Dataworks批量刷数优化方案探讨
在数据仓库的日常使用中,经常会有批量补数据,或者逻辑调整后批量重跑数据的场景。
批量刷数的实现方式,因调度工具差异而各有不同。
Dataworks调度批量刷数局限
我们的数据仓库构建在阿里云的dataworks+maxcompute产品上,dataworks的调度工具提供了补数据的功能,可以很方便的补整个任务流的数据,但是该功能有个局限,就是只能指定一个参数,即业务日期,如下图。
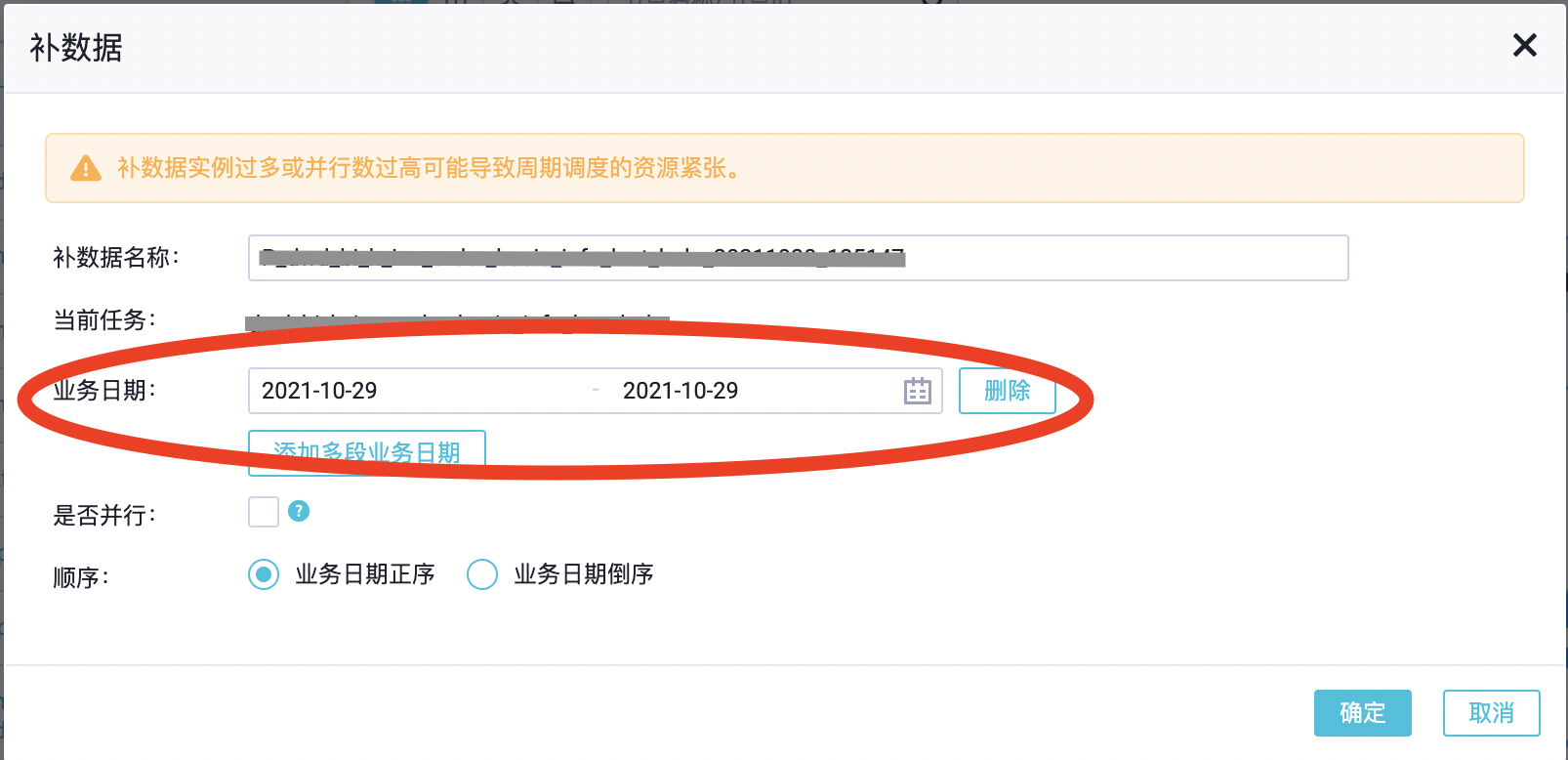
如果要刷一个月的数据,比如2021年10月份,要怎么操作呢?业务日期选定时间范围2021-10-01 ~ 2021-10-31。然后dataworks会根据选定的时间范围,每天生成一个实例去执行任务补数据,也就是补数据的任务要跑31次,每次补一天的数据。
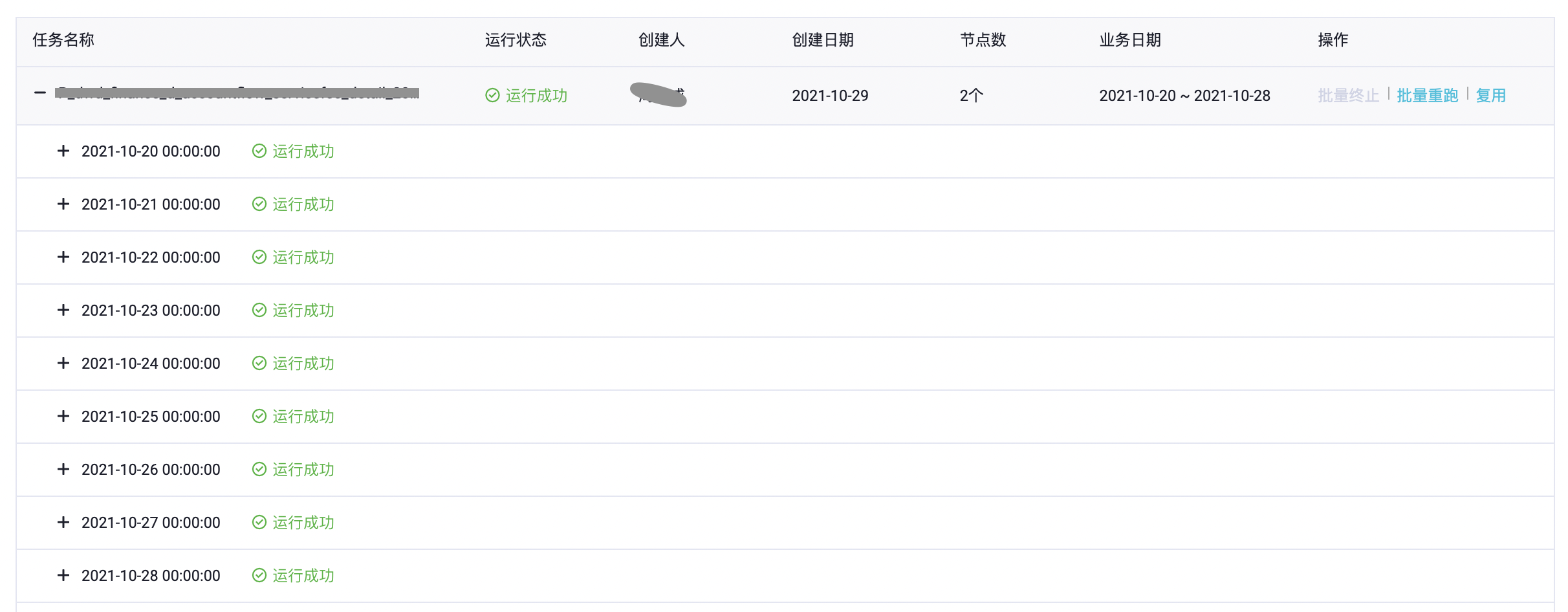
