1.二级索引的核心思想是什么?2.二级索引由谁来管理?3.在主表中插入某条数据后,hbase如何将索引列写到索引表中去?4.scan查询的时候,coprocessor钩子的作用是什么?5.在split的时候,索引表在什么时候对数据划分?![]()
本文是以华为二级索引为例:
华为在HBTC 2012上由其高级技术经理Anoop Sam John透露了其二级索引方案,这在业界引起极大的反响,甚至有人认为,如果华为早点公布这个方案,hbase的某些问题早就解决了。其核心思想是保证索引表和主表在同一个region server上。更新:目前该方案华为已经开源,详见:https://github.com/Huawei-Hadoop/hindex下面来对其方案做一个分析。1.整体架构这个架构在Client Ext中设定索引细节,在Balancer中收集信息,在Coprocessor中管理二级索引数据。<ignore_js_op>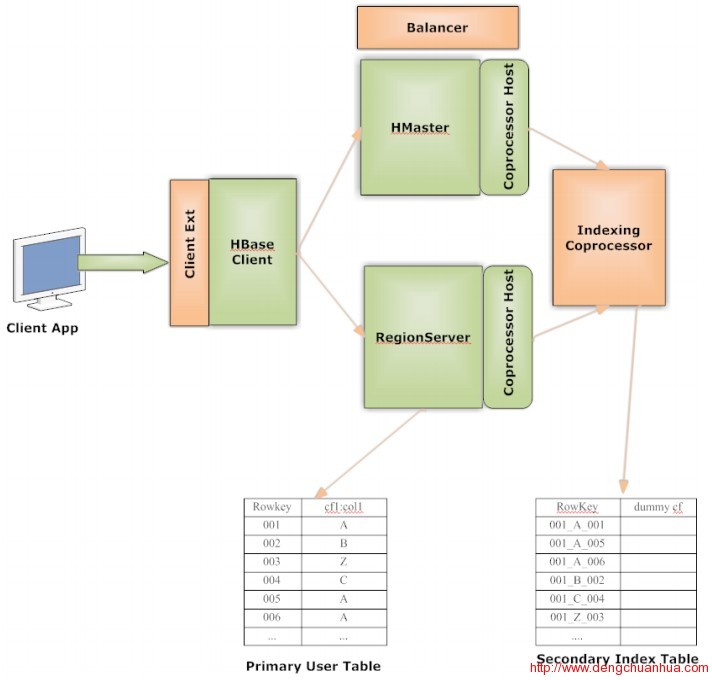
2.表创建在创建表的时候,在同一个region server上创建索引表,且一一对应。<ignore_js_op>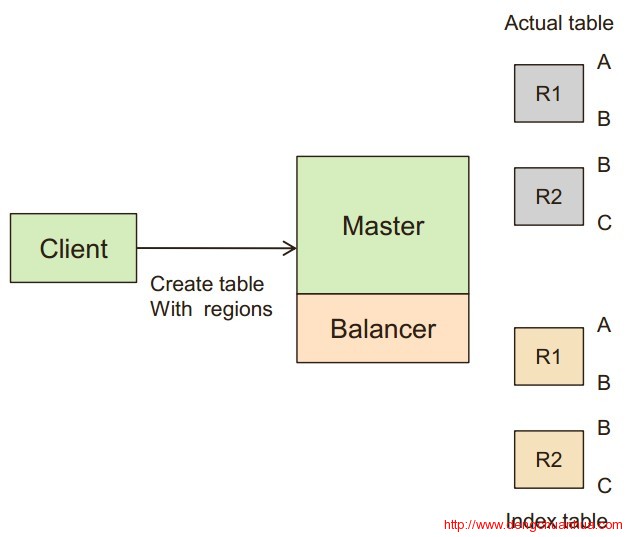
3.插入操作在主表中插入某条数据后,用Coprocessor将索引列写到索引表中去,写道索引表中的数据的主键为:region开始key+索引名+索引列值+主表row key。这么做,是为了让其在同一个分布规则下,索引表会跟主表在通过region server上,在查询的时候就可以少一次rpc。<ignore_js_op> 4.scan操作一个查询到来的时候,通过coprocessor钩子,先从索引表中查询范围row,然后再从主表中相关row中扫描获得最终数据。<ignore_js_op>
