1)Java 中能创建 volatile 数组吗?
能,Java 中可以创建 volatile 类型数组,不过只是一个指向数组的引用,而不是整个数组。我的意思是,如果改变引用指向的数组,将会受到 volatile 的保护,但是如果多个线程同时改变数组的元素,volatile 标示符就不能起到之前的保护作用了。
2)volatile 能使得一个非原子操作变成原子操作吗?
一个典型的例子是在类中有一个 long 类型的成员变量。如果你知道该成员变量会被多个线程访问,如计数器、价格等,你最好是将其设置为 volatile。为什么?因为 Java 中读取 long 类型变量不是原子的,需要分成两步,如果一个线程正在修改该 long 变量的值,另一个线程可能只能看到该值的一半(前 32 位)。但是对一个 volatile 型的 long 或 double 变量的读写是原子。
3)volatile 修饰符的有过什么实践?
一种实践是用 volatile 修饰 long 和 double 变量,使其能按原子类型来读写。double 和 long 都是64位宽,因此对这两种类型的读是分为两部分的,第一次读取第一个 32 位,然后再读剩下的 32 位,这个过程不是原子的,但 Java 中 volatile 型的 long 或 double 变量的读写是原子的。volatile 修复符的另一个作用是提供内存屏障(memory barrier),例如在分布式框架中的应用。简单的说,就是当你写一个 volatile 变量之前,Java 内存模型会插入一个写屏障(write barrier),读一个 volatile 变量之前,会插入一个读屏障(read barrier)。意思就是说,在你写一个 volatile域时,能保证任何线程都能看到你写的值,同时,在写之前,也能保证任何数值的更新对所有线程是可见的,因为内存屏障会将其他所有写的值更新到缓存。
4)volatile 类型变量提供什么保证?
volatile 变量提供顺序和可见性保证,例如,JVM 或者 JIT为了获得更好的性能会对语句重排序,但是 volatile 类型变量即使在没有同步块的情况下赋值也不会与其他语句重排序。 volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。某些情况下,volatile 还能提供原子性,如读 64 位数据类型,像 long 和 double 都不是原子的,但 volatile 类型的 double 和 long 就是原子的。
5) 10 个线程和 2 个线程的同步代码,哪个更容易写?
从写代码的角度来说,两者的复杂度是相同的,因为同步代码与线程数量是相互独立的。但是同步策略的选择依赖于线程的数量,因为越多的线程意味着更大的竞争,所以你需要利用同步技术,如锁分离,这要求更复杂的代码和专业知识。
6)你是如何调用 wait()方法的?使用 if 块还是循环?为什么?
wait() 方法应该在循环调用,因为当线程获取到 CPU 开始执行的时候,其他条件可能还没有满足,所以在处理前,循环检测条件是否满足会更好。下面是一段标准的使用 wait 和 notify 方法的代码:
// The standard idiom for using the wait method
synchronized (obj) {
while (condition does not hold)
obj.wait(); // (Releases lock, and reacquires on wakeup)
... // Perform action appropriate to condition
}
7)Java 中 sleep 方法和 wait 方法的区别?(答案)
虽然两者都是用来暂停当前运行的线程,但是 sleep() 实际上只是短暂停顿,因为它不会释放锁,而 wait() 意味着条件等待,这就是为什么该方法要释放锁,因为只有这样,其他等待的线程才能在满足条件时获取到该锁。
8)什么是不可变对象(immutable object)?Java 中怎么创建一个不可变对象?
不可变对象指对象一旦被创建,状态就不能再改变。任何修改都会创建一个新的对象,如 String、Integer及其它包装类。详情参见答案,一步一步指导你在 Java 中创建一个不可变的类。
9)我们能创建一个包含可变对象的不可变对象吗?
是的,我们是可以创建一个包含可变对象的不可变对象的,你只需要谨慎一点,不要共享可变对象的引用就可以了,如果需要变化时,就返回原对象的一个拷贝。最常见的例子就是对象中包含一个日期对象的引用。
10)在多线程环境中使用HashMap有什么问题?
