务后执行reduce任务的顺序串行执行。
4.在ResourceManager节点中配置Slave文件
#配置要运行NodeManager的节点,值可以是主机名或IP地址。
192.168.1.80
192.168.1.81
192.168.1.82
2.2启动YARN集群
1.在ResourceManager节点中启动YARN集群。

2.分别通过jps命令查看正在运行的JAVA进程。



3.当YARN集群启动后,由于ResourceManager部署在hadoop1机器上,因此可以访问http://192.168.1.80:8088进入YARN的可视化管理界面,可以查看到当前YARN集群中有3个存活的NodeManager节点。

4.在JosHistory节点中启动JobHistory。

当启动JobHistory后,可以访问mapreduce.jobhistory.address配置项指定的地址进入JobHistory可视化管理界面,默认是http://192.168.1.80:19888。
3.1 动态新增DataNode和NodeManager节点
1.准备一台新的机器(节点)
2.修改各个节点的hosts文件,添加新节点的主机名与IP的映射关系。

3.相互配置SSH,使可以通过SSH进行免密码登录。
4.修改NameNode和ResourceManager节点的Slave文件,添加新节点的主机名或IP地址。

5.单独在新节点中启动DataNode和NodeManager。

6.进入HDFS的可视化管理界面,可以查看到当前HDFS集群中有4个存活的DataNode节点。
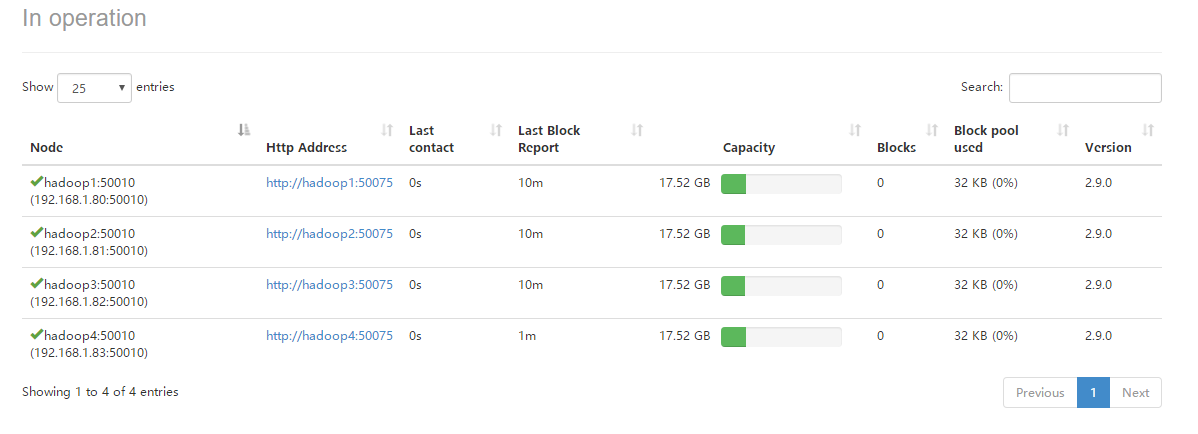
7.进入YARN的可视化管理界面,可以查看到当前YARN集群中有4个存活的NodeManager节点。
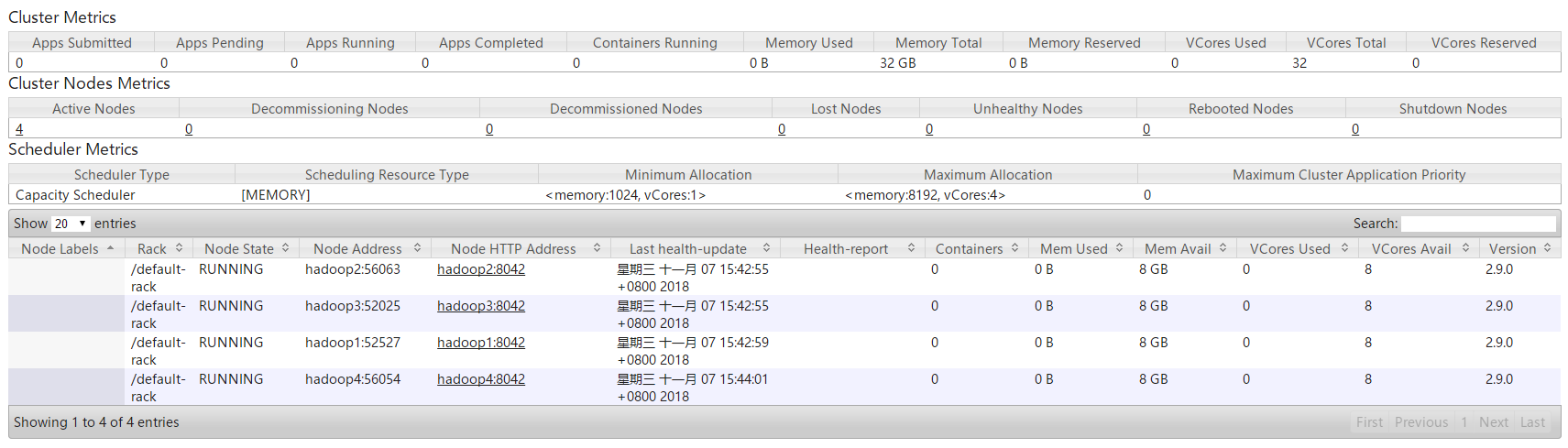
3.2 动态卸载DataNode和NodeMananger节点
1.修改NameNode节点上的hdfs-site.xml配置文件,添加过滤配置。
<!-- 指定一个配置文件,使NameNode过滤配置文件中指定的host --> <property> <name>dfs.hosts.exclude</name> <value>/usr/hadoop/hadoop-2.9.0/etc/hadoop/hdfs.exclude</value> </property>
2.修改ResourceManager节点上的yarn-site.xml配置文件,添加过滤配置。
<!-- 指定一个配置文件,使ResourceManager过滤配置文件中指定的host --> <property> <name>yarn.resourcemanager.nodes.exclude-path</name> <value>/usr/hadoop/hadoop-2.9.0/etc/hadoop/yarn.exclude</value> </property>
3.分别刷新HDFS和YARN集群

