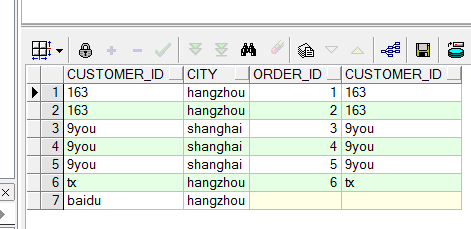
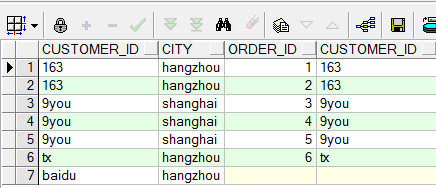
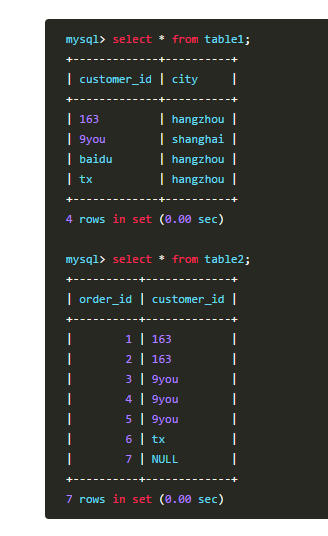
select customer_id ,count(table2.customer_id) 人数
from table2 where customer_id in (select customer_id from table1 where city='hangzhou') //错在这一句
group by customer_id having count(customer_id)<2;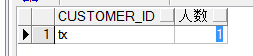 错了,因为还有一名用户是'baidu',却没有显示出来.
错了,因为还有一名用户是'baidu',却没有显示出来. select a.customer_id, count(b.order_id) 人数
from table1 a
left join table2 b
on a.customer_id=b.customer_id
where a.city='hangzhou'
group by a.customer_id
having count(b.order_id)<2;having count(b.order_id)<2;(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list> //如果select语句后面的列没有结合聚合函数,那么只能是group by 后面的这些列.因为如果不是这样的话,oracle没有办法决定是哪一行的数据 因为是先执行group by语句,所以只要你能保证select后面的列让Oracle知道怎么取就行了,记住Oracle是没办法从一组里面随机选择一个,必须是确定下来的
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
Student(S#,Sname,Sage,Ssex) 学生表 |
S#:学号;Sname:学生姓名;Sage:学生年龄;Ssex:学生性别
|
Course(C#,Cname,T#) 课程表
|
C#:课程编号;Cname:课程名字;T#:教师编号
|
SC(S#,C#,score) 成绩表
|
S#:学号;C#,课程编号;score:成绩
|
Teacher(T#,Tname) 教师表
| T#:教师编号; Tname:教师名字
|
1、查询同时选了"001课程"和"002课程“中001”课程比“002”课程成绩高的所有学生的学号;
select a.S# from (select S#,Score from SC where C#='001') a,(select S#,score from SC where C#='002') b
where a.score>b.score and a.S#=b.S#;select S# ,avg(score) '平均分数' from SC group by S# having avg(score)>60;Student(S#,Sname,Sage,Ssex) 学生表
Course(C#,Cname,T#) 课程表
SC(S#,C#,score) 成绩表
Teacher(T#,Tname) 教师表
select Student.S#,Sname,count(C#),sum(score) from Student left (outer) join SC on Student.S#=SC.S#
group by Student.S#,Sname.//不知道这里要不要填,多个group by是什么鬼
如果没有 那些聚合函数 group by 后面出现什么,就必须在select后面一起出现
可能有一些同学没有选课select SC.S# ,Sname ,count(S#),sum(score) from SC,Student where
Student.S#=SC.S# group by SC.S# Student(S#,Sname,Sage,Ssex) 学生表
Course(C#,Cname,T#) 课程表
SC(S#,C#,score) 成绩表
Teacher(T#,Tname) 教师表
4、查询姓“李”的老师的个数
其实这里根本就不需要考虑重名的情况,因为既然有这个老师,那么它的T#就是唯一的,所以.....
Select count(*) from teacher where Tname like '李%';
Course(C#,Cname,T#) 课程表
SC(S#,C#,score) 成绩表
Teacher(T#,Tname) 教师表
5 查询没学过“叶平”老师课的同学的学号、姓名 注:学号肯定是唯一的.
