原文链接:https://blog.csdn.net/napoay/article/details/62885899
一、简介
Grok是迄今为止使蹩脚的、无结构的日志结构化和可查询的最好方式。Grok在解析 syslog logs、apache and other webserver logs、mysql logs等任意格式的文件上表现完美。
Grok内置了120多种的正则表达式库,地址:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns。
二、入门例子
下面是一条tomcat日志:
83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png
HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel
Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"
从filebeat中输出到logstash,配置如下:
input {
beats {
port => "5043"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
}
output {
stdout { codec => rubydebug }
}fileter中的message代表一条一条的日志,%{COMBINEDAPACHELOG}代表解析日志的正则表达式,COMBINEDAPACHELOG的具体内容见:https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/httpd。解析后:
{
"request" => "/presentations/logstash-monitorama-2013/images/kibana-search.png",
"agent" => ""Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"",
"offset" => 325,
"auth" => "-",
"ident" => "-",
"input_type" => "log",
"verb" => "GET",
"source" => "/path/to/file/logstash-tutorial.log",
"message" => "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"",
"type" => "log",
"tags" => [
[0] "beats_input_codec_plain_applied"
],
"referrer" => ""http://semicomplete.com/presentations/logstash-monitorama-2013/"",
"@timestamp" => 2016-10-11T21:04:36.167Z,
"response" => "200",
"bytes" => "203023",
"clientip" => "83.149.9.216",
"@version" => "1",
"beat" => {
"hostname" => "My-MacBook-Pro.local",
"name" => "My-MacBook-Pro.local"
},
"host" => "My-MacBook-Pro.local",
"httpversion" => "1.1",
"timestamp" => "04/Jan/2015:05:13:42 +0000"
}再比如,下面这条日志:
55.3.244.1 GET /index.html 15824 0.043- 1
这条日志可切分为5个部分,IP(55.3.244.1)、方法(GET)、请求文件路径(/index.html)、字节数(15824)、访问时长(0.043),对这条日志的解析模式(正则表达式匹配)如下:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}- 1
写到filter中:
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
}- 1
- 2
- 3
- 4
- 5
解析后:
client: 55.3.244.1
method: GET
request: /index.html
bytes: 15824
duration: 0.043- 1
- 2
- 3
- 4
- 5
三、解析任意格式日志
解析任意格式日志的步骤:
- 先确定日志的切分原则,也就是一条日志切分成几个部分。
- 对每一块进行分析,如果Grok中正则满足需求,直接拿来用。如果Grok中没用现成的,采用自定义模式。
- 学会在Grok Debugger中调试。
下面给出例子,来两条日志:
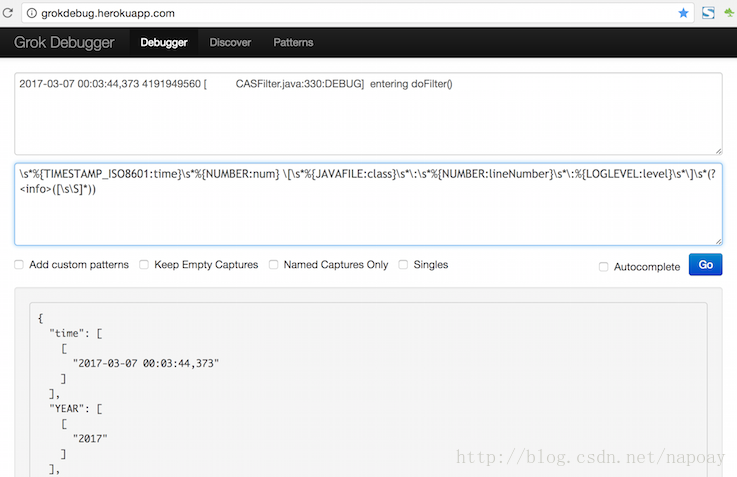
2017-03-07 00:03:44,373 4191949560 [ CASFilter.java:330:DEBUG] entering doFilter()
2017-03-16 00:00:01,641 133383049 [ UploadFileModel.java:234:INFO ] 上报内容准备写入文件- 1
- 2
- 3
切分原则:
2017-03-16 00:00:01,641:时间
133383049:编号
UploadFileModel.java:java类名
234:代码行号
INFO:日志级别
entering doFilter():日志内容
- 1
- 2
- 3
- 4
- 5
- 6
- 7
前五个字段用Grok中已有的,分别是TIMESTAMP_ISO8601、NUMBER、JAVAFILE、NUMBER、LOGLEVEL,最后一个采用自定义正则的形式,日志级别的]之后的内容不论是中英文,都作为日志信息处理,使用自定义正则表达式子的规则如下:
(?<field_name>the pattern here)- 1
最后一个字段的内容用info表示,正则如下:
(?<info>([sS]*))- 1
上面两条日志对应的完整的正则如下,其中s*用于剔除空格。
s*%{TIMESTAMP_ISO8601:time}s*%{NUMBER:num} [s*%{JAVAFILE:class}s*:s*%{NUMBER:lineNumber}s*:%{LOGLEVEL:level}s*]s*(?<info>([sS]*))- 1
正则解析容易出错,强烈建议使用Grok Debugger调试,姿势如下。