第一次使用该配置时需要重启HDFS和YARN集群,使其重新读取配置文件,往后一旦修改过exclude.host配置文件则直接刷新集群即可。
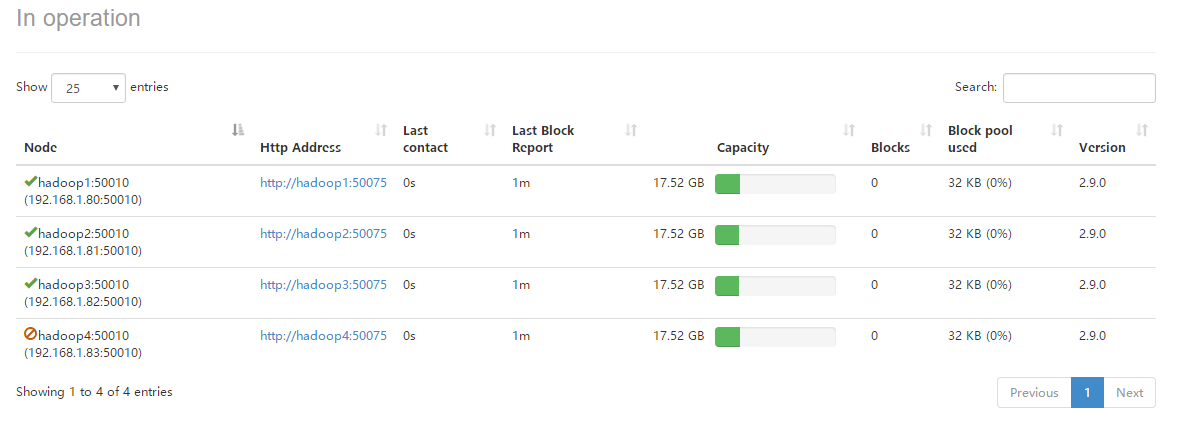
4.进入HDFS的可视化管理界面,可以查看到hadoop4的DataNode节点已经被动态的移除。
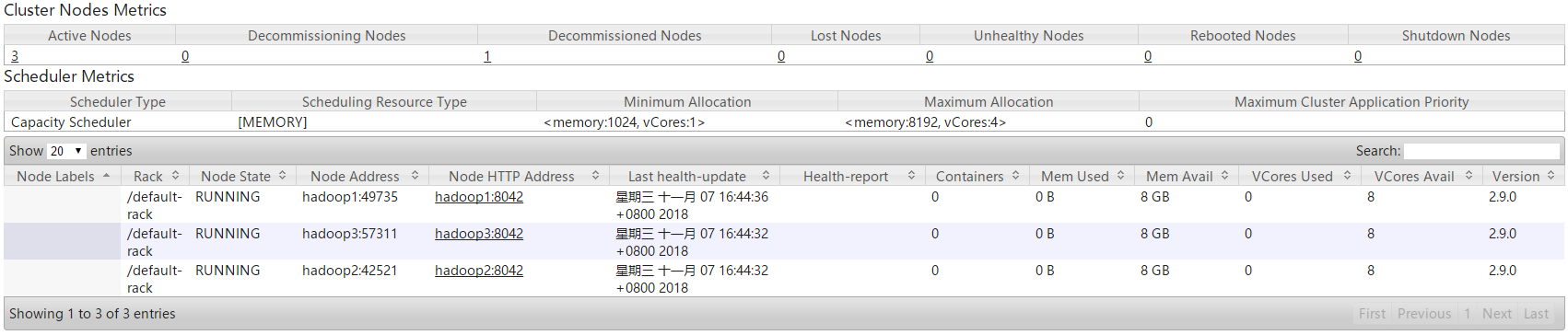
5.进入Yarn的可视化管理界面,可以看到hadoop4的NodeManager节点已被移除。
6.使用jps命令查看hadoop4正在运行的JAVA进程,可以发现该节点上的NodeManager进程已经被kill掉,而DataNode进程仍然在运行,因此YARN集群在通过exclude.hosts文件过滤节点时,会把节点上的NodeManager进程杀死,因此不能够动态的进行恢复,而HDFS集群在通过exclude.hosts文件过滤节点时,并不会把节点上的DataNode进程给杀死,因此可以动态的进行恢复。
