1 概念
散列:散列也叫散列函数,是一种可以将任意长度的输入转换为固定长度输出的算法,因此不同的输入可能产生相同的输出。
散列码:散列码就是按照散列函数生成的结果。
2 散列在编程语言中的应用
散列可以将对象信息提取出摘要,然后产生固定长度的结果,我们利用这个结果跟对象关联起来就能达到快速查找对象的目的。那么,在众多的对象查找方法里,为什么要使用散列?因为快,就相当于抽象的Map直接通过key(散列结果)获取value(散列关联的对象),它的速度是O(1)。而像遍历的方法(线性搜索)获取对象速度很慢,随着集合里面的数据集膨胀它的速度是O(n)。
2.1 散列在Java中应用
Java中使用散列的数据结构有HashMap、HashSet(使用HashMap实现的)、LinkedHashMap或者LinkedHashSet,如果想要自己定义的对类这些数据结构里正确无误的运行就必须重写hashCode()和equals()方法,否则就老老实实的使用Java标准类库的类。
2.1.1 忽略重写hashCode()和equals()方法引发的问题
创建People和房屋类House然后让people寻找自己的房子
2.1.1.1 创建People
假设people的身份证号相同我们就认为他们是同一个人。
public class People {
private String idcard;
public People(String idcard) {
this.idcard = idcard;
}
@Override
public String toString() {
return "[People: "+idcard+"]";
}
}
2.1.1.2 创建House
public class House {
/**
* 门牌号
*/
private String houseNum;
public House(String houseNum) {
this.houseNum = houseNum;
}
@Override
public String toString() {
return "[门牌号:"+houseNum+"]";
}
}
2.1.1.3 people开始寻找房子
import java.util.*;
public class PeopleTest {
public static void main(String[] args) {
findHouse();
}
static void findHouse() {
Map<People, House> houseMap = new HashMap<>();
for (int i = 1; i <= 3; i++) {
People people = new People("" + i + i + i);
houseMap.put(people, new House("C-" + i));
}
//打印houseMap
System.out.println("houseMap:"+houseMap);
//身份证号为222的people寻找自己的房子
System.out.println("身份证号为222的people寻找自己的房子....");
People people222 = new People("222");
House housec2 = houseMap.get(people222);
if (Objects.isNull(housec2)) {
System.out.println("身份证号为222的people没找见自己的房子");
}else {
System.out.println("身份证号为222的people找见自己的房子:"+housec2);
}
}
}
结果:
houseMap:{[People: 111]=[门牌号:C-1], [People: 222]=[门牌号:C-2], [People: 333]=[门牌号:C-3]}
身份证号为222的people寻找自己的房子....
身份证号为222的people没找见自己的房子
因为People继承了Object类,所以People使用的是Object方法生成的散列码,Object使用对象的地址计算散列码,所以每个People的散列码不可能相同。如果这些不同散列码按照HashMap哈希函数static final int hash(Object key) 得到的结果一样,HashMap就会调用People的equals()方法去进行比较键值是否已经在表中存在。然而,People的equals()方法依然是调用Object的equals()方法,Object.equals()方法是比较两个对象的引用,更加不可能相等了。
2.1.1.4 重写哈希和equals方法
正确的重写equals()需满足以下条件
- 自反性。任意x,x.equals(x)必须返回true。
- 对称性。任意x、y,y.equals(x)返回true那么x.equals(y)也必须返回true。
- 传递性。任意x、y、z,如果x.equals(y)返回true,y.equals(z)返回true,那么x.equals(z)必须返回true。
- 一致性。对于任意x、y,如果他们中用于比较的信息不变,那么无论调用多少次x.equals(y)返回的结果必须一致,要么一直是true,要么一直是false。
- 对于任意不是null的x,x.equals(null)必须返回false。
重写People
import java.util.Objects;
public class People {
private String idcard;
public People(String idcard) {
this.idcard = idcard;
}
@Override
public boolean equals(Object o) {
//引用相等直接返回true
if (this == o) return true;
//比较是否是同一类型
if (o == null || getClass() != o.getClass()) return false;
People people = (People) o;
//身份证号相同就认为是同一个人
return Objects.equals(this.idcard, people.idcard);
}
@Override
public int hashCode() {
return Objects.hash(idcard);
}
@Override
public String toString() {
return "[People: "+idcard+"]";
}
}
再次找房子,看看结果:
houseMap:{[People: 111]=[门牌号:C-1], [People: 222]=[门牌号:C-2], [People: 333]=[门牌号:C-3]}
身份证号为222的people寻找自己的房子....
