通过第一篇我们发现一行很神奇的代码。
while(true){//循环侦听新的客户端的连接 //调用accept()方法侦听,等待客户端的连接以获取Socket实例 socket = serverSocket.accept();
这行代码,我一直想知道和了解一下,serverSocket.accept() 这一句到底是如何实现阻塞监听端口的。
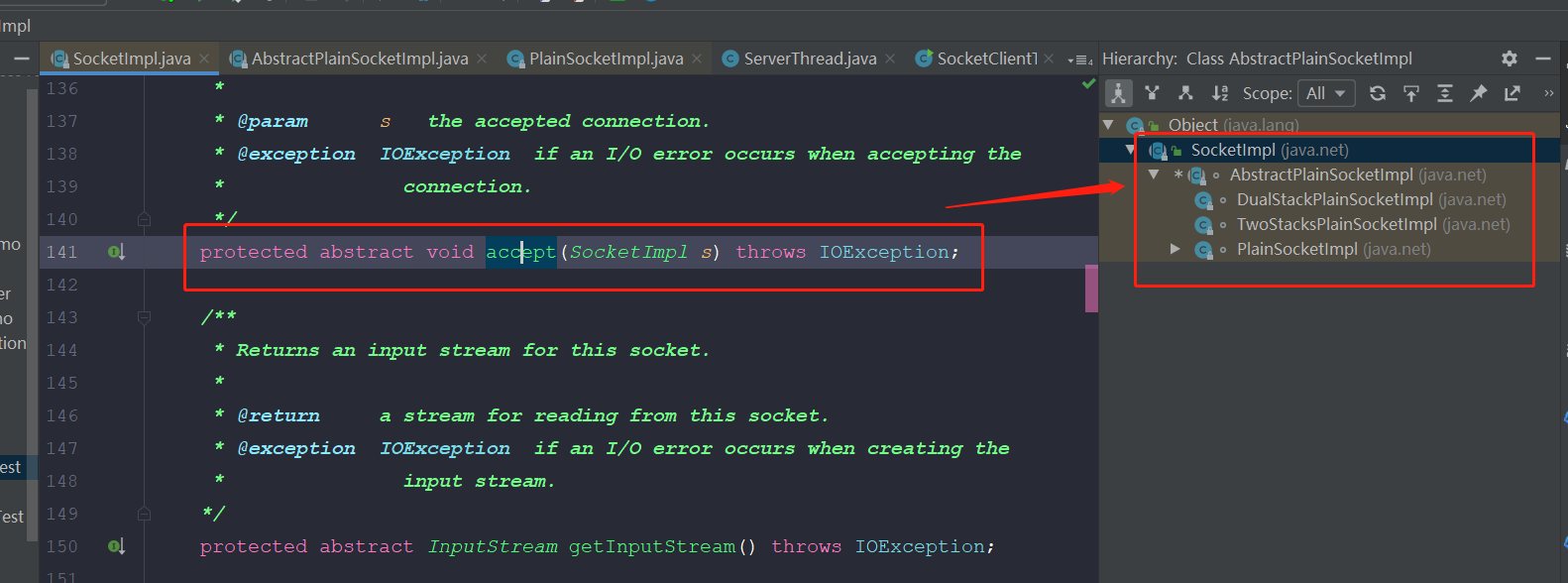
在这里,找到accept()的实现类plainSocketImpl类
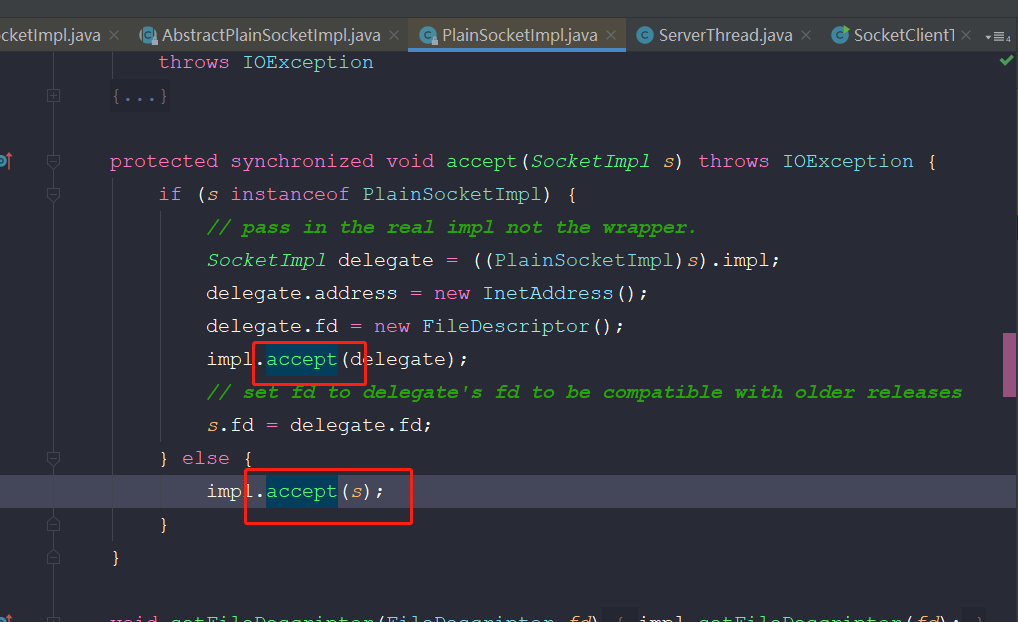

进入发现,仍然是accept(),看来应该是在JDK中找不到最终的实现了。
于是,通过网上的各种搜索,找到的答案,在这里记录一下,仅作为扩展知识面的记录。
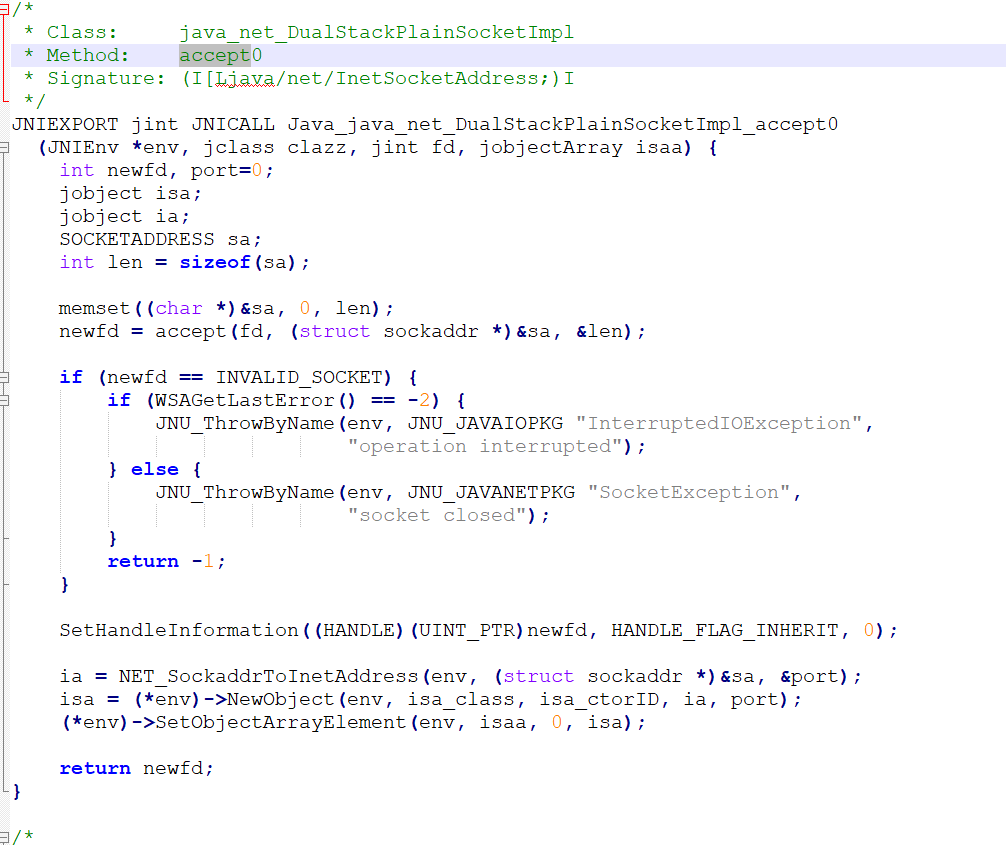
写过安卓的话,就会发现,这是JNI的native代码了,应该是C的方法了。
在系统中找到了头文件winsock2.h。
函数声明在这里。但是找不到对应的实现。想到linux中应该有类似开源的源码。
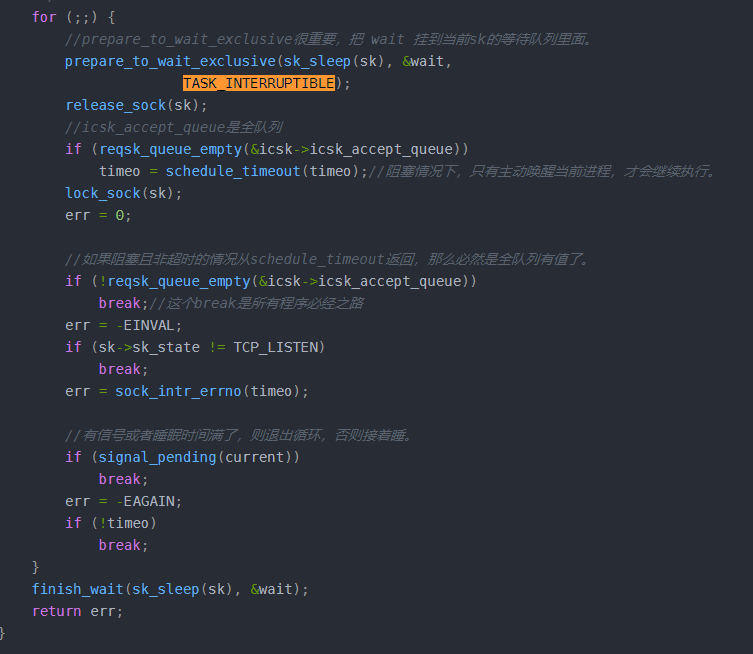
抄自另一博客主的解释,通过一些资料后,发现还是比较正确的,记录如下:
首先,为什么循环?这是历史原因,考虑有这么一种情况,就是睡眠时间没有睡满,那么 schedule_timeout返回的值大于0,那么什么情况下,睡眠没有睡满呢?一种情况就是进程收到信号,另一种就是listenfd对应的socket的全队列有数据了,不考虑信号的情况,假设全队列有数据了,历史上,Linux的accept是惊群的,全队列有值后,所有进程都唤醒,那么必然存在某些进程读取到了全队列socket,而某些没有读取到,这些没有读取到的进程,肯定是睡眠没睡满,所以需要接着睡。
但是本文分析的Linux内核版本是3.10,全队列有数据时,只会唤醒一个进程,故而,次for循环只会跑一次。
prepare_to_wait_exclusive函数很重要,把当前上下文加到listenfd对应的socket等待队列里面,如果是多进程,那么listenfd对应的socket等待队列里面会有多个进程的上下文。
多进程 accept 如何处理惊群
多进程accept,不考虑resuseport,那么多进程accept只会出现在父子进程同时accept的情况,那么上文也说过,prepare_to_wait_exclusive函数会被当前进程上下文加入到listenfd等待队列里面,所以父子进程的上下文都会加入到socket的等待队列里面。核心问题就是这么唤醒,我们可以相当,所谓的惊群,就是把等待队里里面的所有进程都唤醒。
注意上图中首先将进程加入到等待队列里面,并设置为可中断。schedule_timeout是理想的延迟方法。会让需要延迟的任务睡眠指定的时间。最核心的是schedule函数。
它的前后是设置定时器,和删除定时器。定时器到指定时间会唤醒进程,重新加入就绪队列。但是我们知道在每到指定时间的时候也可以唤醒进程,就是因为设置了可中断。
看来是schedule实现了阻塞。