这样就会导致整个补数的过程非常缓慢,且耗资源。
- 因为maxcompute是基于hive的,一个任务的启动初始化-〉申请资源-〉等待资源分配的过程是很重、很缓慢的,31个天任务的这个过程中耗时会是单个任务的31倍(未并行的情况下)。初步统计了一下,单个maxcompute任务的启动耗时大概是8s,31个任务启动就比单个任务多出了4分钟,如果整个流程涉及10个任务,整个刷数的耗时单在这个阶段就要多出40分钟。
- 作为大数据的计算引擎,在一定的数据量级内,数据处理的耗时差别并不大。也就是说一次处理一天的数据,相较于一次处理一个月的数据,正常而言区别不会很大,绝对低于处理30次一天数据的耗时。
所以想要有效率的补数,不能依靠这种方式。
优化方案1
提升批量刷数效率的第一步,就是改造任务,按时间范围跑数,比如一次跑一个月的数据。但是这与日常调度的任务又有冲突,所以需要新建一份做为手动任务发布执行。
同时dataworks的手动任务的执行,也只能指定一个业务日期参数,且没法选定业务日期范围,即批量生成实例。
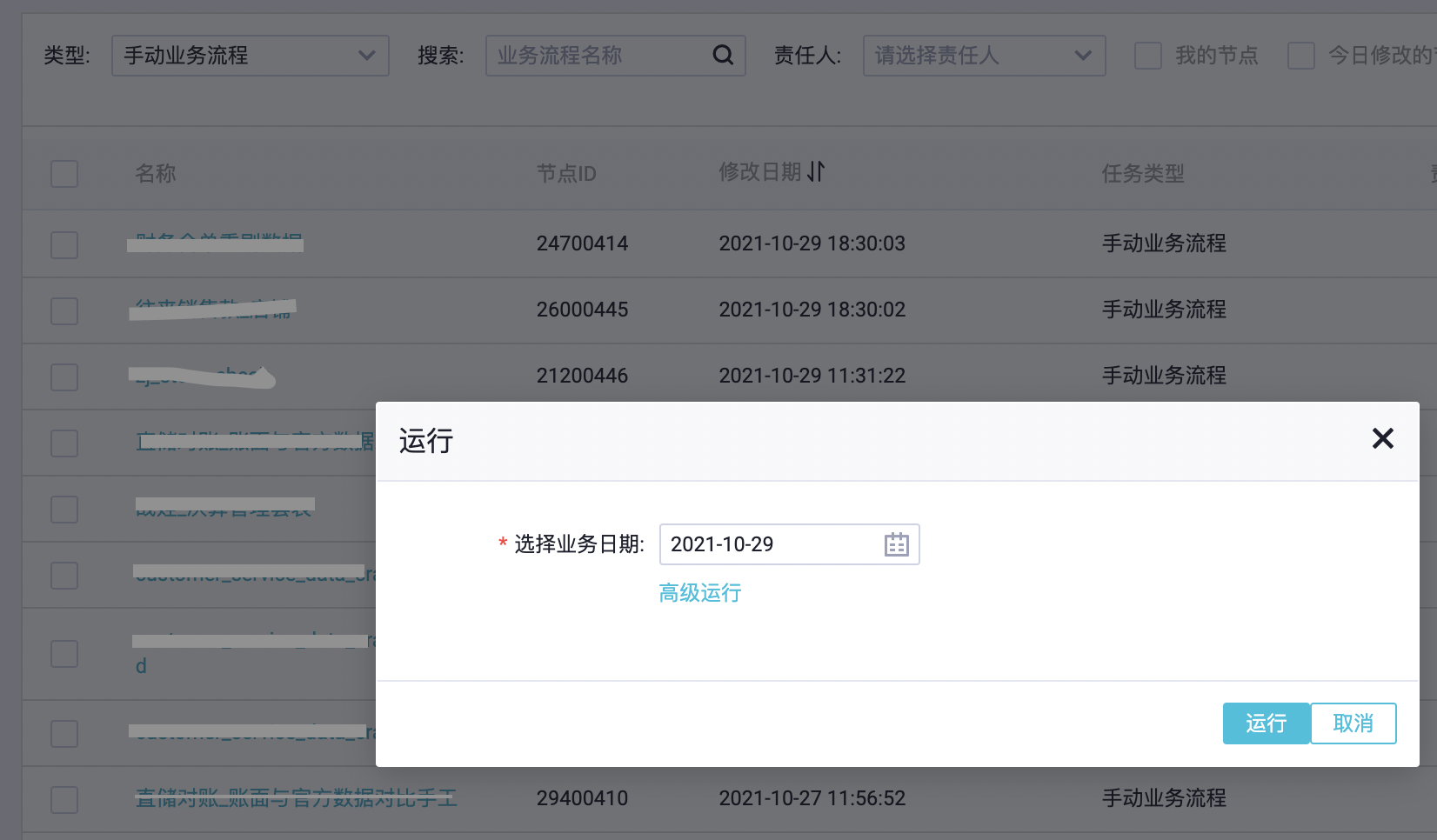
介于这个限制,所以手动任务的跑数时间周期只能是固定的,比如月、周、年。
按照这种方式刷数的效率,也已经远远高于前面的多实例按天补数据的方式。
实际案例,一个涉及近30个任务的流程,通过补数据的多实例按天刷一个月的数,耗时需6.5~8小时。通过手动任务按月刷数耗时只需1.5~2小时,效率提升近75%。
这种方式的缺点是:
- 同一脚本要维护两套,一套周期任务,一套手动任务。增加维护成本。
- 脚本跑数时间周期固定,如果需要调整周期需改脚本,并单独发布。比如按月刷数的脚本,想要按年刷,需要改脚本重新发布。
优化方案2
仔细分析,造成批量刷数麻烦、效率低下的根本原因,其实是dataworks的调度工具(不管是补数据,还是手工任务执行)只能指定一个参数。