HashMap 在并发时可能出现的问题主要是两方面,首先如果多个线程同时使用put方法添加元素,而且假设正好存在两个 put 的 key 发生了碰撞(根据 hash 值计算的 bucket 一样),那么根据 HashMap 的实现,这两个 key 会添加到数组的同一个位置,这样最终就会发生其中一个线程的 put 的数据被覆盖。第二就是如果多个线程同时检测到元素个数超过数组大小* loadFactor ,这样就会发生多个线程同时对 Node 数组进行扩容,都在重新计算元素位置以及复制数据,但是最终只有一个线程扩容后的数组会赋给 table,也就是说其他线程的都会丢失,并且各自线程 put 的数据也丢失。
关于 HashMap 线程不安全这一点,《Java并发编程的艺术》一书中是这样说的:
HashMap 在并发执行 put 操作时会引起死循环,导致 CPU 利用率接近100%。因为多线程会导致 HashMap 的 Node 链表形成环形数据结构,一旦形成环形数据结构,Node 的 next 节点永远不为空,就会在获取 Node 时产生死循环。
多线程环境下应该使用:Hashtable或者ConcurrentHashMap
> HashMap 在 new 后并不会立即分配bucket数组,而是第一次 put 时初始化,类似 ArrayList 在第一次add时分配空间。
> HashMap 的 bucket 数组大小一定是2的幂,如果 new 的时候指定了容量且不是2的幂,实际容量会是最接近(大于)指定容量的2的幂,比如 new HashMap<>(19),比19大且最接近的2的幂是32,实际容量就是32。
> HashMap 在 put 的元素数量大于 Capacity * LoadFactor(默认16 * 0.75) 之后会进行扩容。
> JDK8在哈希碰撞的链表长度达到TREEIFY_THRESHOLD(默认8)后,会把该链表转变成树结构,提高了性能。
> JDK8在 resize 的时候,通过巧妙的设计,减少了 rehash 的性能消耗。
> JDK7 中的 HashMap 还是采用大家所熟悉的数组+链表的结构来存储数据。
> JDK8 中的 HashMap 采用了数组+链表或树的结构来存储数据。
11)多重继承会带来哪些问题?
混淆。比如B和C继承于A,然后B和C分别覆盖(override)了A中的同一个方法。最后,D又分别继承于B和C,那D到底该使用B和C中的哪一个方法呢?
12)String对象为什么被设计成不可变的?
>字符串常量池的需要
>允许String对象缓存hashcode(String对象的哈希码被频繁地使用, 比如在hashMap等容器中。)
>安全性
13)HashTable和ConCurrentHashMap的对比
>Hashtable是对其put方法通过synchronized关键字对整个方法加锁,每执行一次put方法都会阻塞当前线程,所以当Hashtable的大小增加到一定的时候,性能会急剧下降,因为迭代时需要被锁定很长的时间。
>ConcurrentHashMap引入了分割(Segment),可以理解为把一个大的Map拆分成N个小的HashTable,在put方法中,会根据hash(paramK.hashCode())来决定具体存放进哪个Segment,如果查看Segment的put操作,我们会发现内部使用的同步机制是基于lock操作的,这样就可以对Map的一部分(Segment)进行上锁,这样影响的只是将要放入同一个Segment的元素的put操作,保证同步的时候,锁住的不是整个Map(HashTable就是这么做的),相对于HashTable提高了多线程环境下的性能,因此HashTable已经被淘汰了。
14)String.intern()方法的用法
如果类的字符串常量池中没有这个字符串,则先放到类的字符串常量池中,然后返回这个字符串的引用;如果类的字符串常量池中有这个字符串,则直接返回其引用。
使用intern()方法可以在程序运行期间动态扩充类的字符串常量池,这个方法的最大好处是可以避免创建不必要的字符串实例对象。
import java.util.Random;
public class Test {
static final int MAX = 10000;
static final String[] arr = new String[MAX];
public static void main(String[] args) {
Integer[] DB_DATA = new Integer[10];
Random random = new Random(10 * 10000);
for (int i = 0; i < DB_DATA.length; i++) {
DB_DATA[i] = random.nextInt(99 * 10000);
}