参考答案:
select Student.S#,Student.Sname
from Student
where S# not in (select distinct( SC.S#) from SC,Course,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平'); //这里得到的是'叶平'老师有上过的课,然后得到上过
叶平老师的课的学生的学号()Student(S#,Sname,Sage,Ssex) 学生表
Course(C#,Cname,T#) 课程表
SC(S#,C#,score) 成绩表
Teacher(T#,Tname) 教师表
6查询学过“001”并且也学过编号“002”课程的同学的学号、姓名;
select a.S#,a.Sname from (select S# from SC where C#='001' )a ,
(select S# from SC where C#='002') b
where
a.S#=b.S# select Student.S#,Student.Sname from Student,SC
where Student.S#=SC.S# and SC.C#='001'and
exists( Select * from SC as SC_2 where SC_2.S#=SC.S# and SC_2.C#='002');
这个答案好奇怪,感觉怪怪的.Student(S#,Sname,Sage,Ssex) 学生表
Course(C#,Cname,T#) 课程表
SC(S#,C#,score) 成绩表
Teacher(T#,Tname) 教师表
| 购物人 商品名称 数量 A 甲 2 B 乙 4 C 丙 1 A 丁 2 B 丙 5 |
select 购物人 from 购物信息 group by 购物人 having count(商品名称)>=2
select 购物人 from 购物信息 group by 购物人 having count(*)>=2
这两种有区别吗?应该没有区别.其实个人认识最好的做法是用cuont(*),因为count()函数感觉只是一个用来计算行数的.而不是具体某一个列.| 姓名 课程 分数 张三 语文 81 张三 数学 75 李四 语文 56 李四 数学 90 王五 语文 81 王五 数学 100 王五 英语 49 |
select * from score where name in (select name from score group by name having min(分数)>59);
//这种写法是错误的,因为有可能有学生的的姓名是一样的.如果一个张三及格,一个张三不及格.那么会把不及格的一起查询出来
正确写法:
答:select * from 成绩表 where 姓名 not in (select distinct 姓名 from 成绩表 where 分数 < 60)
或者:
select * from 成绩表 where 姓名 in (select 姓名 from 成绩表 group by 姓名 having min(分数) >=60) 正确答案也是错的.
正确答案也没有考虑到学生姓名重复的情况.又或者说如果这张表内有多个张三,那么这张表已经没有意义了.因为你不知道语文数学,分别是哪个张三的,所以可以假设,不会有重复
名称 产地 进价 苹果 烟台 2.5 苹果 云南 1.9 苹果 四川 3 西瓜 江西 1.5 西瓜 北京 2.4 |
select 名称 from 商品表 group by 名称 having avg(进行)<2;DELETE you can use the where condition i.e. to delete only certain records.The DELETE command is used to remove rows from a table. A WHERE clause can be used to only remove some rows.
If no WHERE condition is specified, all rows will be removed.
After performing a DELETE operation you need to COMMIT or ROLLBACK the transaction to make the change permanent or to undo it.
通过使用 commit 或者 rollback 来使这个改变变成永久的,或者撤销这个改变
Note that this operation will cause all DELETE triggers on the table to fire.
to fire 这里面的to fire 就是执行的意思吧 ,擦火的意思TRUNCATE
TRUNCATE removes all rows from a table. The operation cannot be rolled back and no triggers will be fired. As such, TRUCATE is faster and doesn't use as much undo space as a DELETE.(不需要像delete一样需要一个undo撤销的空间)
这个操作不能回滚,而且不会触发触发器,这个速度非常快,而不需要像delete这样额外的空间来执行undo操作.会全部删除数据,但是表的结构是会保存下来的.
DROP
The DROP command removes a table from the database. All the tables' rows, indexes and privileges will also be removed. No DML triggers will be fired. (todo 没有DML触发器回去触发还是解雇)The operation cannot be rolled back.
这个是直接把整个表都删了,索引,权限什么都没有了.而且DML(select insert delete update)这些触发器不会被触发.
所以只有delete执行的时候会触发触发器,其他两个是不会触发触发器的.
PS: DROP and TRUNCATE are DDL commands, whereas DELETE is a DML command. As such, DELETE operations can be rolled back (undone), while DROP and TRUNCATE operations cannot be rolled back.
Drop command will delete the entire row also the structure.But truncate will delete the contenets only not the strucure,(todo 意思是说除了表结构,其他类似索引这些东西也会被删掉的吗) so no need to give specifications for another table creation.
