简介
Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据。Hive本身不存储数据,它完全依赖HDFS和MapReduce。这样就可以将结构化的数据文件映射为为一张数据库表,并提供完整的SQL查询功能,并将SQL语句最终转换为MapReduce任务进行运行。 而HBase表是物理表,适合存放非结构化的数据。
- 两者分别是什么?
Apache Hive是数据仓库。通过Hive可以使用HQL语言查询存放在HDFS上的数据。HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce. 虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询--因为它是基于MapReduce算法。
Apache Hbase Key/Value,基础单元是cell,它运行在HDFS之上。和Hive不一样,Hbase的能够在它的数据库上实时运行,而不是运行MapReduce任务,。
2. 两者的特点
Hive帮助熟悉SQL的人运行MapReduce任务。因为它是JDBC兼容的。运行Hive查询会花费很长时间,因为它会默认遍历表中所有的数据。但可以通过Hive的分区来控制。因为这样一来文件大小是固定的,就这么大一块存储空间,从固定空间里查数据是很快的。
HBase通过存储key/value来工作。注意版本的功能。
- 应用场景
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase非常适合用来进行大数据的实时查询。Facebook用Hbase进行消息和实时的分析。它也可以用来统计Facebook的连接数。 - 总结
Hive和Hbase是两种基于Hadoop的不同技术--Hive是一种类SQL的引擎,可以直接将文件转成数据库。并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。Hive可以用来进行统计查询,HBase可以用来进行实时查询。数据也可以从Hive写到Hbase,再从Hbase写回Hive。
Note, Hive is not something you install on worker nodes. Hive is a Hadoop client. Just run Hive according to the instructions you see at the Hive site.
Hive不需要安装到每个HADOOP节点,它是一个HADOOP客户端,仅在需要的地方安装即可
安装前提:
安装好了hadoop,hadoop的集群搭建。
安装好了mysql。这里我们就开始安装MySQL
安装MySql
1.1 卸载原有的Mysql
在root用户下操作 找出mysql的相关目录
sudo find / -name mysql
显示结果为:
/usr/share/bash-completion/completions/mysql
/etc/apparmor.d/abstractions/mysql
通过命令rm -rf将mysql有关目录都删除掉,例如我这里只有上述的两个目录
sudo rm -rf /etc/apparmor.d/abstractions/mysql
sudo rm -rf /usr/share/bash-completion/completions/mysql
1.2 使用以下命令即可进行mysql安装,注意安装前先更新一下软件源以获得最新版本
sudo apt-get install mysql-server #安装mysql
上述命令会安装以下包:
apparmor
mysql-client-5.7
mysql-common
mysql-server
mysql-server-5.7
mysql-server-core-5.7
因此无需再安装mysql-client等。安装过程会提示设置mysql root用户的密码,设置完成后等待自动安装即可。默认安装完成就启动了mysql。
- 启动和关闭mysql服务器:
service mysql start
service mysql stop
- 确认是否启动成功,mysql节点处于LISTEN状态表示启动成功:
sudo netstat -tap | grep mysql

- 进入mysql shell界面:
mysql -u root -p
- 解决利用sqoop导入MySQL中文乱码的问题(可以插入中文,但不能用sqoop导入中文)
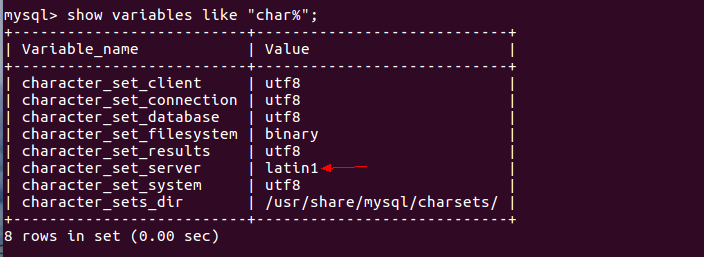
导致导入时中文乱码的原因是character_set_server默认设置是latin1,如下图。
可以单个设置修改编码方式set character_set_server=utf8;但是重启会失效,建议按以下方式修改编码方式。
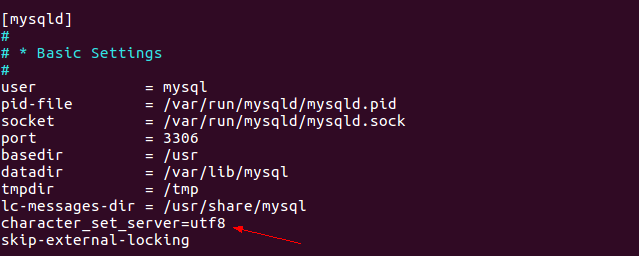
(1)编辑配置文件。sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
(2)在[mysqld]下添加一行character_set_server=utf8。如下图
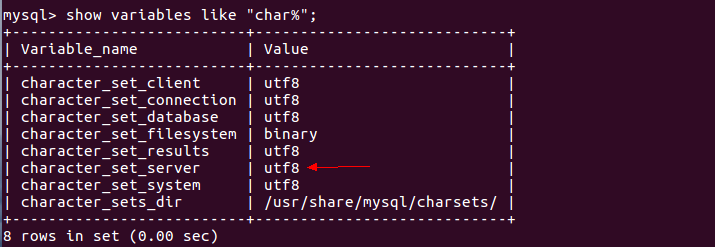
(3)重启MySQL服务。service mysql restart
(4)登陆MySQL,并查看MySQL目前设置的编码。show variables like "char%";
MySQL常用操作
注意:MySQL中每个命令后都要以英文分号;结尾。
1、显示数据库
mysql> show databases;
MySql刚安装完有两个数据库:mysql和test。mysql库非常重要,它里面有MySQL的系统信息,我们改密码和新增用户,实际上就是用这个库中的相关表进行操作。
2、显示数据库中的表
mysql> use mysql; (打开库,对每个库进行操作就要打开此库)
Database changed
mysql> show tables;
3、显示数据表的结构:
describe 表名;
4、显示表中的记录:
select * from 表名;
例如:显示mysql库中user表中的纪录。所有能对MySQL用户操作的用户都在此表中。
select * from user;
5、建库:
create database 库名;
例如:创建一个名字位aaa的库
mysql> create databases aaa;
6、建表:
use 库名;
create table 表名 (字段设定列表);
例如:在刚创建的aaa库中建立表person,表中有id(序号,自动增长),xm(姓名),xb(性别),csny(出身年月)四个字段
use aaa;
mysql> create table person (id int(3) auto_increment not null primary key, xm varchar(10),xb varchar(2),csny date);
可以用describe命令察看刚建立的表结构。
mysql> describe person;
describe-person
7、增加记录
例如:增加几条相关纪录。