signed long __sched schedule_timeout(signed long timeout) { struct timer_list timer; unsigned long expire; switch (timeout) { case MAX_SCHEDULE_TIMEOUT: //睡眠时间无限大,则不需要设置定时器。 /* * These two special cases are useful to be comfortable * in the caller. Nothing more. We could take * MAX_SCHEDULE_TIMEOUT from one of the negative value * but I' d like to return a valid offset (>=0) to allow * the caller to do everything it want with the retval. */ schedule(); goto out; default: /* * Another bit of PARANOID. Note that the retval will be * 0 since no piece of kernel is supposed to do a check * for a negative retval of schedule_timeout() (since it * should never happens anyway). You just have the printk() * that will tell you if something is gone wrong and where. */ if (timeout < 0) { printk(KERN_ERR "schedule_timeout: wrong timeout " "value %lx\n", timeout); dump_stack(); current->state = TASK_RUNNING; goto out; } } expire = timeout + jiffies; setup_timer_on_stack(&timer, process_timeout, (unsigned long)current); __mod_timer(&timer, expire, false, TIMER_NOT_PINNED); schedule(); del_singleshot_timer_sync(&timer); /* Remove the timer from the object tracker */ destroy_timer_on_stack(&timer); timeout = expire - jiffies; out: return timeout < 0 ? 0 : timeout; }
内核版本2.6.39。schedule主要实现了进程调度。即让出当前进程的CPU,切换上下文。既然切换到其它进程执行了,而当前进程又进入了等待队列,不再会被调度。
直到时间结束,或者中断来。这时候会从schedule返回。删除定时器。根据返回的timeout值判断是否大于0判断是睡眠到时间被唤醒,还是因为有连接了提前唤醒。