DML(Data definition language):select insert delete update 还有一些其他的
DDL(Data definition language):create alter drop
(主要用在定义或者改变表(alter)的结构,数据结构,表之间的连接和约束等初始化工作上)
DCL(Data Control language):数据库控制功能,用来设置或者更改数据库用户或角色权限的语句
包括(grant,deny(否认;拒绝),revoke(撤回,取消,废除)等)
(4)表名:高考信息表
| 准考证号 科目 成绩 2006001 语文 119 2006001 数学 108 2006002 物理 142 2006001 化学 136 2006001 物理 127 2006002 数学 149 2006002 英语 110 2006002 语文 105 2006001 英语 98 2006002 化学 129 |
select 准考证号 from 高考信息表 group by 准考证号 having sum(成绩)>600;| 准考证号 数学 语文 英语 物理 化学 2006001 108 119 98 127 136 2006002 149 105 110 142 129 |
select 准考证号 from 高考信息表 where (数学+语文+英语+物理+化学) > 600
where字句还可以这样子完,以前很少见到,只要这种方法吗?(四部分)
(一)表名:club
| id gender age 67 M 19 68 F 30 69 F 27 70 F 16 71 M 32 |
gender number
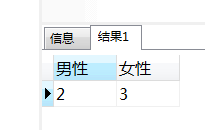
select a.*,b.* from
(select count(*) 男性 from table4 where gender='M') a,
(select count(*) 女性 from table4 where gender='F' )b;
所以可以这样写
select gender ,count(*) 人数 from TABLE4 group by gender;这种其实是最好的写法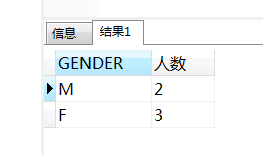
 两种方法
两种方法1 a
2 b
3 b
4 a
5 c
6 c
要求:执行一个删除语句,当Name列上有相同时,只保留ID这列上值小的
例如:删除后的结果应如下:
ID(number型) Name(varchar2型)
1 a
2 b
5 c
select * from team gruop by name having min(id);delete from team where id not in (select min(id) from team group by name) ;(三)表名:student(假设不存在有两个张青这样的人.就只有一个张青)
name course score张青 语文 72
王华 数学 72
张华 英语 81
张青 物理 67
李立 化学 98
张燕 物理 70
张青 化学 76
查询出“张”姓学生中平均成绩大于75分的学生信息
select * from student where name like '张%' group by name having avg(score)>75;
//参考答案
select * from student where name in (select name from student
where name like '张%' group by name having avg(score) > 75)
其实第一种写法不会输出一条记录,因为它的格式错误,错就错在 select * 这里面.所以参考答案才是那样写的.之前没有发现这一点 2017-07-211.一道SQL语句面试题,关于group by表内容:
info 表
date result
2005-05-09 win
2005-05-09 lose
2005-05-09 lose
2005-05-09 lose
2005-05-10 win
2005-05-10 lose
2005-05-10 lose
如果要生成下列结果, 该如何写sql语句?
date win lose
2005-05-09 1 3
2005-05-10 1 2
select date ,count(*) win from info where result ='win' group by date; ----a
select date ,count(*) lose from info where result ='lose' group by date;-----b
有这两句话分别得出这两张表
date win
2005-05-09 1
2005-05-10 1
date lose
2005-05-09 3
2005-05-10 2
然后就是进行连接
select a.date,a.win win,b.lose lose from a left join b on a.date=b.date .
//今天我又发现其实这种写法是存在一个漏洞的 比如说如果 2015-05-09这一天它没有赢过,或者输过呢
//那么是不是用全连接会更好一点呢 其实不然,因为只要具体某一天有比赛,那么肯定就有记录,如果
//某一天真的没有比赛的话,那么其实就没显示这条记录了
//上面那句话说错了吧,具体某一天真的有比赛 可能它都没赢过 那它肯定输过,这个时候赢的下面就是NULL而已 不不不 如果2005-05-09这一天它没有输过,而且它是左连接的话,那么就会少了这一天的.