身份证号为222的people找见自己的房子:[门牌号:C-2]
2.1.2 理解hashCode()
2.1.2.1 看看ArrayList是怎么查询元素的。
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
显而易见在这种非散列的数据结构中,是通过遍历表然后使用equals()方法来判断元素是否相同,这种线程的查询方式效率是最低的。
2.1.2.2 通过非散列方式实现Map
思路:定义两个按照添加元素有序的集合,添加key的同时添加value,他们的key和value在同一个index位置是对应的。
数据生成
import java.util.Map;
import java.util.Random;
/**
* 生成姓名和身份证号Map数据
*/
public class MapDataGenerator {
public static void idcard(Map<String, String> data) {
String[] names = {"张旭磊", "张忆之", "张美叶", "陈磊", "陈京泓", "陈豪龙", "王艺霏", "王健超", "孙佳妍", "孙悟空"};
for (String key : names) {
int val = 0;
Random random = new Random();
val=random.nextInt(900000)+100000;
data.put(key, ""+val+val+val);
}
}
}
实现Map
MapEntry
import java.util.Map;
import java.util.Objects;
public class MapEntry<K,V> implements Map.Entry<K,V>{
private K key;
private V value;
MapEntry(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public K getKey() {
return this.key;
}
@Override
public V getValue() {
return this.value;
}
@Override
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override
public String toString() {
return "MapEntry{" +
"key=" + key +
", value=" + value +
'}';
}
@Override
@SuppressWarnings("unchecked")
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MapEntry mapEntry = getClass().cast(o);
return Objects.equals(key, mapEntry.key) &&
Objects.equals(value, mapEntry.value);
}
@Override
public int hashCode() {
return Objects.hash(key);
}
}
SlowMap
import com.freesky.collection.MapDataGenerator;
import java.util.*;
public class SlowMap<K, V> extends AbstractMap<K, V> {
//保存key的集合
private ArrayList<K> keys = new ArrayList<>();
//保存value的集合
private ArrayList<V> values = new ArrayList<>();
/**
* @param key
* @param value
* @return 返回改key旧值,如果该key第一次放入,返回null
*/
public V put(K key, V value) {
V oldValue = get(key);
//判断该key是否存在,不存在就添加,存在就将旧值用传入的新值代替
if (!keys.contains(key)) {
keys.add(key);
values.add(value);
} else {
//线性定位key
values.set(keys.indexOf(key), value);
}
return oldValue;
}
@Override
public V get(Object key) {
if (!keys.contains(key)) {
return null;
}
//线性定位key
return values.get(keys.indexOf(key));
}
@Override
public Set<Map.Entry<K,V>> entrySet(){
Set<Map.Entry<K, V>> set = new HashSet<>();
Iterator<K> keyIterator = keys.iterator();
Iterator<V> valueIterator = values.iterator();
while (keyIterator.hasNext()) {
set.add(new MapEntry<>(keyIterator.next(), valueIterator.next()));
}
return set;
}
private class MapEntry<K,V> implements Map.Entry<K,V>{
private K key;
private V value;
MapEntry(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public K getKey() {
return this.key;
}
@Override
public V getValue() {
return this.value;
}
@Override
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override
public String toString() {
return "MapEntry{" +
"key=" + key +
", value=" + value +
'}';
}
@Override
@SuppressWarnings("unchecked")
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MapEntry mapEntry = getClass().cast(o);
return Objects.equals(key, mapEntry.key) &&
Objects.equals(value, mapEntry.value);
}
@Override
public int hashCode() {
return Objects.hash(key);
}
}
public static void main(String[] args) {
Map<String, String> slowMap = new SlowMap<>();
MapDataGenerator.idcard(slowMap);
System.out.println("打印SlowMap.............................");
System.out.println(slowMap+"
");
System.out.println("打印孙悟空的身份证号.............................");
System.out.println(slowMap.get("孙悟空")+"
");
System.out.println("打印entrySet.............................");
System.out.println(slowMap.entrySet());
}
}
运行结果:
打印SlowMap.............................
{陈京泓=168528168528168528, 孙悟空=205116205116205116, 孙佳妍=449358449358449358, 张美叶=674041674041674041, 陈磊=620317620317620317, 陈豪龙=332670332670332670, 张忆之=916686916686916686, 王健超=503536503536503536, 张旭磊=717568717568717568, 王艺霏=608515608515608515}
打印孙悟空的身份证号.............................