/* * schedule() is the main scheduler function. */ asmlinkage void __sched schedule(void) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; need_resched: preempt_disable(); //禁止内核抢占 cpu = smp_processor_id(); //获取当前CPU rq = cpu_rq(cpu); //获取该CPU维护的运行队列(run queue) rcu_note_context_switch(cpu); //更新全局状态,标识当前CPU发生上下文的切换。 prev = rq->curr; //运行队列中的curr指针赋予prev。 schedule_debug(prev); if (sched_feat(HRTICK)) hrtick_clear(rq); raw_spin_lock_irq(&rq->lock); //锁住该队列 switch_count = &prev->nivcsw; //记录当前进程的切换次数 if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { //是否同时满足以下条件:1该进程处于停止状态,2该进程没有在内核态被抢占。 if (unlikely(signal_pending_state(prev->state, prev))) { //若不是非挂起信号,则将该进程状态设置成TASK_RUNNING prev->state = TASK_RUNNING; } else { //若为非挂起信号则将其从队列中移出 /* * If a worker is going to sleep, notify and * ask workqueue whether it wants to wake up a * task to maintain concurrency. If so, wake * up the task. */ if (prev->flags & PF_WQ_WORKER) { struct task_struct *to_wakeup; to_wakeup = wq_worker_sleeping(prev, cpu); if (to_wakeup) try_to_wake_up_local(to_wakeup); } deactivate_task(rq, prev, DEQUEUE_SLEEP); //从运行队列中移出 /* * If we are going to sleep and we have plugged IO queued, make * sure to submit it to avoid deadlocks. */ if (blk_needs_flush_plug(prev)) { raw_spin_unlock(&rq->lock); blk_schedule_flush_plug(prev); raw_spin_lock(&rq->lock); } } switch_count = &prev->nvcsw; //切换次数记录 } pre_schedule(rq, prev); if (unlikely(!rq->nr_running)) idle_balance(cpu, rq); put_prev_task(rq, prev); next = pick_next_task(rq); //挑选一个优先级最高的任务将其排进队列。 clear_tsk_need_resched(prev); //清除pre的TIF_NEED_RESCHED标志。 