另一种不常见的方法
select date, sum(case when result = "win" then 1 else 0 end) as "win",
sum(case when result = "lose" then 1 else 0 end) as "lose" from info
group by date; //执行顺序是先分组,然后在分组中,进行统计. 但是这种写法貌似在Oracle中不能执行所以这道题最好的方法是全外连接
20:51:11 SQL> select ename,sal from emp where sal in (select max(sal),min(sal) from emp );
select ename,sal from emp where sal in (select max(sal),min(sal) from emp )
ORA-00913: 值过多
这种写法居然是错的,我简直震惊 有什么好震惊的,这很明显是错的! 子查询返回的是两列啊,可是你只用一列去接收,傻逼啊select ename,max(sal) from emp;
select ename,max(sal) from emp
ORA-00937: 不是单组分组函数
错误的原因是为什么呢
必须这个样子
select ename,sal from emp where sal=(select max(sal) from emp);
ENAME SAL
---------- ---------
KING 5000.00
感觉挺奇怪的。第一种用max(sal)查出来之后明明是已经可以确定一行了。或者多行也可以,但是为什么那种方法不行,这里面一定有什么交易。
但是
21:01:25 SQL> select min(sal),max(sal) from emp;
MIN(SAL) MAX(SAL)
---------- ----------
800 5000
这个就可以,日了狗了。
凭什么啊 只能理解成语法规定吧21:06:43 SQL> select * from emp where sal>avg(sal);
select * from emp where sal>avg(sal)
ORA-00934: 此处不允许使用分组函数
哈哈,在where 字句中是不能这样写的,大哥,不要再犯了
正确答案如下:
21:15:13 SQL> select deptno,avg(sal),max(sal) from emp group by deptno;
DEPTNO AVG(SAL) MAX(SAL)
------ ---------- ----------
30 1566.66666 2850
20 2175 3000
10 2916.66666 5000select max(sal),min(sal) ,deptno from emp group by deptno order by deptno;SQL> select dept.dname ,ename ,sal from emp,dept where emp.deptno=dept.deptno and dept.deptno=10;
DNAME ENAME SAL
-------------- ---------- ---------
ACCOUNTING CLARK 2450.00
ACCOUNTING KING 5000.00
ACCOUNTING MILLER 1300.00
一般是给表取个表名SQL> select * from salgrade;
GRADE LOSAL HISAL
---------- ---------- ----------
1 700 1200
2 1201 1400
3 1401 2000
4 2001 3000
5 3001 9999SQL> select a1.ename,a1.sal,a2.grade from emp a1,salgrade a2 where a1.sal between a2.losal and a2.hisal;
ENAME SAL GRADE
---------- --------- ----------
SMITH 800.00 1
JAMES 950.00 1
ADAMS 1100.00 1
WARD 1250.00 2
MARTIN 1250.00 2
MILLER 1300.00 2
TURNER 1500.00 3
ALLEN 1600.00 3
CLARK 2450.00 4
BLAKE 2850.00 4
JONES 2975.00 4
SCOTT 3000.00 4
FORD 3000.00 4
KING 5000.00 5SQL> select ename ,sal, dname from emp,dept where emp.deptno=dept.deptno order by dept.deptno;
ENAME SAL DNAME
---------- --------- --------------
CLARK 2450.00 ACCOUNTING
KING 5000.00 ACCOUNTING
MILLER 1300.00 ACCOUNTING
JONES 2975.00 RESEARCH
FORD 3000.00 RESEARCH
ADAMS 1100.00 RESEARCH
SMITH 800.00 RESEARCH
SCOTT 3000.00 RESEARCH
WARD 1250.00 SALES
TURNER 1500.00 SALES
ALLEN 1600.00 SALES
JAMES 950.00 SALES
BLAKE 2850.00 SALES
MARTIN 1250.00 SALESSQL> select distinct a1.ename,a2.ename from emp a1,emp a2 where a1.mgr=a2.empno;
ENAME ENAME
---------- ----------
BLAKE KING
TURNER BLAKE
WARD BLAKE
FORD JONES
SMITH FORD
MARTIN BLAKE
ADAMS SCOTT
SCOTT JONES
JONES KING
ALLEN BLAKE
JAMES BLAKE
MILLER CLARKSQL> select * from emp where deptno =(select deptno from emp where ename='SMITH');
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
7369 SMITH CLERK 7902 1980/12/17 800.00 20
7566 JONES MANAGER 7839 1981/4/2 2975.00 20
7788 SCOTT ANALYST 7566 1987/4/19 3000.00 20
7876 ADAMS CLERK 7788 1987/5/23 1100.00 20
7902 FORD ANALYST 7566 1981/12/3 3000.00 20SQL> select ename ,job ,sal ,deptno from emp where job in(select job from emp where deptno=10);
ENAME JOB SAL DEPTNO
---------- --------- --------- ------
CLARK MANAGER 2450.00 10
BLAKE MANAGER 2850.00 30
JONES MANAGER 2975.00 20
KING PRESIDENT 5000.00 10
