服务器数据恢复环境:
某品牌MSA SAN Storage存储;
共8块SAS硬盘:7块硬盘组成RAID5,1块热备盘;
基于RAID5的LUN有6个,均分配给HP-Unix小机使用,上层做的LVM逻辑卷,重要数据为Oracle数据库及OA服务端。
服务器故障:
RAID5有2块硬盘损坏,只有一块热备盘激活,RAID5瘫痪,上层LUN无法使用。服务器管理员联系我们数据恢复中心进行数据恢复。
服务器数据恢复过程:
1、北亚服务器数据恢复工程师收到硬盘以后检测所有硬盘没有发现物理故障,使用硬盘坏道检测工具检测也没有发现坏道。
2、备份数据。使用工具将所有硬盘都镜像成文件。
3、故障分析:
由于硬盘没有发现坏道和其他物理故障,服务器数据恢复工程师初步判断RAID故障的原因是某些磁盘读写不稳定。因为该型号存储控制器的磁盘检测策略严格,会把性能不稳定磁盘认定为坏盘并踢出RAID组。一旦掉线的盘超过该RAID允许掉盘的极限,该RAID将不可用,上层基于RAID的LUN也会不可用。
4、分析RAID结构:
该存储的LUN都是基于RAID的,因此需要先分析底层RAID信息,然后根据分析获取到的信息重构原始RAID。服务器数据恢复工程师经过分析发现4号盘的数据同其他盘不太一样,初步判断该盘是hot Spare盘。接着分析其他盘,分析Oracle数据库页在每个磁盘中分布的情况,并根据数据分布的情况分析出RAID条带大小、磁盘顺序、数据走向等
RAID信息。
5、分析RAID掉线盘:
根据分析获取到的RAID信息使用北亚自主开发的RAID虚拟程序将原始的RAID虚拟重构。但由于该RAID一共掉线两块盘,因此需要分析这两块硬盘掉线的顺序。服务器数据恢复工程师分析每一块硬盘中的数据后发现有一块硬盘在同一个条带上的数据和其他硬盘明显不一样,初步判断此盘是最先掉线的。通过北亚自主开发的RAID校验程序对这个条带做校验,最终确定最先掉线的硬盘了。
6、分析RAID中的LUN信息:
由于LUN是基于RAID的,将RAID虚拟重构出来以后分析LUN在RAID中的分配情况和LUN分配的数据块MAP。只需要将每一个LUN的数据块分布MAP提取出来,然后针对这些信息编写相应的程序对所有LUN的数据MAP做解析,然后根据数据MAP导出所有LUN的数据即可。

7、解析LVM逻辑卷:
对导出来的LUN数据做分析发现所有LUN中均包含HP-Unix的LVM逻辑卷信息。通过解析每个LUN中的LVM信息发现一共有三个LVM,一个LVM中划分了一个LV,存放OA服务器端的数据;另外一个LVM中划分了一个LV,存放临时备份数据;剩余4个LUN组成一个LVM,划分了一个LV,存放Oracle数据库文件。北亚服务器数据恢复工程师编写LVM解释程序将每个LVM中的LV卷解释出来,但解释程序出错。
8、修复LVM逻辑卷:
分析程序报错的原因,开发工程师debug程序出错的位置。文件系统工程师对恢复出来的LUN做检测,检测存储瘫痪是否会导致LMV逻辑卷的信息损坏。经过检测发现存储瘫痪确实导致LVM信息损坏。人工对损坏的区域进行修复,并同步修改程序,重新解析LVM逻辑卷。
9、解析VXFS文件系统:
搭建HP-Unix环境,将解释出来的LV卷映射到HP-Unix,并尝试Mount文件系统。结果Mount文件系统出错,尝试使用“fsck –F vxfs” 命令修复vxfs文件系统,但修复后还是不能挂载。分析可能是底层vxfs文件系统的部分元数据可能被破坏,需要进行手工修复。
10、修复VXFS文件系统:
服务器数据恢复工程师对解析出来的LV进行分析,根据VXFS文件系统的底层结构校验此文件系统是否完整。经过分析发现底层VXFS文件系统有问题,存储瘫痪的同时文件系统正在执行IO操作,部分文件系统元文件损坏。手工修复这些损坏的元文件保证VXFS文件系统能够正常解析。将修复好的LV卷挂载到HP-Unix小机上尝试Mount文件系统,文件系统没有报错,成功挂载。
11、恢复所有用户文件:
在HP-Unix机器上mount文件系统后将所有数据均备份至指定磁盘空间。
12、检测数据库文件是否完整:
使用Oracle数据库文件检测工具检测每个数据库文件是否完整,没有发现错误。使用北亚自主研发的Oracle数据库检测工具检测,发现有部分数据库文件和日志文件校验不一致,安排数据库工程师对此类文件进行修复并再次校验,直到所有文件通过校验。
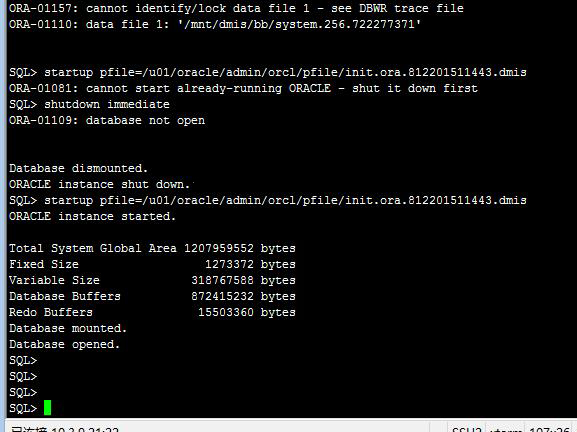
13、启动Oracle数据库:
将恢复出来的Oracle数据库附加到原始生产环境的HP-Unix服务器中尝试启动Oracle数据库,Oracle数据库启动成功。
数据验证:
启动Oracle数据库和OA服务端,在本地电脑安装OA客户端,通过OA客户端对最新的数据记录以及历史数据记录进行验证,并且安排不同部门人员进行远程验证。经过验证确认数据完整无误,数据恢复成功。