关于图文识别功能相关技术的实现
转载请注明源地址:http://www.cnblogs.com/funnyzpc/p/8908906.html
上一章,写的是SSL证书配置,中间折腾了好一会,在此感谢SSL证书发行商的协助;这次我就讲讲ocr识别的问题,先说说需求来源吧。。。
之前因为风控每次需要手动P协议文件和身份证(脱敏),还要识别证件及图片文件的内容,觉得狠狠狠麻烦,遂就找到了技术总监,技术总监一拍脑袋,额,小邹啊。。。
呃,一开始并没抱太大希望,不过还是花了些心思做了些需求实现的调研,怎么办 google、duckduckgo、github一路找下来就有了几个工程了,嘿嘿~,可惜还没高兴到,没想到的是这些工程一个比一个坑,不是依赖windows系统组件就是代码bug不断,作者们,能用点儿心么![]()
日夜操劳,加班啊,总算是将几个工程全都修得能跑起来了,大费周折。。。难得啊![]()
欸,可惜效果均不佳;现开始,我总结下一些主流的图文识别技术,只是浅聊哦。。。
首先,这些工程大致分两类:
一类是纯算法,不附带机器学习功能的,且需要依赖于window系统组件的工程,比如tesseract和tess4j,识别效果可以说是巨差(可能我的技术很菜的原因 ),但有一点儿值得赞许,就是识别结果的格式还算不错,这类图文识别的特点大致有如下几点:
),但有一点儿值得赞许,就是识别结果的格式还算不错,这类图文识别的特点大致有如下几点:
