本文是基于知乎上的一个答案
基于视频的超分辨率重建是指从许多帧连续的低分辨率图像中重建出一幅高分辨率的图像,并且这幅高分辨率的图像能够显示出单帧低分辨率图像中丢掉的细节,比如下面是一个2秒视频(176x144)中的一帧:

为了方便和分辨率重建之后的图片对比,用Nearest Neighbor放大到了704x576。而下面是重建后的超分辨率图像:

可以看到,许多丢失的细节被重建了,这就是基于视频序列的超分辨率重建。
接下来用一个玩具例子来说明基本原理,首先打开画图板,写下一个
线条分明,软绵无力,面对这么屌的一个字,我决定拍一段长达24帧的8x8分辨率的视频: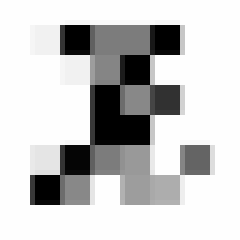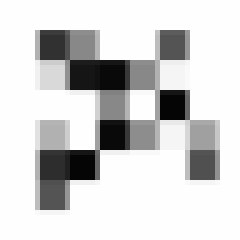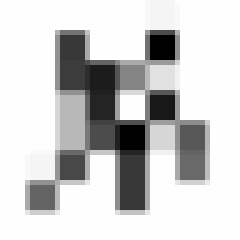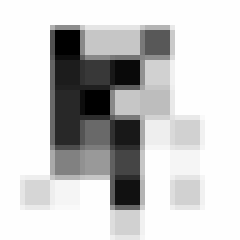
因为手抖,并且相机分辨率低,已经没了屌样。
其实上面的视频是我先把原图的图像随机平移,然后线性插值降采样到8x8分辨率得到的。在这个过程中我模拟了两件事:1) 随机平移模拟视频拍摄过程中的随机抖动,这是从多帧图像中重建超分辨率图像的关键,后面我会讲到,同时这也是符合现实生活规律的,虽然宏观来说拍摄一段静止的视频很容易,可是在像素级别任何微小的画面移动都可以被体现出来。2) 线性插值降采样模拟在CMOS上成像时图像元素小于像素时细节的丢失,线性插值是因为像素记录的值是在像素原件有效感光面积上的平均曝光强度。这两个过程的示意图如下:
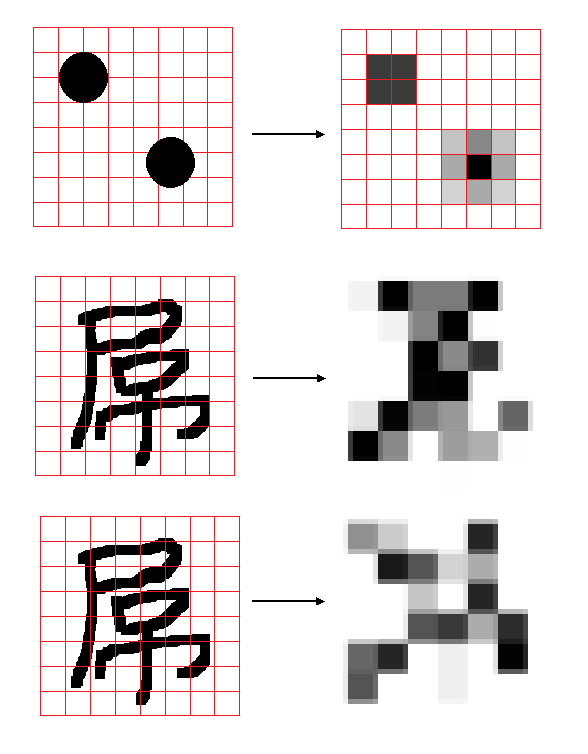
首先看第一个图中两个圆的例子,这两个圆大小完全一样,因为成像位置不同,圆在每个像素上覆盖的面积也不一样,对应像素的灰度会不一样,最后在像素阵列上对应了不同的图案,而这个信息正是进行超分辨率重建的基础。同样的对于写下的屌字,在不同的抖动位置上,也会得到不一样的低分辨率图案。
所以问题可以描述为,一幅高分辨率的图像(I_{H}),经过n次某种变换({{I}_{L}}=Fleft( {{I}_{H}} ight))后得到了n幅低分辨率图像,其中第i幅图像为(I_{L,i})。而具体到视频录制中,"某种变换"就是每次拍摄每一帧的时候记录图像的过程,具体到这个例子中(F())就是手抖导致的图像平移和线性插值的降采样。
所以本质上来讲从多帧低分辨率图像中进行超分辨率重建是个Inference的问题,高分辨率图像中的细节信息在录制成低分辨率帧的时候导致了丢失,然而抖动带来的位移相当于给了多一个维度的信息让我们可以通过算法对信息进行恢复,从某种意义上讲抖动保存了原来图像的细节信息。抖动有多重要呢,先来做一个简单的试验,尽管采样到的帧分辨率都低得可怜,可是我们如果把抖动的信息恢复出来,也就是把抖动后的这些低分辨率图片对齐,然后求一个平均,结果如下:
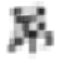
这时候已经可以勉强看出屌样了。。
进一步的,我们想推断出更高分辨率的图像,一个很自然的想法就是对超分辨率图像进行猜测,把猜测的图像变换后的结果和录制采样到的结果进行对比,然后把差异作为目标函数进行优化:
[min sumlimits_{i=1}^{n}{left| {{I}_{L,i}}-Fleft( {{I}_{H,i}}
ight)
ight|}]
对于上面这个优化问题,如果抖动的范围完美覆盖了一个像素周期以内的所有区域,并且高分辨率图像在每个不同位置都至少对应一帧的话,那么理论上是可以完美恢复出高分辨率图像的。然而通常情况并非如此,比方说我想把我例子中24帧8x8的视频恢复成一幅48x48的高分辨率图像,也就是6倍的分辨率提升,那么24帧显然不够,这种情况叫做ill-posed,也就是说有无数个解可以满足这个优化问题,所以需要一些regularization。通常而言我们看到的图像一般都是较为平滑的,而不是像老式电视机里没信号是那样满屏的雪花斑噪声,所以可以加入一项抑制图像梯度的项:
[min sumlimits_{i=1}^{n}{left| {{I}_{L,i}}-{{F}_{i}}left( {{I}_{H}}
ight)
ight|}+left|
abla {{I}_{H}}
ight|]
注意我这里用的都是L1 Norm,一般来说L1的优点是使梯度的分布更为稀疏,这样能更好的保存边缘,另外计算量也小。
用遗传算法来解这个优化问题试试,得到结果如下:
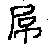
进化过程的示意图:

