import re,requests,json
headers = {'Referer':'https://movie.douban.com/typerank?type_name=%E5%89%A7%E6%83%85%E7%89%87&type=11&interval_id=100:90&action=1',#向服务器表示从哪个页面发起的请求#
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'#user-agent:表示系统以及浏览器型号
}#爬虫伪装#
for i in range(0,100):
res=requests.get("https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start="+str(i)+"&limit=1",headers=headers) #i对应表示电影排名的json文件#
res.encoding = "UTP-8"
re_dict=re.compile(r"{.*}")#正则表达式过滤数据#
dict=re_dict.search(res.text)
rank=dict.group()
rank_movie_dict=json.loads(rank)#将过滤数据转为python对象 并放入词典#
print(rank_movie_dict["title"])
for j in rank_movie_dict["actors"]:
print(j + "/", end="")
print(" ")
print(rank_movie_dict["release_date"] + "/", end="")
for j in rank_movie_dict["regions"]:
print(j + "/", end="")
print(" ")
for j in rank_movie_dict["types"]:
print(j + "/",end="")
print(" ")
print("评分:" + str(rank_movie_dict["score"]) + "评分人数" + str(rank_movie_dict["vote_count"]))
print("_______________________________________________________")
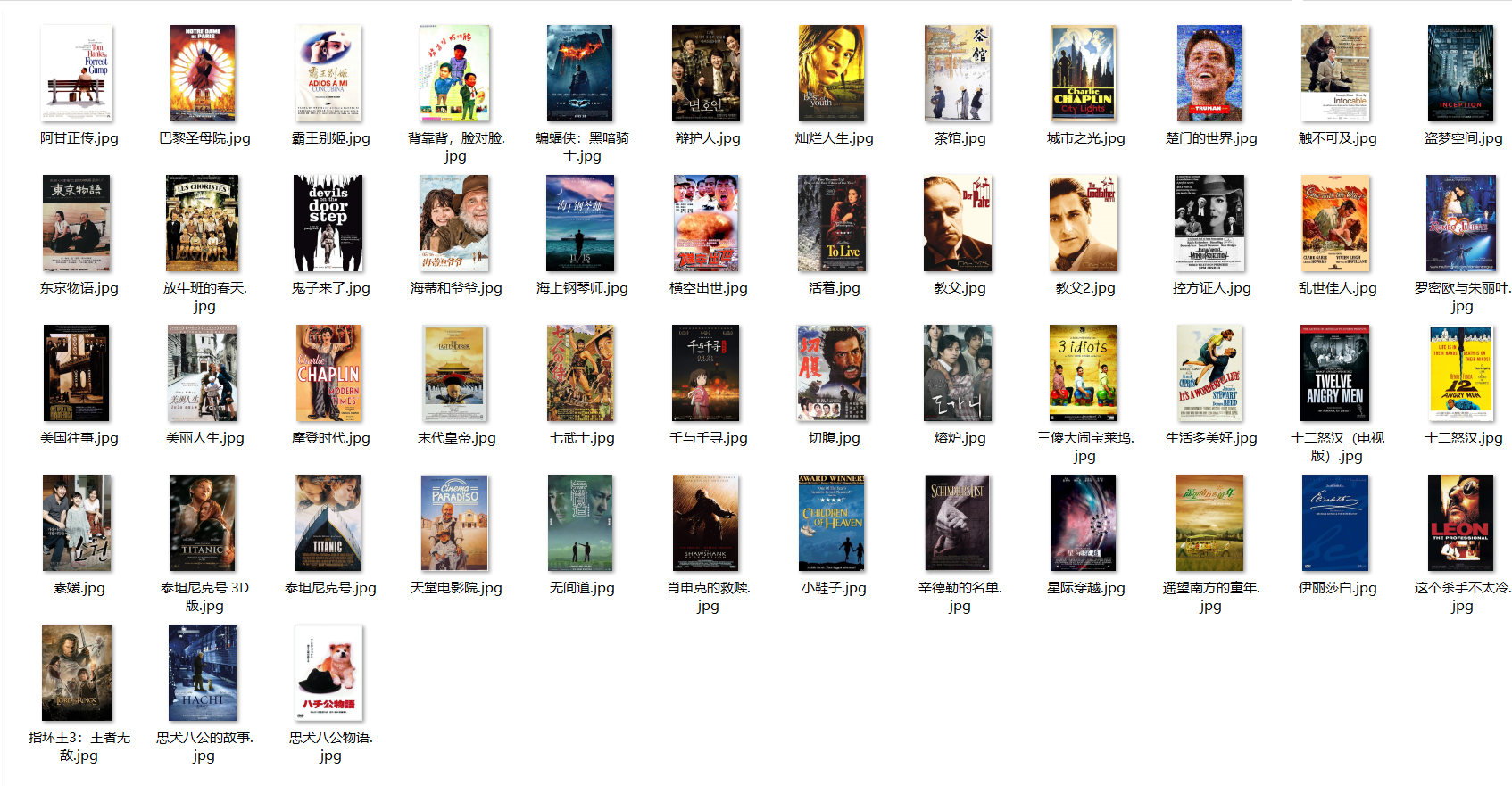
img_url=rank_movie_dict["cover_url"]#获取图片地址#
res_img=requests.get(img_url,headers=headers)
res_img.raise_for_status()
with open(".\豆瓣电影图片\" + rank_movie_dict["title"] + ".jpg", "wb") as p:
p.write(res_img.content)#写入二进制数据#
运行结果: