二分图匹配
基本概念:
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
通常分为以下几种匹配:
一、 最大匹配
指在当前已完成的匹配下,无法再通过增加未完成匹配的边的方式来增加匹配的边数。这个问题通常使用匈牙利算法解决,朴素时间复杂度为O(V^3),使用邻接表的前提下时间复杂度为O(VE)。还有一种对匈牙利进行了优化的Hopcroft-Karp算法,时间复杂度为O(sqrt(V)*E)。
二、 完全匹配(完备匹配)
是在最大匹配下的一种特殊情况,指在二分图的两个集合中的点两两都能够得到匹配。
三、 最佳匹配
节点带有权值,在能够完全匹配的前提下,选择匹配方案使得权值之和最大。这个问题通常使用KM算法解决,时间复杂度O(V^3)。
算法介绍:
一、 匈牙利算法
1、基本概念:
1)交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边...形成的路径叫交替路。
2)增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。
如下图所示:
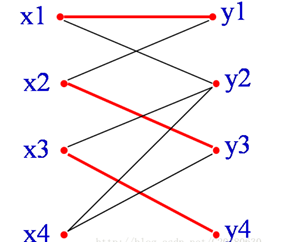
红边为三条已经匹配的边。从X部一个未匹配的顶点x4开始,能找到一条增广路:
x4->y3->x2->y1->x1->y2->x4->y3->x2->y1->x1->y2 。
由增广路的定义可以推出下述三个结论:
①增广路的路径长度必定为奇数,第一条边和最后一条边都不属于M(已匹配子图),因为两个端点分属两个集合,且未匹配。
②增广路经过取反操作(已匹配边变为未匹配边,未匹配边变为已匹配边)可以得到一个更大的匹配M’。
③M为G的最大匹配当且仅当不存在相对于M的增广路径。
2、匈牙利算法能解决的问题:
1)最大匹配
最大匹配的匹配边的数目。
2)最小点覆盖数
二分图的最小点覆盖数=最大匹配数(König定理)
这里说明一下什么是最小点覆盖:假如选了一个点就相当于覆盖了以它为端点的所有边,你需要选择最少的点来覆盖所有的边。
3)最小路径覆盖
最小路径覆盖=顶点数-最大匹配数
在一个N*N的有向图中,路径覆盖就是在图中找一些路经,使之覆盖了图中的所有顶点,
且任何一个顶点有且只有一条路径与之关联;(如果把这些路径中的每条路径从它的起始点走到它的终点。
最小路径覆盖就是找出最小的路径条数,使之成为G的一个路径覆盖。
由上面可以得出:
①一个单独的顶点是一条路径;
②如果存在一路径p1,p2,......pk,其中p1 为起点,pk为终点,那么在覆盖图中,顶点p1,p2,......pk不再与其它的顶点之间存在有向边。
4)最大独立集
最大独立集=顶点数-最大匹配数。
独立集:图中任意两个顶点都不相连的顶点集合。
3、算法实现(别的博客找的)
我们以下图为例说明匈牙利匹配算法。
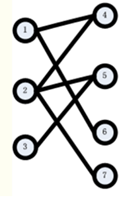
step1:从1开始,找到右侧的点4,发现点4没有被匹配,所以找到了1的匹配点为4 。得到如下图:
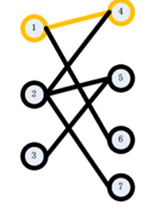
step2:接下来,从2开始,试图在右边找到一个它的匹配点。我们枚举5,发现5还没有被匹配,于是找到了2的匹配点,为5.得到如下图:
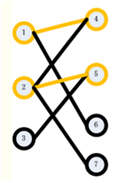
step3:接下来,我们找3的匹配点。我们枚举了5,发现5已经有了匹配点2。此时,我们试图找到2除了5以外的另一个匹配点,我们发现,我们可以找到7,于是2可以匹配7,所以5可以匹配给3,得到如下图:
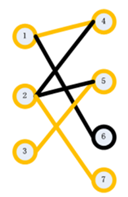
此时,结束,我们得到最大匹配为3。
匈牙利算法的本质就是在不断寻找增广路,直到找不到位置则当前的匹配图就是最大匹配。
二、Hopcroft-Carp
这个算法是匈牙利算法的优化,匈牙利算法是一次寻找一条增广路,而它是一次寻找多条增广路,时间复杂度O(sqrt(V)*E)。
一套不解释模板(其实自己也没看懂,算了算了会用就行)。
三、KM算法
时间复杂度O(n^3)
可以参考这些博客:
详细点的:http://philoscience.iteye.com/blog/1754498
然后我自己也稍微讲两句吧,按自己理解的(可能会讲错)。
这个算法主要是在原来匈牙利算法的基础上加入了顶标这个东西。
开局是一张二分图对吧,然后对于X和Y集合,分别给每个集合的顶点lx[i]和ly[i]表示每个顶点的顶标,g[i][j]是边(i,j)的权值。
初始化一个二分子图,通过lx[i]+y[i]=g[i][j]这个条件判断边是否在二分子图中,然后每当在当前二分子图找不到匹配时,那就要加边了呀~
怎么加呢,只要在交错路上(没匹配成功的增广路)任意添一条都可以(不懂回去看看匈牙利算法),但是我们要权值最大呀,那我们要尽量亏得少,
于是,我们选择了相比原来权值减得最少的边,损失的差值d=min{lx[i]+ly[j]-w[i][j]}(i是交错路中的点,j是不在交错路中的点)。然后就把交错路的X集合点的顶标-d,
交错路中的Y集合点的顶标+d,这样有什么用呢?为了使得二分子图能够多出新的边(至少多一条,即对应d值得边)。差不多就是贪心每次加边亏得最少的边感觉。
贴模板:
匈牙利算法(51Nod 2006 飞行员配对)