有其他调度工具使用经验的朋友都会知道,在用调度工具手动执行任务时,一般是可以指定任务的入参的。而一般的ETL脚本都会设置两个入参: 开始时间、结束时间,来支持按时间范围跑数。
而阿里云dataworks调度工具支持自定义传参的唯一方式是赋值节点。通过赋值节点的输出参数,将参数传递给下游任务,下游任务可通过设置依赖赋值节点,获取赋值节点的输出参数,作为本节点任务的入参。
具体配置方法,可参考dataworks的说明文档:https://help.aliyun.com/document_detail/137534.html
所以具体的优化思路是,通过控制赋值节点的输出值,来指定下游任务的跑数时间范围,以实现批量刷数的目的。
赋值节点配置
因赋值节点的输出值需要可人为调整,所以设计创建一参数表,赋值节点从表里获取数据,作为输出值。可通过update参数表的值,来调整赋值节点输出值。
因为要update表,所以需创建一个支持事务(update)的表,同时需要包含下游节点需要的两个参数:开始时间、结束时间。
如:
CREATE TABLE IF NOT EXISTS schedule_args(
start_date BIGINT COMMENT '开始日期,格式:yyyymmdd'
,end_date BIGINT COMMENT '结束日期,格式:yyyymmdd'
) STORED AS ALIORC
TBLPROPERTIES ('comment'='调度任务入参表', 'transactional'='true')
;
又,因为只有周期任务支持赋值节点,且下游任务都得从该节点获取跑数时间范围。所以这里会有个风险点: 对赋值节点参数的调整可能影响到下游任务的日常调度。
解决方法是:通过增加判断逻辑,把日常调度与补数据两种场景的参数生成区别开。