long t = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
// 这个写法不管字符串的值是否相同,都会创建1w个字符串对象
// arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length]));
// 下面这个会先看字符串常量池中是否有这个字符串,有的话直接返回引用,不用重新创建实例了。
arr[i] = String.valueOf(DB_DATA[i % DB_DATA.length]).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}
}
15)List和Set的区别
List是有序&线性地存储,可存放重复的对象;Set无序存放,不允许存放重复的对象,null值只允许存放1次。
16)ArrayList和LinkedList的区别
ArrayList内部采用的的是数据结构是数组,数组默认的capacity为10。数组里面的元素中间插入或删除时都可能会进行arraycopy操作,所以插入和删除操作性能较低(慢);但查询速度快。
LinkedList内部的数据结构是双向链表,中间插入或删除开销不大(只需要改变相邻node的pre和next引用即可),但随即查询较慢(分段遍历查询,把node的数量分成前后2部分,看索引落在哪个部分,落在哪段就在哪段遍历查询。落在前半部分则往后遍历,落在后半部分则往前遍历)。
下图是ArrayList和LinkedList的在各场景下的性能比较:
17)存取相同的数据ArrayList和LinkedList谁占的空间更大?
空间占用上,ArrayList完胜。可以参考:https://www.cnblogs.com/frankyou/p/9598439.html
18)TreeSet对存入数据有什么要求?
①不能存入null值 ②数据类型必须相同
19)常见的Set实现有哪些?
①HashSet:基于HashMap,通过HashMap的key来存放对象,HashMap的value是一个固定的object对象。可以设置这个HashMap的initialCapacity。
②TreeSet:通过传入类型的compareTo方法进行比较排序(前提是这些指定的类型实现了compareTo方法),也可以实现自己的compare方法来自定义排序。
20)class.forName()和ClassLoader.loadClass()的区别是什么?
1️⃣Class.forName(className)装载的class已经被初始化;
2️⃣ClassLoader.loadClass(className)装载的class还没有被link。
21)获取一个实例对象的Class对象的3种方式
①通过实例变量的getClass()方法
Dog dog = new Dog(); Class d = dog.getClass();
②通过类Class的静态方法forName()
try { Class dog1 = Class.forName("Dog"); } catch (ClassNotFoundException e) { e.printStackTrace(); }
③直接给出对象类文件的.class
Class dog2 = Dog.class;
22)JDK和CGLIB生成动态代理类的区别
①JDK动态代理是利用反射机制生成一个实现代理目标对象的接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
②CGLIB动态代理是利用asm开源包,把目标代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
1、如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
2、如果目标对象实现了接口,可以强制使用CGLIB实现AOP
3、如果目标对象没有实现了接口,必须采用CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换
<!--强制使用CGLIB实现代理-->
<aop:aspectj-autoproxy proxy-target-class="true"/>
动态代理在Spring中的应用主要体现在AOP上。
23)浅拷贝和深拷贝的区别
①浅拷贝:对于基本数据类型进行值传递,对引用类型进行引用拷贝。
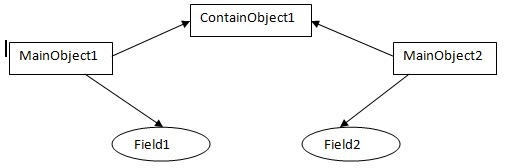
②深拷贝:对于基本数据类型进行值传递,对于引用类型先创建一个新的对象并复制其内容。

24)Class.forName和ClassLoader.loadClass的区别
Class.forName加载的类已做了初始化;ClassLoader.loadClass加载的class还没有被link。