因为是GA,所以看上去还是有些瑕疵,不过屌样已经很明显了,如果继续优化应该能得到更接近原图的效果。当然了,如前所述,我只是用一个玩具例子讲一下超分辨率重构的基本思想。具体的问题中,除了抖动和低分辨率采样,还有镜头PSF(Point Spread Function),图像的转动和其他形变,场景中的物体移动等因素,优化算法也不会是GA这种相比起来漫无目的的搜索(虽然我还修改了变异和交叉函数)。另外降采样我这里用的是线性插值,这包含一个假设,就是每个像素的感光元件的有效感光面积接近这个元件在传感器表面占用的面积,而这个假设通常是不严格成立的,尤其是对现在消费级相机和手机中流行的CMOS。因为在知乎上收到过一些反馈,还要特别说的是为什么要用遗传算法:1) 回答问题的时候手头刚好有个GA工具包(基于MIT的GALib),2)“屌”的例子是个二值图案,3)可以做出相变般酷炫的动画。作为一个玩具例子,我觉得屌还是挺不错的,但是要强调的是,如果用到实际中,1)GA是不合适,屌字也不合适,尤其是这么极端的图案,不管L几Norm都是降不下去的。
而对于比较实际的情况下的超分辨率图像重建,在OpenCV里实现已经非常简单了,代码如下:
1 cv::Ptr<cv::superres::FrameSource> frames = cv::superres::createFrameSource_Video( "diao.mp4" ); 2 cv::Ptr<cv::superres::SuperResolution> super_res = cv::superres::createSuperResolution_BTVL1(); 3 super_res->setInput( frames ); 4 5 cv::Mat super_resolved_image; 6 super_res->nextFrame( super_resolved_image ); 7 8 cv::imshow( "Super Resolved Image", super_resolved_image ); 9 cv::waitKey( 0 );
这个代码的测试结果就是文章一开始的两幅对比图。通常情况下超分辨率重建运算量还是比较大的,所以实际情况代码不会这么简单,一个用到GPU的的例子可以在OpenCV的sample code里找到。