具体实现是:通过获取dataworks内置业务日期参数$bizdate,并对业务日期值的判断,来区分周期调度和补数据两种场景。 正常周期调度的业务日期都是前一天,而补数据指定的业务日期不是。
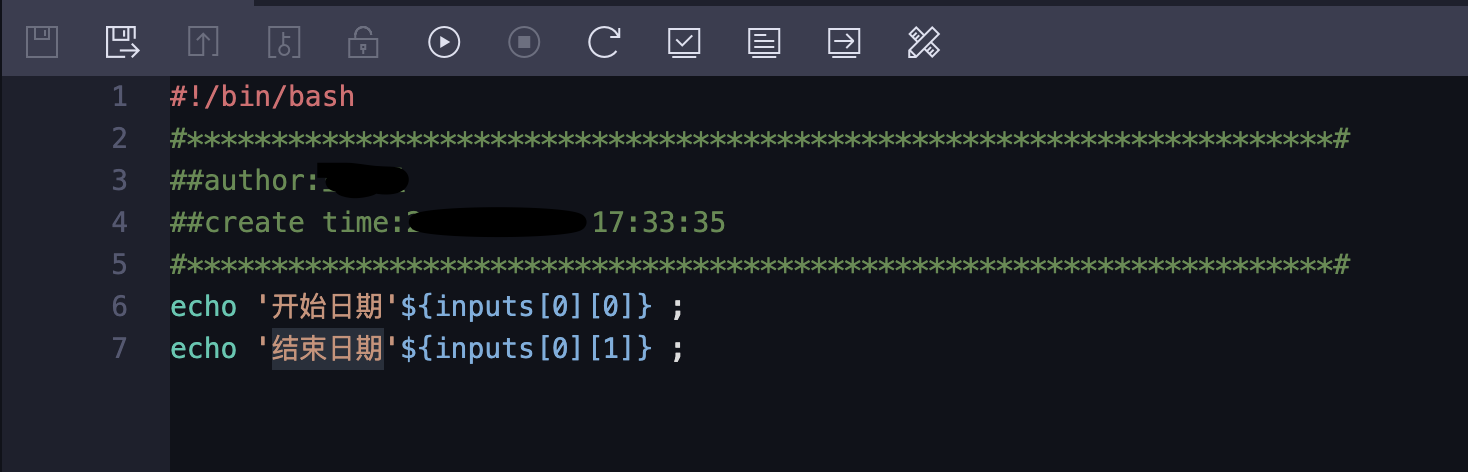
所以赋值节点的脚本如下:
select case when '${bizdate}' <> to_char(dateadd(getdate(),-1,'dd'),'yyyymmdd') then start_date else '${bizdate}' end as start_date
,case when '${bizdate}' <> to_char(dateadd(getdate(),-1,'dd'),'yyyymmdd') then end_date else '${bizdate}' end as end_date
from schedule_args ;