A>工程代码量较大
B>依赖window组件,需要在window系统下才能运行
C>识别效果无法通过学习逐渐优化
D>识别出来的文字时常乱码,中文识别乱码错别字较多
E>识别结果通常使用格式化模子来格式化结果,遂,识别结果的格式还算过得去
一类是基于机器学习(比如Tensorflow)的工程,这些工程参差不齐,存在插件版本问题,尤其是python插件,实在在太太太难装了,在一就是工程大多较为简陋,由于机器学习具有不断改善的趋势,这是基于机器学习的图文识别的最大优势,总结起来,基于机器学习的图文识别的特点儿大致有如下几点:
A>工程比较简单,代码量不是很多
B>依赖的语言插件,如python实在难以安装
C>有很多优化的方向,比如使用显卡,优化算法(卷积神经网络)来提高识别速度及模型准确度
D>十分耗费计算机字段,一般识别一页A4大小的图片中的内容,(我使用Macbook Pro) 最快也用了二十多秒
E>识别的结果比较乱,但对于中文,尤其是图片较好的中文的文字识别准确率能达到百分之七十网上,但是识别格式和文字准确度不如上者
F>由于是基于机器学习,遂需要大量的数据喂养以提高识别的准确率,喂养的数据十分可观
额,总的来说,后者的优势较大,也是趋势,比如腾讯QQ的图片识别还有百度大脑AI这些基本都是基于机器学习,个人觉得,如果投入一个团队去专门研究开发一个图文识别的产品,也是比较容易实现的,何况这个方向向前走就是人工智能,尽管现在看起来有些智障...。
