首先进入博客园的管理页面:
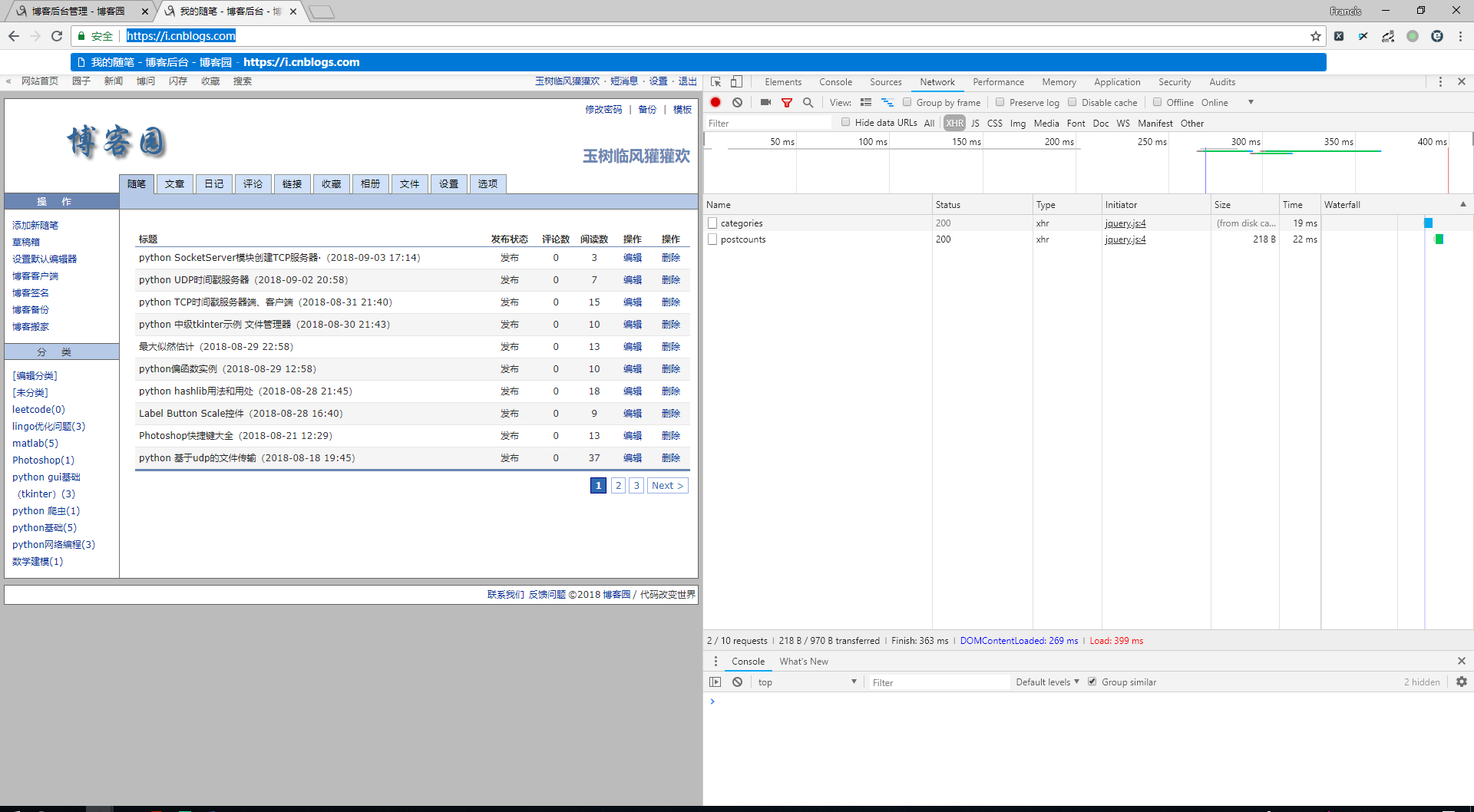
通过观察A-JAX请求,发现博客的分类(categories)是一个json格式的数据即:
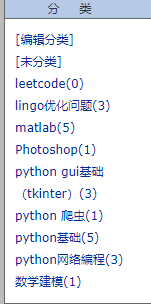

于是先爬取categories。通过各个分类的页面进而爬去地址,浏览量,打开一个category的页面: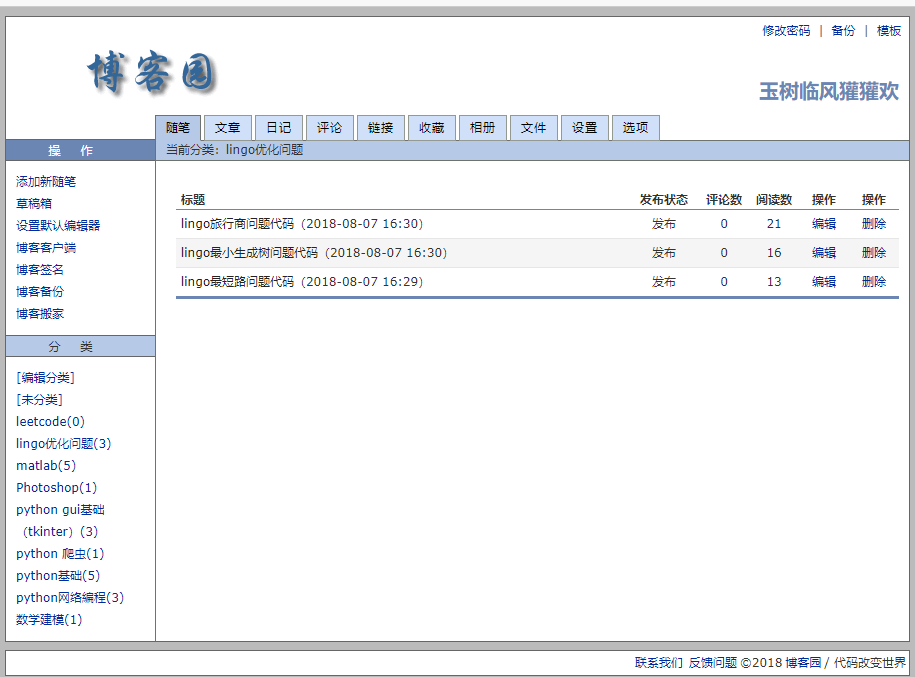
检查网页


这样就得到了每个博客的地址和浏览量了
上代码,其他一些问题在代码中给出注释:
import time import requests import json import re from selenium import webdriver url = 'https://i.cnblogs.com/categories' base_url = 'https://i.cnblogs.com/posts?' views = 0 url_list = [] headers = { #在headers中添加上自己的cookie 'cookie': '你自己的cookie','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', 'upgrade-insecure-requests': '1' } pattern1 = re.compile('<td>发布</td>.*?d.*?(d{1,})', re.S) #正则表达式 #这边尤其要注意到浏览量有可能不只是一个位数,还可能是二位数三位数,所以写正则的时候应该是(d{1,}) pattern2 = re.compile('<td class="post-title"><a href="(.*?)"', re.S) #正则表达式 response = requests.get(url=url, headers=headers) html = response.text data = json.loads(html) #通过json.loads把数据转化成字典格式 categories = (i['CategoryId'] for i in data) for category in categories: cate_url = base_url + 'categoryid=' + str(category) #build每个category的地址 