注: 更完备的规避风险的方法是,通过python脚本从表获取参数,并增加对空表和表不存在两种异常场景的处理。
这样正常日调度,赋值节点生成的输出参数值都是前一天,与不使用赋值节点获取的dataworks业务日期参数一致。
简单测试
配置下游节点,测试赋值节点的参数生成和下游节点的参数获取,以及日常调度和补数据场景的切换。
下游测试节点配置:
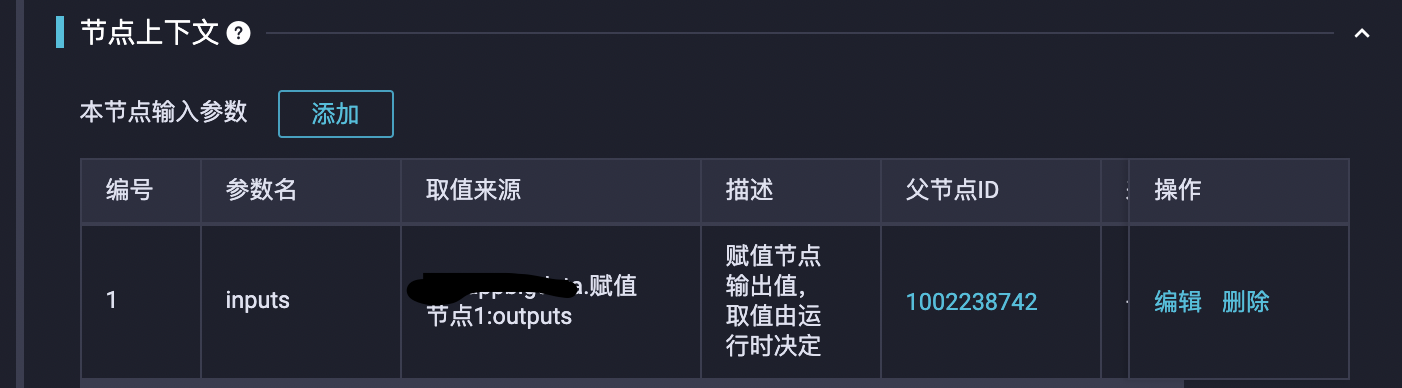
节点流程如下:
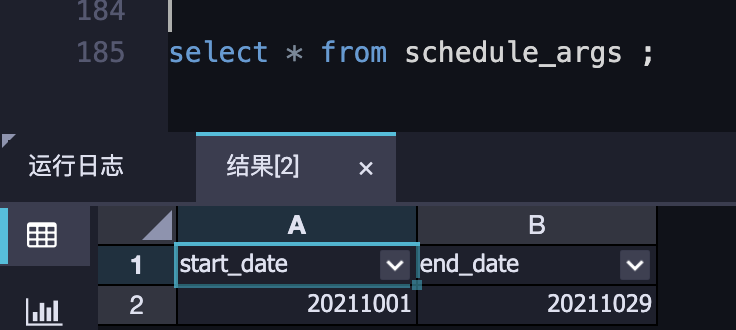
参数表配置:
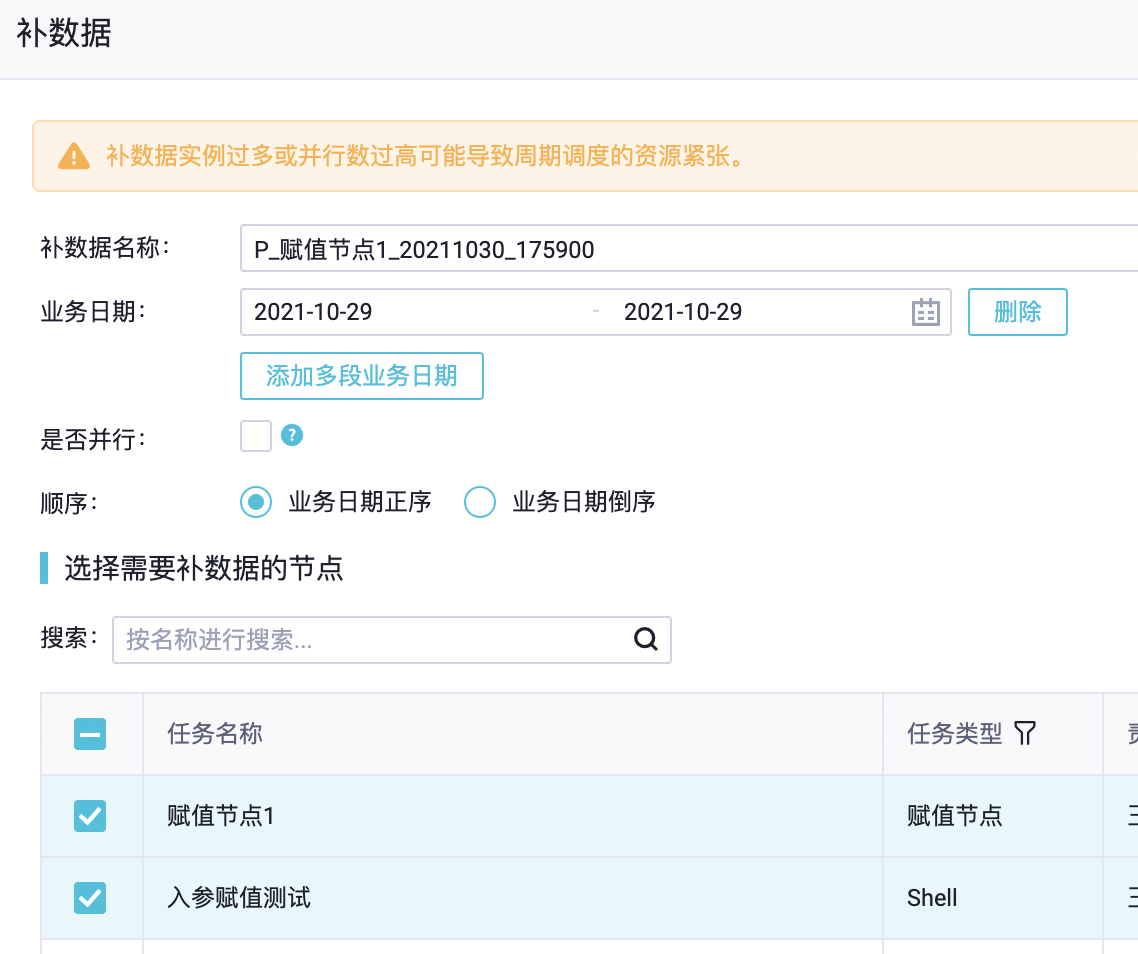
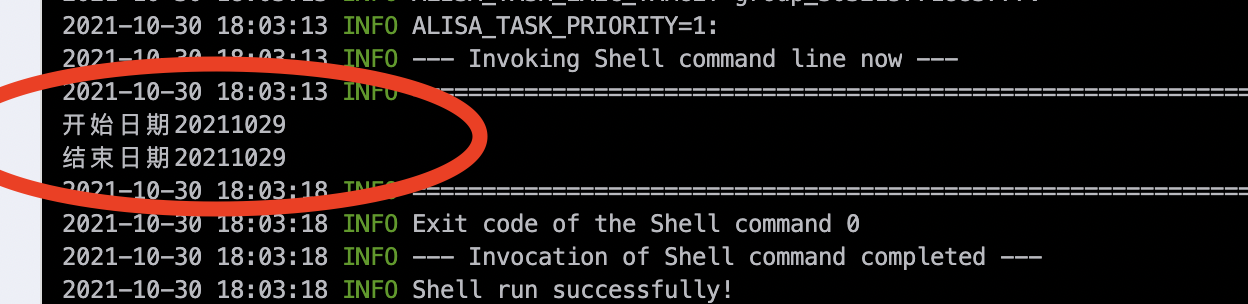
业务日期选择前一天,模拟日常调度场景:
下游节点获取入参为正常日调度的业务日期:
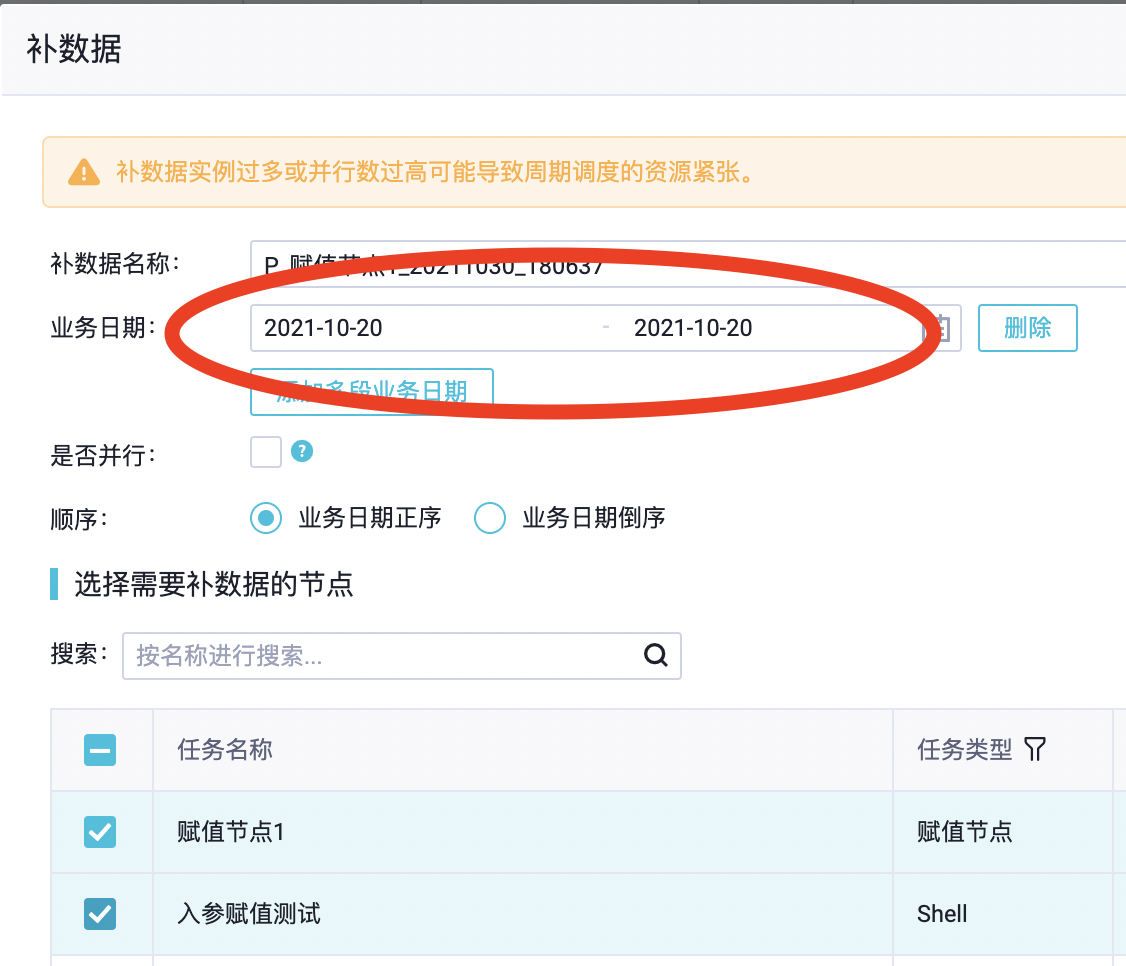
