序列化
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes
- 把内存数据 转成字符,叫序列化
- 把字符 转成内存数据,叫反序列化
模块 json
json.dumps() 序列化一个对象
import json
data = {
'roles':[
{'role':'monster','type':'pig','life':50},
{'role':'hero','type':'关羽','life':80},
]
}
d = json.dumps(data) #转成字符串
print(type(d))
print(d)
打印结果:
<class 'str'>
{"roles": [{"role": "monster", "type": "pig", "life": 50}, {"role": "hero", "type": "u5173u7fbd", "life": 80}]}
json.lodads() 从一个对象加载数据
import json
data = {
'roles':[
{'role':'monster','type':'pig','life':50},
{'role':'hero','type':'关羽','life':80},
]
}
d = json.dumps(data) #仅转成字符串
d2 = json.loads(d)
print(type(d2),d2)
#<class 'dict'>
#{'roles': [{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': '关羽', 'life': 80}]}
json.dump() 将一个对象序列化存入文件
import json
data = {
'roles':[
{'role':'monster','type':'pig','life':50},
{'role':'hero','type':'关羽','life':80},
]
}
f = open('test.json',mode='w')
json.dump(data, f) #转成字符并写入文件
结果:会将 data中的数据写入文件
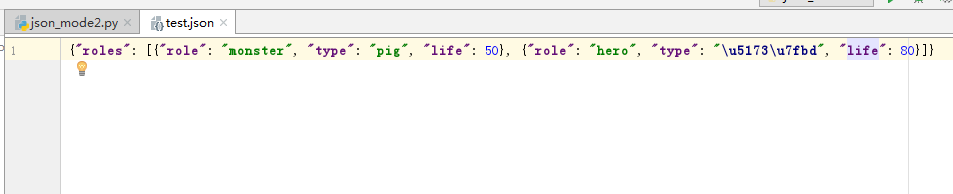
json.load() 从一个打开的文件句柄加载数据
import json
f = open('test.json','r')
data = json.load(f)
print(data['roles'])
打印:
[{'role': 'monster', 'type': 'pig', 'life': 50}, {'role': 'hero', 'type': '关羽', 'life': 80}]
import json
f = open('json_file.json','w',encoding='utf-8')
data1 = {'name':'nurato','skill':'螺旋丸'}
data2 = [1,2,3,'sunshine']
json.dump(data1, f)
json.dump(data2, f)
结果:
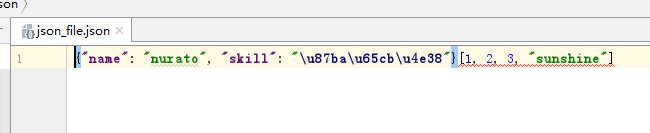
说明: 可以dump多次数据并写入文件
我们现在json.load 一下
f = open('json_file.json','r',encoding='utf-8')
json.load(f)
# 程序报错:json.decoder.JSONDecodeError
只load 一次,并且json格式有问题,会报错
------------------------------------------------分割线------------------------------------------------
模块pickle
import pickle
data1 = {'name':'nurato','skill':'螺旋丸'}
f = open('data.pkl','wb')
pickle.dump(data1,f)
结果:创建了一个 名为 data.pkl 的文件
import pickle
f = open('data.pkl','rb')
d = pickle.load(f)
print(type(d))
print(d)
#<class 'dict'>
#{'name': 'nurato', 'skill': '螺旋丸'}
关于json 和 pickle
JSON:
优点:跨语言、体积小
缺点:只能支持intstrlist upledict
Pickle:
优点:专为python设计,支持python所有的数据类型
缺点:只能在python中使用,存储数据占空间大
---------------------------------------分割线-------------------------------------------
序列化 shelve 模块
import shelve
f = shelve.open('shelve_test') #打开一个文件
names = ['python', 'html', 'java']
info = {'name': 'jack', 'age': 25}
f['names'] = names
f['info_dic'] = info
f.close()
结果:会创建 shelve_test 文件
import shelve
f = shelve.open('shelve_test') #打开一个文件
print(list(f.keys())) #['names', 'info_dic']
print(list(f.items())) #[('names', ['python', 'html', 'java']), ('info_dic', {'name': 'jack', 'age': 25})]
print(f.get('names')) #['python', 'html', 'java']
print(f.get('info_dic')) #{'name': 'jack', 'age': 25}
增加内容:
import shelve
f = shelve.open('shelve_test') #打开一个文件
f['book'] = [1,2,3,4,5] #增加内容
f.close()
f2 = shelve.open('shelve_test')
print(list(f2.keys())) # ['names', 'info_dic', 'book']
print(f2['book'])
我们来修改一下内容:(只能通过 f['book'] = [1,2,'肖申克的救赎',4,5]) 这样的方式重新赋值来更改
f['book'][0] = 'new book' 这样的方式是不可以的。
import shelve
f = shelve.open('shelve_test') # 打开一个文件
f['book'] = [1,2,'肖申克的救赎',4,5]
f.close()
f2 = shelve.open('shelve_test')
print(f2['book']) # [1, 2, '肖申克的救赎', 4, 5]
删除内容:
import shelve
f = shelve.open('shelve_test') #打开一个文件
del f['book']
f.close()
f2 = shelve.open('shelve_test')
print(list(f2.items()))
# 打印 : [('names', ['python', 'html', 'java']), ('info_dic', {'name': 'jack', 'age': 25})]