哦,大致总结完了,我就展示下基于tess4j和chinese-ocr这两项目的实现效果,我的输入是身份证:

(注意:源图片是从github上拉下来的,个人做了些简陋的脱敏处理!)
下面是基于tess4j实现的结果:
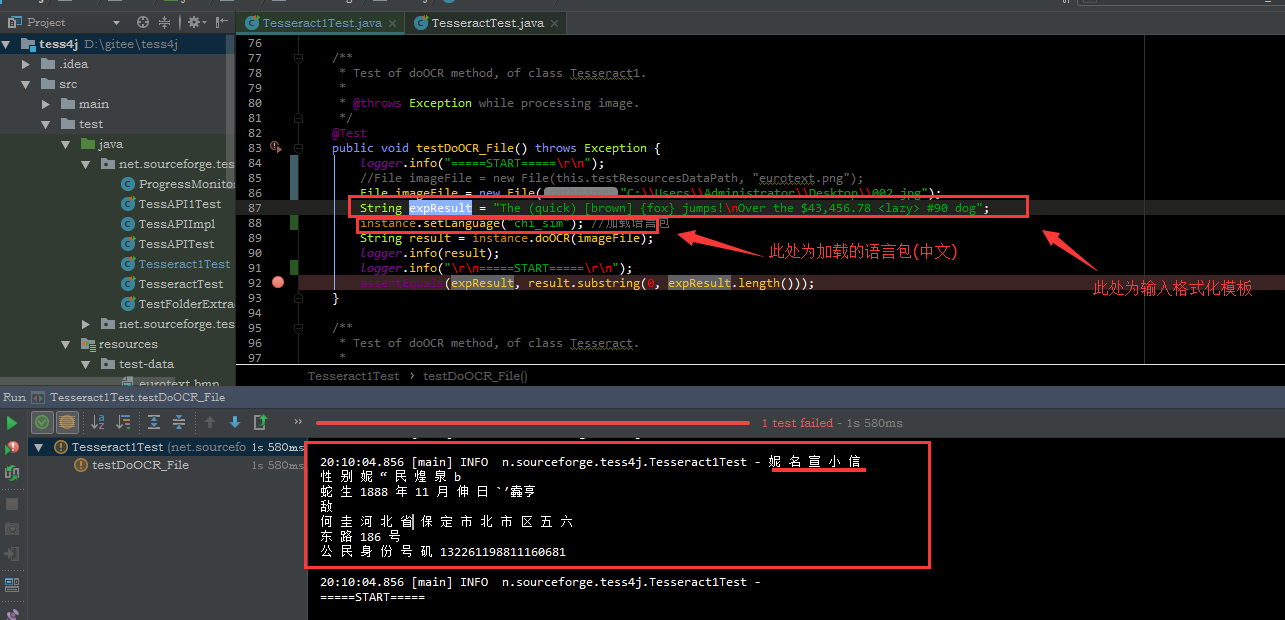
tess4j的实现只能基于windows组件实现,故项目只能在windows下运行,另外tesseract也是windows组件的实现。
一下是基于chinese-ocr的项目的实现的结果: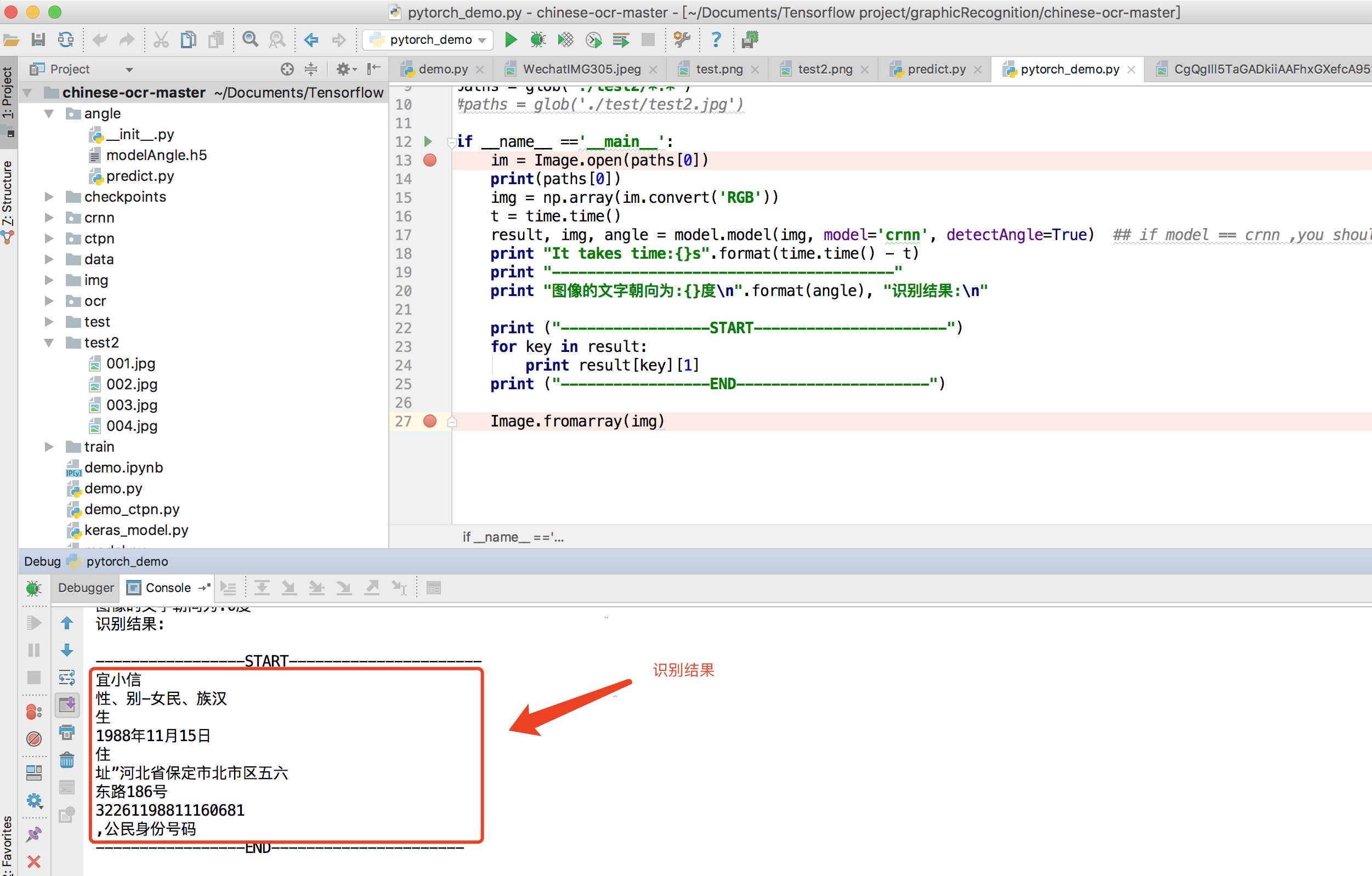
chinese-orc是基于python语言+tensorflow的实现,结果一目了然,需要说的是,一下几个也是基于=>
text-detection-ctpn :基于Tensorflow实现的图片识别,未调试通过
tensorflow-ocr :基于tensorflow实现的图片识别,未调试通过
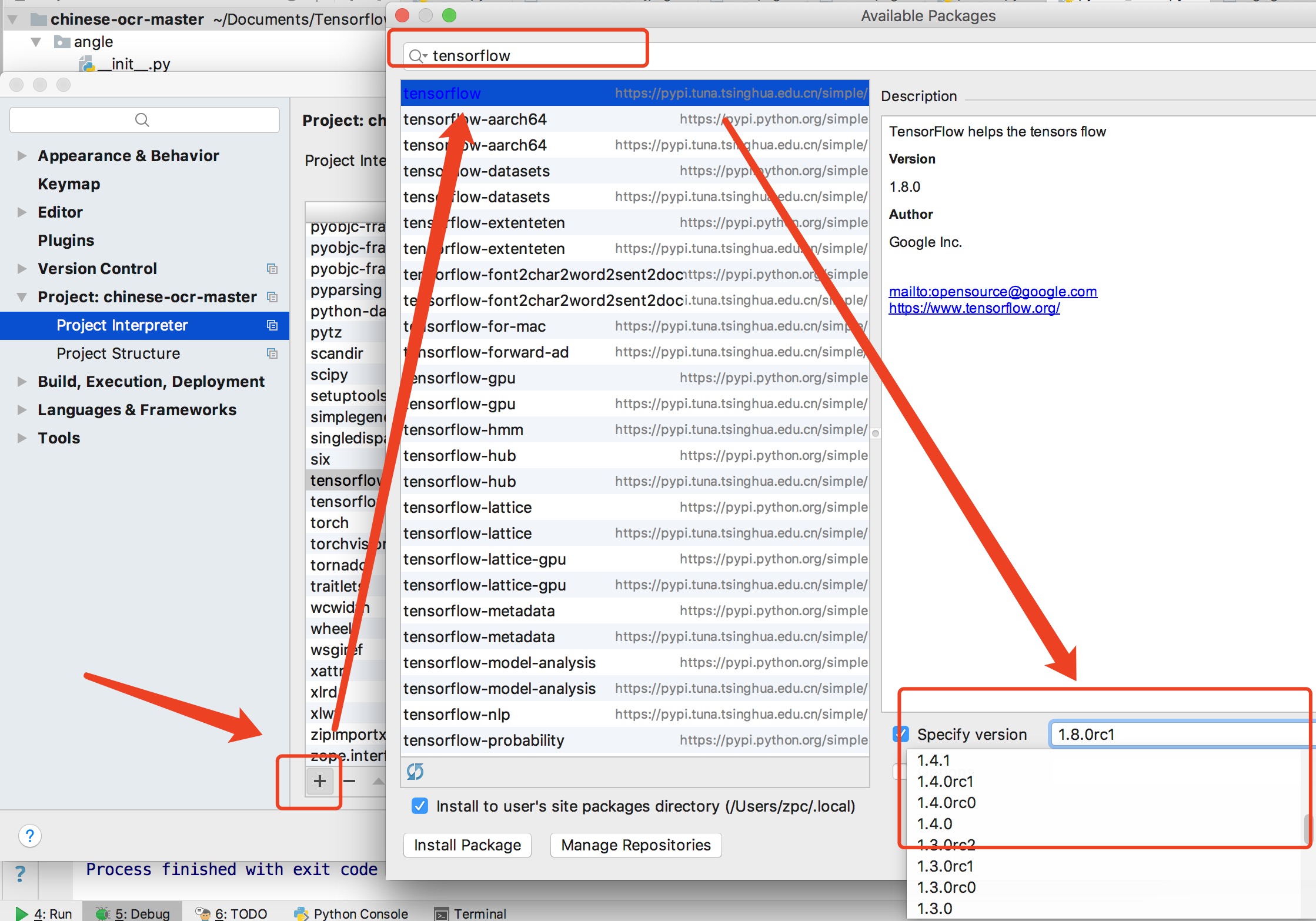
B>对于部分(例如 test.py)文件跑不起来的,请尝试着将这个文件放置在工程主目录下,但同时请注意 import引用的文件(可能需要手动修改)
 。
。