205116205116205116
打印entrySet.............................
[MapEntry{key=陈京泓, value=168528168528168528}, MapEntry{key=孙悟空, value=205116205116205116}, MapEntry{key=孙佳妍, value=449358449358449358}, MapEntry{key=张美叶, value=674041674041674041}, MapEntry{key=陈磊, value=620317620317620317}, MapEntry{key=陈豪龙, value=332670332670332670}, MapEntry{key=张忆之, value=916686916686916686}, MapEntry{key=王健超, value=503536503536503536}, MapEntry{key=张旭磊, value=717568717568717568}, MapEntry{key=王艺霏, value=608515608515608515}]
总结:put()方法将key和value放入对应的List中,同样遵循了Map规范,put()返回key对应的旧值,不存在的话就返回null,get()方法依然是在key不存在时返回null,如果key存在就根据key的索引获取对应的value值。MapEntry的实现了Map.Entry,简单的进行key和value的保存。
使用entrySet()修改map值
public static void modifyMapValueByMapEntry(Map<String, String> map){
MapDataGenerator.idcard(map);
map.entrySet().forEach(en->{
//找出孙悟空,然后将他的身份证号设置成999999
if (en.getKey().equals("孙悟空")) {
en.setValue("999999");
}
});
System.out.println(map);
}
- 将SlowMap传入,修改孙悟空的身份证号
public static void main(String[] args) {
Map<String, String> map = new SlowMap<>();
modifyMapValueByMapEntry(map);
}

孙悟空的身份证号没有像预期中发生改变
2. 将传入参数换成HashMap
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
modifyMapValueByMapEntry(map);
}
结果

结论:SlowMap的MapEntry实现不恰当,因为它创建了Map的副本,不能修改Map。而HashMap的Entry使用Map的视图可以对Map进行修改。
2.1.2.3 通过散列实现Map
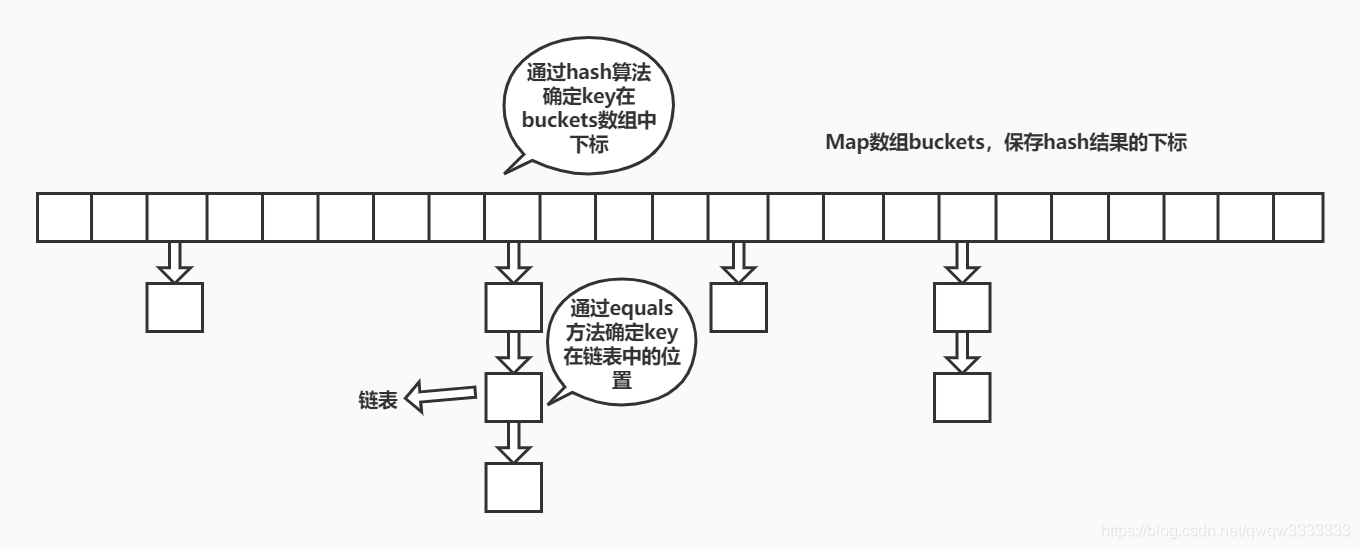
SlowMap说明了创建Map很简单,但是SlowMap使用了线性查询进行key的查找,效率低下。数组是储存获取元素最快的容器,我们可以用数据储存键的信息,是不是可以直接使用hashCode()作为数组下标?