MILLER CLERK 1300.00 10
JAMES CLERK 950.00 30
ADAMS CLERK 1100.00 20
SMITH CLERK 800.00 20
更好的写法,加上distinct
SQL> select ename ,job ,sal ,deptno from emp where job in(select distinct job from emp where deptno=10);
SQL> select * from emp where (deptno,job)= (select deptno ,job from emp where ename='SMITH'); //列和列之间要对应起来,顺序不能乱
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
7369 SMITH CLERK 7902 1980/12/17 800.00 20
7876 ADAMS CLERK 7788 1987/5/23 1100.00 20SQL> select a1.ename,a1.deptno from emp a1 ,(select deptno,avg(sal) sal from emp group by deptno) a2 where a1.deptno=a2.deptno and a1.sal>a2.sal order by deptno;
ENAME DEPTNO
---------- ------
KING 10
JONES 20
SCOTT 20
FORD 20
ALLEN 30
BLAKE 30
6 rows selectedSQL> select a1.*,rownum rn from (select * from emp) a1;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO RN
----- ---------- --------- ----- ----------- --------- --------- ------ ----------
7369 SMITH CLERK 7902 1980/12/17 800.00 20 1
7499 ALLEN SALESMAN 7698 1981/2/20 1600.00 300.00 30 2
7521 WARD SALESMAN 7698 1981/2/22 1250.00 500.00 30 3
7566 JONES MANAGER 7839 1981/4/2 2975.00 20 4
7654 MARTIN SALESMAN 7698 1981/9/28 1250.00 1400.00 30 5
7698 BLAKE MANAGER 7839 1981/5/1 2850.00 30 6
7782 CLARK MANAGER 7839 1981/6/9 2450.00 10 7
7788 SCOTT ANALYST 7566 1987/4/19 3000.00 20 8
7839 KING PRESIDENT 1981/11/17 5000.00 10 9
7844 TURNER SALESMAN 7698 1981/9/8 1500.00 0.00 30 10
7876 ADAMS CLERK 7788 1987/5/23 1100.00 20 11
7900 JAMES CLERK 7698 1981/12/3 950.00 30 12
7902 FORD ANALYST 7566 1981/12/3 3000.00 20 13
7934 MILLER CLERK 7782 1982/1/23 1300.00 10 14
14 rows selectedSQL> select a1.*,rownum rn from (select * from emp) a1 where rownum<=10;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO RN
----- ---------- --------- ----- ----------- --------- --------- ------ ----------
7369 SMITH CLERK 7902 1980/12/17 800.00 20 1
7499 ALLEN SALESMAN 7698 1981/2/20 1600.00 300.00 30 2
7521 WARD SALESMAN 7698 1981/2/22 1250.00 500.00 30 3
7566 JONES MANAGER 7839 1981/4/2 2975.00 20 4
7654 MARTIN SALESMAN 7698 1981/9/28 1250.00 1400.00 30 5
7698 BLAKE MANAGER 7839 1981/5/1 2850.00 30 6
7782 CLARK MANAGER 7839 1981/6/9 2450.00 10 7
7788 SCOTT ANALYST 7566 1987/4/19 3000.00 20 8
7839 KING PRESIDENT 1981/11/17 5000.00 10 9
7844 TURNER SALESMAN 7698 1981/9/8 1500.00 0.00 30 10
10 rows selectedSQL> select * from (select a1.*,rownum rn from (select * from emp) a1 where rownum<=10) where rn>=6 ;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO RN
----- ---------- --------- ----- ----------- --------- --------- ------ ----------
7698 BLAKE MANAGER 7839 1981/5/1 2850.00 30 6
7782 CLARK MANAGER 7839 1981/6/9 2450.00 10 7
7788 SCOTT ANALYST 7566 1987/4/19 3000.00 20 8
7839 KING PRESIDENT 1981/11/17 5000.00 10 9
7844 TURNER SALESMAN 7698 1981/9/8 1500.00 0.00 30 10select * from (select a1.*,rownum rn from (select 具体的列 from emp) a1 where rownum<=10) where rn>=6 ;SQL> create table mytable324 (id,name ,sal) as select empno ,ename,sal from emp;
Table created
SQL> select * from mytable324;
ID NAME SAL
----- ---------- ---------
7369 SMITH 800.00
7499 ALLEN 1600.00
7521 WARD 1250.00
7566 JONES 2975.00
7654 MARTIN 1250.00
7698 BLAKE 2850.00
7782 CLARK 2450.00
7788 SCOTT 3000.00
7839 KING 5000.00
7844 TURNER 1500.00
7876 ADAMS 1100.00
7900 JAMES 950.00
7902 FORD 3000.00
7934 MILLER 1300.00
14 rows selected