mysql>insert into person values(null,’张三’,’男’,’1997-01-02′);
mysql>insert into person values(null,’李四’,’女’,’1996-12-02′);
因为在创建表时设置了id自增,因此无需插入id字段,用null代替即可。
可用select命令来验证结果。
mysql> select * from person;
select-from-person
8、修改纪录
例如:将张三的出生年月改为1971-01-10
mysql> update person set csny=’1971-01-10′ where xm=’张三’;
9、删除纪录
例如:删除张三的纪录。
mysql> delete from person where xm=’张三’;
10、删库和删表
drop database 库名;
drop table 表名;
11、查看mysql版本
在mysql5.0中命令如下:
show variables like ‘version’;
或者:select version();
Hive 安装
配置mysql
- 启动并登陆mysql shell
service mysql start #启动mysql服务
mysql -u root -p #登陆shell界面
- 新建hive数据库。
mysql> create database hive;
- 配置mysql允许hive接入:
mysql> create user 'hive'@'%' identified by 'hive'; # 用户,机器名,密码
mysql> grant all on *.* to 'hive'@'%' identified by 'hive'; #将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
mysql> flush privileges; #刷新mysql系统权限关系表
安装Hive
- 下载并解压hive源程序
Hive下载地址
sudo tar -zxvf ./apache-hive-2.2.0-bin.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv apache-hive-2.2.0-bin hive # 将文件夹名改为hive
sudo chown -R hadoop hive # 修改文件权限
- 配置环境变量
为了方便使用,我们把hive命令加入到环境变量中去,编辑~/.bashrc文件vim ~/.bashrc,在最前面一行添加:
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
保存退出后,运行source ~/.bashrc使配置立即生效。
- 进入/usr/local/hive/conf目录,这个目录下存在的文件都是模板,需要复制和改名,要修改的如下
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
cp hive-log4j2.properties.template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
- 在hdfs目录下建立三个文件,用来存放hive信息,并赋予777权限
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user/hive/warehouse
hadoop fs -chmod 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/log
- 修改hive-env.sh文件
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export HIVE_CONF_DIR=/usr/local/hive/conf
- 在hive-site.xml文件中
字段的配置:
<property>
<name>hive.exec.scratchdir</name>
<value>/usr/local/hive/tmp</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.exec.script.wrapper</name>
<value/>
<description/>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
注意!! hive.exec.script.wrapper需要在数据库相关配置之后。
- 创建/usr/local/hive/tmp文件夹
sudo mkdir /usr/local/hive/tmp
然后在配置文件hive-site.xml中,把所有的${system:java.io.tmpdir} 都替换为/usr/local/hive/tmp,把所有的${system:user.name}替换为root
8. 配置jdbc的驱动
下载mysql-connector-java-5.1.46-bin.jar 包(也可以在下载页面,选择Looking for previous GA versions?去找想要的版本),复制放到/usr/local/hive/lib目录下就可以了
9. 初始化hive,在hive2.0以后的版本,初始化命令都是:
schematool -dbType mysql -initSchema
在Hive中创建数据库和表
进入Shell命令提示符状态。因为需要借助于MySQL保存Hive的元数据,所以,请首先启动MySQL数据库:
service mysql start #可以在Linux的任何目录下执行该命令
由于Hive是基于Hadoop的数据仓库,使用HiveQL语言撰写的查询语句,最终都会被Hive自动解析成MapReduce任务由Hadoop去具体执行,因此,需要启动Hadoop,然后再启动Hive。
然后执行以下命令启动Hadoop:
cd /usr/local/hadoop
./sbin/start-all.sh
cd /usr/local/hive
./bin/hive #由于已经配置了path环境变量,这里也可以直接使用hive,不加路径 我这里用了一次 ,似乎后面spark操作需要启动后面这个服务 bin/hive --service metastore &
通过上述过程,我们就完成了MySQL、Hadoop和Hive三者的启动。
下面我们进入Hive,新建一个数据库sparktest,并在这个数据库下面创建一个表student,并录入两条数据。
下面操作请在Hive命令提示符下操作:
hive> create database if not exists sparktest;//创建数据库sparktest
hive> show databases; //显示一下是否创建出了sparktest数据库
//下面在数据库sparktest中创建一个表student
hive> create table if not exists sparktest.student(
> id int,
> name string,
> gender string,
> age int);
hive> use sparktest; //切换到sparktest