答案是:不可以。因为自带的hashCode()值范围是int型散列值,范围是int值范围,太大了。而数组的容量是有限的。因此可以利用散列函数将hashCode()转换成固定大小的值作为数组的下标。这就是散列码。生成散列码的方法就是hashCode()。
为了解决数组容量问题,允许不同的键生成相同的下标(hash冲突),所以数组的大小就不重要了,任何键都能在数组中找到它的位置。
如何解决hash冲突
如果能保证没有冲突,那就是完美的散列,但是这种情况很少见。冲突由外部链接处理:数组不保存值本身,而是保存值的List或者树状结构数据。
查询过程:
- 先根据hash算法计算数组下标index。
- 根据index定位数组中的位置。
- 获取该位置链表或者树结构数据,然后使用equals方法进行比值操作。
- 第三步找到key后返回对应的value,否则返回null
2.1.2.4 实现散列Map
SimpleHashMap
import com.freesky.collection.MapDataGenerator;
import java.util.*;
public class SimpleHashMap<K, V> extends AbstractMap<K, V> {
private static final int CAPICITY = 999;
private LinkedList<MapEntry<K, V>>[] buckets = new LinkedList[CAPICITY];
@Override
public V put(K key, V value) {
V oldValue = null;
int len = buckets.length;
int hash = hash(key);
//对数组长度和hash结果进行高效取余操作,数组永远不会越界
int index = (len - 1) & hash;
if (Objects.isNull(buckets[index])) {
buckets[index] = new LinkedList<>();
}
LinkedList<MapEntry<K, V>> bucket = buckets[index];
MapEntry<K, V> mapEntry = new MapEntry<>(key, value);
boolean found = false;
ListIterator<MapEntry<K, V>> iterator = bucket.listIterator();
while (iterator.hasNext()) {
MapEntry<K, V> entry = iterator.next();
//找到等值的key
if (entry.getKey().equals(key)) {
//给oldValue赋值,将返回
oldValue = entry.getValue();
//设置新的entry
iterator.set(mapEntry);
found = true;
break;
}
}
if (!found) {
buckets[index].add(mapEntry);
}
return oldValue;
}
@Override
public V get(Object key) {
int len = buckets.length;
int hash = hash(key);
int index = (len - 1) & hash;
LinkedList<MapEntry<K, V>> bucket = buckets[index];
if (Objects.isNull(bucket)) {
return null;
}
for (MapEntry<K, V> b : bucket) {
if (b.getKey().equals(key)) {
return b.getValue();
}
}
return null;
}
private int hash(Object key) {
int h;
//hashCode可能为负数,key不为空时保证hash结果是正数
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
@Override
public Set<Map.Entry<K, V>> entrySet() {
Set<Map.Entry<K, V>> set = new HashSet<>();
for (LinkedList<MapEntry<K, V>> bucket : buckets) {
if (Objects.isNull(bucket)) {
continue;
}
set.addAll(bucket);
}
return set;
}
public static void main(String[] args) {
Map<String, String> slowMap = new SimpleHashMap<>();
MapDataGenerator.idcard(slowMap);
System.out.println("打印SlowMap.............................");
System.out.println(slowMap+"
");
System.out.println("打印孙悟空的身份证号.............................");
System.out.println(slowMap.get("孙悟空")+"
");
System.out.println("打印entrySet.............................");
System.out.println(slowMap.entrySet());
}
}
运行结果

2.1.2.5 总结
Map中数组的下标值依赖Map容量,容量的改变和容器的充满程度和负载因子有关。将key的hashCode()结果经过特殊处理作为Map中数组的下标。无论何时,一个对象的hashCode()结果必须相同,put和get元素时的算法也必须相同,否则就有可能放进去的元素和取出来的不相等。hashCode()不能依赖唯一性的对象信息,否则就不能使一个新产生的键和put进去的键相同,比如使用默认的hashCode()的值(默认的hashCode()是对象的地址),永远不可能重复。
有效的hashCode()是基于对象信息生成的散列码,而且可以重复,但是必须保证通过hashCode()和equals()确定对象的唯一性。
好的hashCode()应该尽可能的分布均匀,否则数据就会集中在HashMap、HashSet等散列容器的某些区域,就像晾衣服只把衣服晾在绳子的一两个地方,造成局部负载过重,严重影响容器的插入和取值效率。