rq->skip_clock_update = 0; if (likely(prev != next)) { //如果prev和next非同一个进程 rq->nr_switches++; //队列切换次数更新 rq->curr = next; ++*switch_count; //进程切换次数更新 context_switch(rq, prev, next); /* unlocks the rq */ //进程之间上下文切换 /* * The context switch have flipped the stack from under us * and restored the local variables which were saved when * this task called schedule() in the past. prev == current * is still correct, but it can be moved to another cpu/rq. */ cpu = smp_processor_id(); rq = cpu_rq(cpu); } else //如果prev和next为同一进程,则不进行进程切换。 raw_spin_unlock_irq(&rq->lock); post_schedule(rq); preempt_enable_no_resched(); if (need_resched()) //如果该进程被其他进程设置了TIF_NEED_RESCHED标志,则函数重新执行进行调度 goto need_resched; }
多进程 accept 如何处理惊群
多进程accept,不考虑resuseport,那么多进程accept只会出现在父子进程同时accept的情况,那么上文也说过,prepare_to_wait_exclusive函数会被当前进程上下文加入到listenfd等待队列里面,所以父子进程的上下文都会加入到socket的等待队列里面。核心问题就是这么唤醒,我们可以相当,所谓的惊群,就是把等待队里里面的所有进程都唤醒。
我们此时来看看如何唤醒。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) { struct sock *rsk; ...... if (sk->sk_state == TCP_LISTEN) { struct sock *nsk = tcp_v4_hnd_req(sk, skb); if (!nsk) goto discard; if (nsk != sk) { sock_rps_save_rxhash(nsk, skb); //当三次握手客户端的ack到来时,会走tcp_child_process这里 if (tcp_child_process(sk, nsk, skb)) { rsk = nsk; goto reset; } return 0; } } ...... } tcp_child_process: int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) { struct sock *rsk; ...... if (sk->sk_state == TCP_LISTEN) { struct sock *nsk = tcp_v4_hnd_req(sk, skb); if (!nsk) goto discard; if (nsk != sk) { sock_rps_save_rxhash(nsk, skb); //当三次握手客户端的ack到来时,会走tcp_child_process这里 if (tcp_child_process(sk, nsk, skb)) { rsk = nsk; goto reset; } return 0; } } ...... } parent->sk_data_ready: static void sock_def_readable(struct sock *sk, int len) { struct socket_wq *wq; rcu_read_lock(); wq = rcu_dereference(sk->sk_wq); //显然,我们在accept的时候调用了`prepare_to_wait_exclusive`加入了队列,故唤醒靠 wake_up_interruptible_sync_poll if (wq_has_sleeper(wq)) wake_up_interruptible_sync_poll(&wq->wait, POLLIN | POLLPRI | POLLRDNORM | POLLRDBAND); sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN); rcu_read_unlock(); } #define wake_up_interruptible_sync_poll(x, m) \ __wake_up_sync_key((x), TASK_INTERRUPTIBLE, 1, (void *) (m)) void __wake_up_sync_key(wait_queue_head_t *q, unsigned int mode, int nr_exclusive, void *key) { unsigned long flags; int wake_flags = WF_SYNC; if (unlikely(!q)) return; if (unlikely(!nr_exclusive)) wake_flags = 0; spin_lock_irqsave(&q->lock, flags); //mode是TASK_INTERRUPTIBLE nr_exclusive是1, __wake_up_common(q, mode, nr_exclusive, wake_flags, key); spin_unlock_irqrestore(&q->lock, flags); } __wake_up_common: static void __wake_up_common(wait_queue_head_t *q, unsigned int mode, int nr_exclusive, int wake_flags, void *key) { wait_queue_t *curr, *next; list_for_each_entry_safe(curr, next, &q->task_list, task_list) { unsigned flags = curr->flags; //prepare_to_wait_exclusive时候,flags是WQ_FLAG_EXCLUSIVE,入参nr_exclusive是1,所以只执行一次就break了。 if (curr->func(curr, mode, wake_flags, key) && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive) break; } }
结论:
所以多个进程accept的时候,内核只会唤醒1个等待的进程,且唤醒的逻辑是FIFO。