
- 文件-a, --all 包含所有的具有 0 Blocks 的文件系统
- 文件--block-size={SIZE} 使用 {SIZE} 大小的 Blocks
- 文件-h, --human-readable 使用人类可读的格式(预设值是不加这个选项的...)
- 文件-H, --si 很像 -h, 但是用 1000 为单位而不是用 1024
- 文件-i, --inodes 列出 inode 资讯,不列出已使用 block
- 文件-k, --kilobytes 就像是 --block-size=1024
- 文件-l, --local 限制列出的文件结构
- 文件-m, --megabytes 就像 --block-size=1048576
- 文件--no-sync 取得资讯前不 sync (预设值)
- 文件-P, --portability 使用 POSIX 输出格式
- 文件--sync 在取得资讯前 sync
- 文件-t, --type=TYPE 限制列出文件系统的 TYPE
- 文件-T, --print-type 显示文件系统的形式
- 文件-x, --exclude-type=TYPE 限制列出文件系统不要显示 TYPE
- 文件-v (忽略)
- 文件--help 显示这个帮手
- 文件--version 输出版本资讯
显示文件系统的磁盘使用情况统计:
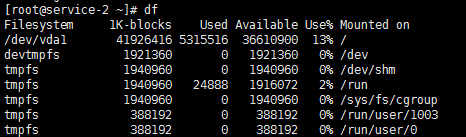
第一列指定文件系统的名称,第二列指定一个特定的文件系统1K-块1K是1024字节为单位的总内存。用、可用、正在使用中,分别指定的内存量。
使用列指定使用的内存的百分比,而最后一栏"安装在"指定的文件系统的挂载点。
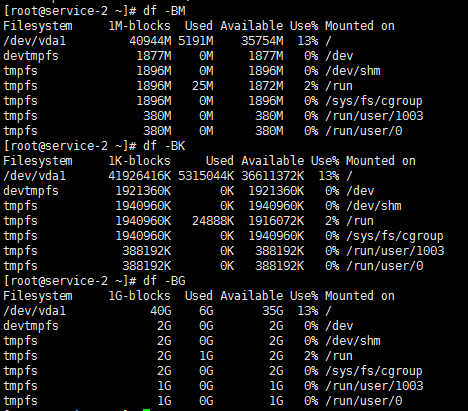
显示不同Size的使用情况:
df也可以显示磁盘使用的文件系统信息:
# df test
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda6 29640780 4320600 23814492 16% /
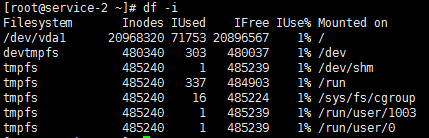
用一个-i选项的df命令的输出显示inode信息而非块使用量。
显示所有的信息:
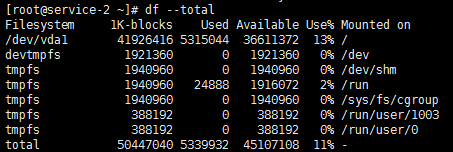
输出的末尾,包含一个额外的行,显示总的每一列。
-h选项,通过它可以产生可读的格式df命令的输出:
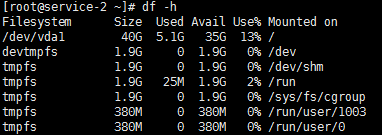
输出显示的数字形式的'G'(千兆字节),"M"(兆字节)和"K"(千字节)。
这使输出容易阅读和理解,从而使显示可读的。
请注意,第二列的名称也发生了变化,为了使显示可读的"大小"。