headers['referer'] = cate_url response = requests.get(cate_url, headers=headers) html = response.text results1 = re.findall(pattern1, html) #浏览量的findall结果 results2 = re.findall(pattern2, html) #网页地址的findall结果 if results1: for result1 in results1: views = views + int(result1) #通过int()内置函数,把string格式的数字转化为int格式的数值,计算浏览量 for result2 in results2: url_list.append('https://' + result2) #build地址 print('总浏览量为:', views) print(url_list) options = webdriver.ChromeOptions() #通过selenium 模块中的webdriver 模拟一个chrome浏览器 #设置中文 options.add_argument('lang=zh_CN.UTF-8') #更换头部 options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"') #https://www.cnblogs.com/francischeng/p/9437809.html #www.cnblogs.com/francischeng/p/9437809.com' driver = webdriver.Chrome(chrome_options=options) while True: for url in url_list: driver.delete_all_cookies() driver.get(url) time.sleep(2) #睡眠两秒
总结。
1.主要遇到的错误是,正则表达式中爬取浏览量的问题,刚开始只写了(d),也就是一个数字。然而浏览量可能是二位数三位数,所以应该改成(d{1,})这样可以爬取多位的数字。
2.通过单纯的模拟浏览器并不能刷浏览量,可能一个ip一天只能增加几个浏览量
3 因为每个ip只能刷固定的浏览量,所以想用代理池得到ip无限刷浏览量