#include<iostream> #include<cstdio> #include<cstring> #include<vector> using namespace std; const int N=105; int n,m; //n为顶点数、m位边数 int link[N]; //link[y]=x,即y与x匹配 bool vis[N]; vector<int>v[N]; //用dfs寻找增广路 bool can(int u){ for(int i=0;i<v[u].size();i++){ int t=v[u][i]; if(!vis[t]){ vis[t]=true; if(link[t]==-1||can(link[t])){ //如果t尚未被匹配,或者link[t]即x可以找到其他能够替代的点,则把t点让给u匹配 link[t]=u; return true; } } } return false; } //返回最大匹配数 int max_match(){ memset(link,-1,sizeof(link)); int ans=0; for(int i=1;i<=n;i++){ memset(vis,false,sizeof(vis)); if(can(i)) ans++; } return ans; } int main(){ scanf("%d%d",&n,&m); int a,b; while(~scanf("%d%d",&a,&b)){ if(a==-1&&b==-1) break; v[a].push_back(b); //a和b有关联 } int t=max_match(); if(t==0) puts("No Solution!"); else printf("%d ",t); return 0; }
多重匹配(HDU 3605 Escape)
1 #include<iostream> 2 #include<cstdio> 3 #include<cstring> 4 #include<vector> 5 #include<algorithm> 6 using namespace std; 7 const int N=1e5+5; 8 const int M=15; 9 10 int n,m; 11 int link[M][N],lim[M]; 12 bool vis[M]; 13 vector<int>v[N]; 14 15 bool dfs(int u){ 16 for(int i=0;i<v[u].size();i++){ 17 int t=v[u][i]; 18 if(vis[t]) continue; 19 vis[t]=true; 20 //若t的匹配数量未达到上限,则直接匹配 21 if(link[t][0]<lim[t]){ 22 link[t][++link[t][0]]=u; 23 return true; 24 } 25 //寻找增广路 26 for(int i=1;i<=lim[t];i++){ 27 if(dfs(link[t][i])){ 28 link[t][i]=u; 29 return true; 30 } 31 } 32 } 33 return false; 34 } 35 36 //多重匹配 37 bool mul_match(){ 38 for(int i=1;i<=n;i++){ 39 memset(vis,false,sizeof(vis)); 40 if(!dfs(i)) return false; 41 } 42 return true; 43 } 44 45 void init(){ 46 for(int i=0;i<=n;i++) v[i].clear(); 47 for(int i=1;i<=m;i++) link[i][0]=0; 48 } 49 50 int main(){ 51 while(~scanf("%d%d",&n,&m)){ 52 init(); 53 for(int i=1;i<=n;i++){ 54 for(int j=1;j<=m;j++){ 55 int x; 56 scanf("%d",&x); 57 if(x) v[i].push_back(j); 58 } 59 } 60 for(int i=1;i<=m;i++){ 61 scanf("%d",&lim[i]); 62 } 63 if(mul_match()) puts("YES"); 64 else puts("NO"); 65 } 66 return 0; 67 }
Hopcroft-Carp(HDU 2389 Rain on your Parade)
1 #include <stdio.h> 2 #include <algorithm> 3 #include <iostream> 4 #include <string.h> 5 #include <vector> 6 #include <queue> 7 using namespace std; 8 /* ******************************* 9 * 二分图匹配(Hopcroft-Carp算法) 10 * 复杂度O(sqrt(n)*E) 11 * 邻接表存图,vector实现 12 * vector先初始化,然后假入边 13 * uN 为左端的顶点数,使用前赋值(点编号0开始) 14 */ 15 const int N = 3030; 16 const int INF = 0x3f3f3f3f; 17 vector<int>G[N]; 18 19 int uN,dis; 20 int Mx[N],My[N],dx[N],dy[N]; 21 bool used[N]; 22 23 struct gnode{ 24 int x,y,speed; 25 }guest[N]; 26 27 struct unode{ 28 int x,y; 29 }ubm[N]; 30 31 bool SearchP() 32 { 33 queue<int>Q; 34 dis = INF; 35 memset(dx,-1,sizeof(dx)); 36 memset(dy,-1,sizeof(dy)); 37 for(int i = 0 ; i < uN; i++) 38 if(Mx[i] == -1) 39 { 40 Q.push(i); 41 dx[i] = 0; 42 } 43 while(!Q.empty()) 44 { 45 int u = Q.front(); 46 Q.pop(); 47 if(dx[u] > dis)break; 48 int sz = G[u].size(); 49 for(int i = 0;i < sz;i++) 50 { 51 int v = G[u][i]; 52 if(dy[v] == -1) 53 { 54 dy[v] = dx[u] + 1; 55 if(My[v] == -1)dis = dy[v]; 56 else 57 { 58 dx[My[v]] = dy[v] + 1; 59 Q.push(My[v]); 60 } 61 } 62 } 63 } 64 return dis != INF; 