hive> show tables; //显示sparktest数据库下面有哪些表
hive> insert into student values(1,'Xueqian','F',23); //插入一条记录
hive> insert into student values(2,'Weiliang','M',24); //再插入一条记录
hive> select * from student; //显示student表中的记录
通过上面操作,我们就在Hive中创建了sparktest.student表,这个表有两条数据。
连接Hive读写数据
现在我们看如何使用Spark读写Hive中的数据。注意,操作到这里之前,你一定已经按照前面的各个操作步骤,启动了Hadoop、Hive、MySQL和spark-shell(包含Hive支持)。
在启动之前,我们需要做一些准备工作,我们需要修改“/usr/local/sparkwithhive/conf/spark-env.sh”这个配置文件:
cd /usr/local/spark/spark-2.3.0-bin-hadoop2.7/conf
vim spark-env.sh
这样就使用vim编辑器打开了spark-env.sh这个文件,这文件里面以前可能包含一些配置信息,全部删除,然后输入下面内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SCALA_HOME=/usr/local/scala/scala-2.10.7
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib
export HIVE_CONF_DIR=/usr/local/hive/conf
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/usr/local/hive/lib/mysql-connector-java-5.1.46-bin.jar
保存spark-env.sh这个文件,退出vim编辑器。
为了让Spark能够访问Hive,需要把Hive的配置文件hive-site.xml拷贝到Spark的conf目录下,请在Shell命令提示符状态下操作:
cp /usr/local/hive/conf/hive-site.xml /usr/local/spark/spark-2.3.0-bin-hadoop2.7/conf
把连接用的jar文件拷贝到指定位置
cp mysql-connector-java-5.1.46-bin.jar /usr/local/spark/spark-2.3.0-bin-hadoop2.7/jars/
好了,经过了前面如此漫长的准备过程,现在终于可以启动spark-shell,编写调试Spark连接Hive读写数据的代码了。
下面,请在spark-shell(包含Hive支持)中执行以下命令从Hive中读取数据:
Scala> import org.apache.spark.sql.Row
Scala> import org.apache.spark.sql.SparkSession
Scala> case class Record(key: Int, value: String)
// warehouseLocation points to the default location for managed databases and tables
Scala> val warehouseLocation = "spark-warehouse"
Scala> val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate()
Scala> import spark.implicits._
Scala> import spark.sql
//下面是运行结果
scala> sql("SELECT * FROM sparktest.student").show()
+---+--------+------+---+
| id| name|gender|age|
+---+--------+------+---+
| 1| Xueqian| F| 23|
| 2|Weiliang| M| 24|
+---+--------+------+---+
启动后就进入了hive命令提示符状态,然后输入如下命令查看sparktest.student表中的数据:
hive> use sparktest;
OK
Time taken: 0.016 seconds
hive> select * from student;
OK
1 Xueqian F 23
2 Weiliang M 24
Time taken: 0.05 seconds, Fetched: 2 row(s)
下面,我们编写程序向Hive数据库的sparktest.student表中插入两条数据,请切换到spark-shell(含Hive支持)终端窗口,输入以下命令:
scala> import java.util.Properties
scala> import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
//下面我们设置两条数据表示两个学生信息
scala> val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26","4 Guanhua M 27")).map(_.split(" "))
//下面要设置模式信息
scala> val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age", IntegerType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
scala> val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
scala> val studentDF = spark.createDataFrame(rowRDD, schema)
//查看studentDF
scala> studentDF.show()
+---+---------+------+---+
| id| name|gender|age|
+---+---------+------+---+
| 3|Rongcheng| M| 26|
| 4| Guanhua| M| 27|
+---+---------+------+---+
//下面注册临时表
scala> studentDF.registerTempTable("tempTable")
scala> sql("insert into sparktest.student select * from tempTable")
然后,请切换到刚才的hive终端窗口,输入以下命令查看Hive数据库内容的变化:
hive> select * from student;
OK
1 Xueqian F 23
2 Weiliang M 24
3 Rongcheng M 26
4 Guanhua M 27
Time taken: 0.049 seconds, Fetched: 4 row(s)