4.scan操作一个查询到来的时候,通过coprocessor钩子,先从索引表中查询范围row,然后再从主表中相关row中扫描获得最终数据。<ignore_js_op>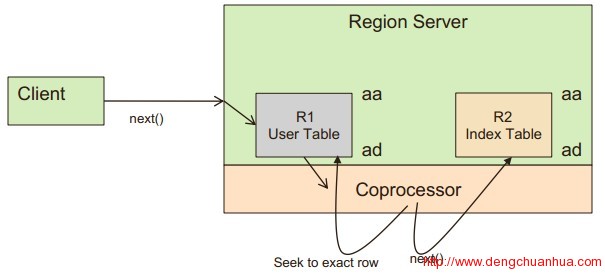 5. split操作处理为了使主表和索引表在同一个RS上,要禁用索引表的自动和手动split,只能由主表split的时候触发,当主表split的时候,对索引表按其对应数据进行划分,同时,对索引表的第二个daughter split的row key的前面部分修改为对应的主键的row key。<ignore_js_op>
5. split操作处理为了使主表和索引表在同一个RS上,要禁用索引表的自动和手动split,只能由主表split的时候触发,当主表split的时候,对索引表按其对应数据进行划分,同时,对索引表的第二个daughter split的row key的前面部分修改为对应的主键的row key。<ignore_js_op>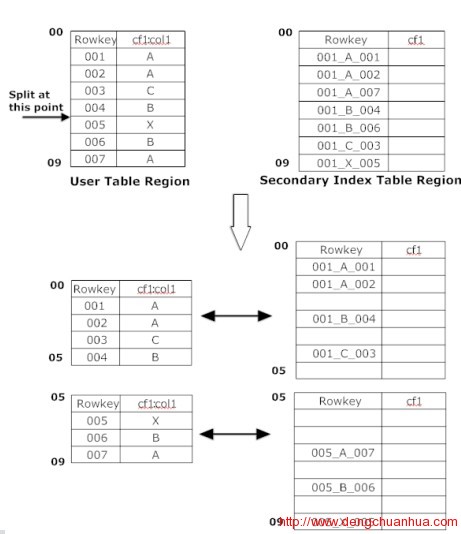 6. 性能查询性能极大提升,插入性能下降10%左右<ignore_js_op>
6. 性能查询性能极大提升,插入性能下降10%左右<ignore_js_op>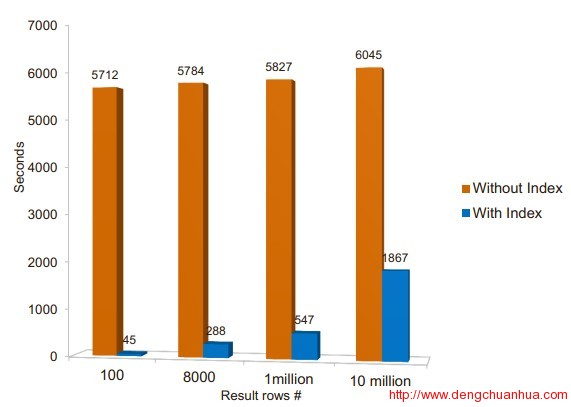 <ignore_js_op>
<ignore_js_op>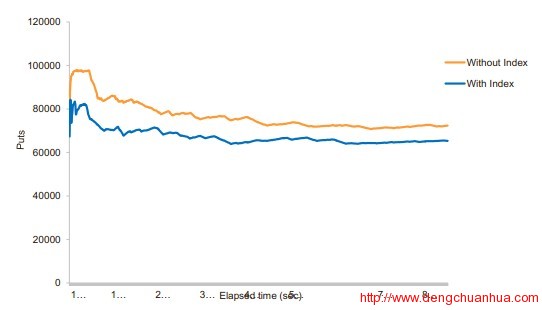 总结,本文对华为hbase使用coprocessor进行二级索引的方案的创建表,插入数据,查询数据的步骤进行了一个粗略分析,以窥其全貌。在使用的时候,可以作为一个参考。
总结,本文对华为hbase使用coprocessor进行二级索引的方案的创建表,插入数据,查询数据的步骤进行了一个粗略分析,以窥其全貌。在使用的时候,可以作为一个参考。
###############################################################转载自邓的博客