65 } 66 bool DFS(int u) 67 { 68 int sz = G[u].size(); 69 for(int i = 0;i < sz;i++) 70 { 71 int v = G[u][i]; 72 if(!used[v] && dy[v] == dx[u] + 1) 73 { 74 used[v] = true; 75 if(My[v] != -1 && dy[v] == dis)continue; 76 if(My[v] == -1 || DFS(My[v])) 77 { 78 My[v] = u; 79 Mx[u] = v; 80 return true; 81 } 82 } 83 } 84 return false; 85 } 86 87 int max_match() 88 { 89 int res = 0; 90 memset(Mx,-1,sizeof(Mx)); 91 memset(My,-1,sizeof(My)); 92 while(SearchP()) 93 { 94 memset(used,false,sizeof(used)); 95 for(int i = 0;i < uN;i++) 96 if(Mx[i] == -1 && DFS(i)) 97 res++; 98 } 99 return res; 100 } 101 102 int main(){ 103 int q,cas=0; 104 scanf("%d",&q); 105 while(q--){ 106 int time,n,m; 107 scanf("%d%d",&time,&m); 108 for(int i=0;i<=m;i++) G[i].clear(); 109 for(int i=0;i<m;i++){ 110 scanf("%d%d%d",&guest[i].x,&guest[i].y,&guest[i].speed); 111 } 112 scanf("%d",&n); 113 for(int i=0;i<n;i++){ 114 scanf("%d%d",&ubm[i].x,&ubm[i].y); 115 } 116 for(int i=0;i<m;i++){ 117 for(int j=0;j<n;j++){ 118 gnode t1=guest[i]; 119 unode t2=ubm[j]; 120 int dis=abs(t1.x-t2.x)+abs(t1.y-t2.y); 121 if(1.0*dis/t1.speed<=time) G[i].push_back(j); 122 } 123 } 124 uN=m; 125 printf("Scenario #%d: %d ",++cas,max_match()); 126 } 127 return 0; 128 }
KM算法(HDU 2255 奔小康赚大钱)
1 #include<iostream> 2 #include<cstdio> 3 #include<cstring> 4 #include<algorithm> 5 using namespace std; 6 const int N=3e3+5; 7 const int INF=0x3f3f3f3f; 8 9 int nx,ny,d; //nx,ny对应两个集合的点数 10 int link[N],lx[N],ly[N];//lx,ly为顶标,nx,ny为x点集y点集的个数 11 int g[N][N]; //g[i][j]表示集合X中的i点到集合Y中的j点的距离 12 bool visx[N],visy[N]; 13 14 bool dfs(int x){ 15 visx[x]=true; 16 for(int y=0;y<ny;y++){ 17 if(visy[y]) continue; 18 int tmp=lx[x]+ly[y]-g[x][y]; 19 //tmp=0表示边(x,y)在当前子图中 20 if(tmp==0){ 21 visy[y]=true; 22 if(link[y]==-1||dfs(link[y])){ 23 link[y]=x; 24 return true; 25 } 26 } 27 else d=min(tmp,d); //d取最小 28 } 29 return false; 30 } 31 32 int KM(){ 33 //初始化 34 memset(link,-1,sizeof(link)); 35 memset(ly,0,sizeof(ly)); 36 for(int i=0;i<nx;i++){ 37 lx[i]=-INF; 38 for(int j=0;j<ny;j++){ 39 if(g[i][j]>lx[i]) 40 lx[i]=g[i][j]; 41 } 42 } 43 44 for(int x=0;x<nx;x++){ 45 while(true){ 46 memset(visx,false,sizeof(visx)); 47 memset(visy,false,sizeof(visy)); 48 d=INF; 49 if(dfs(x)) break; 50 //如果找不到增广路,则通过更改顶标,将新的边加入子图 51 //d=min{lx[i]+ly[i]-w[i][j]} 52 for(int i=0;i<nx;i++){ 53 if(visx[i]) 54 lx[i]-=d; 55 } 56 for(int i=0;i<ny;i++){ 57 if(visy[i]) 58 ly[i]+=d; 59 } 60 } 61 } 62 int res=0; 63 for(int i=0;i<ny;i++){ 64 if(link[i]!=-1) 65 res+=g[link[i]][i]; 66 } 67 return res; 68 } 69 70 int main(){ 71 int n; 72 while(~scanf("%d",&n)){ 73 for(int i=0;i<n;i++){ 74 for(int j=0;j<n;j++){ 75 scanf("%d",&g[i][j]); 76 } 77 } 78 nx=ny=n; 79 printf("%d ",KM()); 80 } 81 return 0; 82 }