大致的思路流程如下:
通过这样的爬取流程,可以不断递归爬去大量数。
我们以轮子哥作为选定起始人,利用Google chrome 的审查观察网页的network
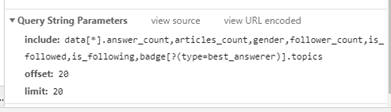



可以看出实际上我们在浏览器在获得这follower 和followee数据时,是调用了一个知乎的api.并且我们观察每个用户的数据,可以知道url_token这个参数是非常重要的,因为它标实了每个用户,我们可以用过url_token来定位这个用户。
为了获取单个用户更加详细的信息,我们把鼠标放在用户头像上
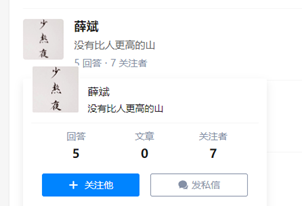
这时候network中会出现一个相对应的A-jax请求:

打开cmd,通过scrapy startproject zhihuuser 命令创建项目开始正式写代码
- 需要先把settings.py中的ROBOTSTXT_OBEY选择为false,让爬虫畅通无阻不受协议的约束,否则有些地方是访问不了的。
-
进入zhihuuser的文件夹,使用scrapy genspider zhihu www.zhihu.com创建知乎的爬虫

- 首先我们测试这个爬虫,直接在cmd中运行爬虫。运行过程中出现了卡顿,并且出现了400代号的服务器错误相应。这是因为知乎服务器有user-agent识别,于是我们修改settings.py中的DEFAULT_REQUEST_HEADERS 参数,添加上浏览器默认的user-agent

-
改修初始请求:

第一步创建了几个user_url follow_url的格式,并且添加上了他的include参数(即follow_query)
第二步是重写了start_requests,初始的用户选择轮子哥(start_usr),通过format 补全了网址,并且分别选择回调函数parse_user和parse_follows
- 创建储存数据的容器items
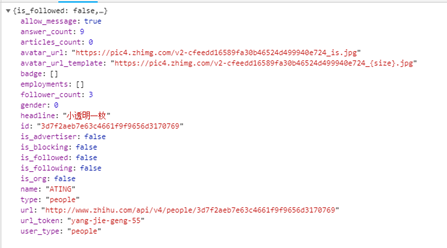

因为数据太多,我这边没有写全。
6.储存每个用户的信息。
我们在爬虫中写parse_user函数,在其中引入UserItem()对象通过item.fields属性,可以得到useritem中的fields。从而填充容器

7.对于followers和followees的Ajax请求
在Ajax请求中有两个数据块:data和paging

①对于data,我们主要需要的信息是url_token,它是某一个用户的唯一标识,通过这个标识可以构建出这个用户的主页网址。

②对于paging

paging是判断followers和followees的Ajax请求,也就是粉丝列表是否已经是最后一列了。Is_end是判断是否是最后一页,next是下一页的url,这两个数据是我们需要的。
首先判断是否有paging,当is_end是false的时候获取到下一页的followes和folloee列表的网址,然后yield Request

8.把用户信息存到Mongodb中,即改写pipeline
Scrapy官方文档有mongodb的代码,直接复制
为了去重,需要修改一条代码:
当然还需要在settings.py中修改设置参数


最后运行代码


代码 :
爬虫代码(zhihu.py):
# -*- coding: utf-8 -*- import json import scrapy from scrapy import Request, Spider from zhihuuser.items import UserItem class ZhihuSpider(scrapy.Spider): name = 'zhihu' allowed_domains = ['www.zhihu.com'] start_user = 'excited-vczh' user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}' user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics' follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}' follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followers?include={include}&offset={offset}&limit={limit}' followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' def start_requests(self): yield Request(self.user_url.format(user=self.start_user, include=self.user_query), self.parse_user) yield Request(self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20), self.parse_follows) yield Request(self.followers_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20), self.parse_followers) def parse_user(self, response): result = json.loads(response.text) item = UserItem() # 声明一个item对象的引用 for field in item.fields: if field in result.keys(): item[field] = result.get(field) yield item # 获取关注列表 followees yield Request( self.follows_url.format(user=result.get('url_token'), include=self.follows_query, limit=20, offset=0), callback=self.parse_user) # 获取粉丝列表 followers yield Request( self.followers_url.format(user=result.get('url_token'), include=self.followers_query, limit=20, offset=0), callback=self.parse_user) def parse_follows(self, response): results = json.loads(response.text) if 'data' in results.keys(): for result in results.get('data'): yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parse_user) if 'paging' in results.keys() and results.get('paging').get('is_end') == False: next_page = results.get('paging').get('next') yield Request(next_page, callback=self.parse_follows) def parse_followers(self, response): results = json.loads(response.text) if 'data' in results.keys(): for result in results.get('data'): yield Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parse_user) if 'paging' in results.keys() and results.get('paging').get('is_end') == False: next_page = results.get('paging').get('next') yield Request(next_page, callback=self.parse_followers)
pipeline代码:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo from scrapy import item class MongoPipeline(object): collection_name = 'scrapy_items' def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): try: self.db['user'].update({'url_token': item['url_token']},{'$set':item}, True) #第一个参数是一个去重的条件 #第二个参数是传入一个item变量, 第三个True表示如果找到就会执行更新,else执行插入 except: pass return item
items.py:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy import Field as f class UserItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() id = f() name = f() employments = f() name = f() url_token = f() follower_count = f() url = f() answer_count = f() headline = f()