补数据场景:
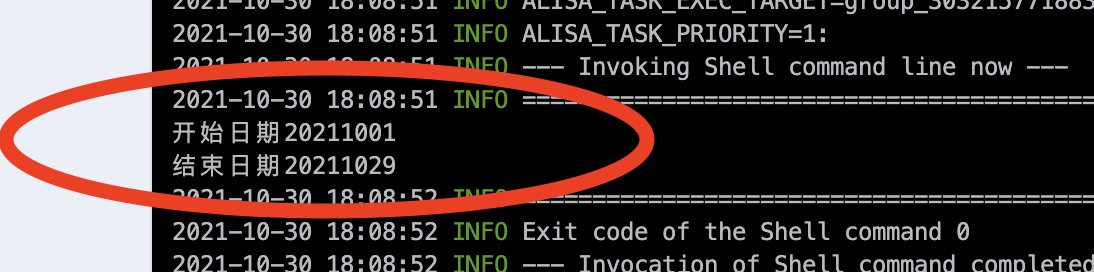
下游节点获取入参为参数表配置的日期:
小结
对于刷数时间周期固定,业务逻辑稳定变更少的任务流程,方案1比较适合。
方案2解决了方案1同一任务需要同时维护多套的问题,同时能够动态调整跑数的时间周期,支持批量刷数的场景更多,也更方便。唯一存在的问题是,在多人同时通过调整参数表进行批量刷数的时候,会有冲突。
比如:开发者A,update了参数表的值为20211001、20211029。在他执行补数据实例之前,开发者B也要刷数据,将参数表的值改为了20201001、20201030。开发者A再去执行补数据时,获取的参数时开发者B修改后的参数值20201001、20201030。
因为maxcompute还没有锁表机制,所以这个问题目前还没有很好的解决方案,只能通过收拢表修改权限等方式,来人为规避这个问题。