反射
1.什么是反射
其实是反省,自省的意思
反射指的是一个对象应该具备,可以检测,修改,增加自身属性的能力
反射就是通过字符串操作属性
涉及四个函数(hasattr、getattr、setattr、delattr),这四个函数就是普通的内置函数,没有双下划线,与print等等没有区别
2.hasattr、getattr、setattr、delattr
class Person: def __init__(self,name,age,gender): self.name = name self.age = age self.gender = gender p = Person("jack",18,"man") print(hasattr(p,"name")) # 判断某个对象是否存在某个属性 if hasattr(p,"name"): # 判断某个对象是否存在某个属性 print(getattr(p,"name",None)) # 从对象中取出属性 print(getattr(p,"hobby",None)) # 第三个值为默认值,当属性不存在时返回默认值 # 为对象添加新的属性 setattr(p,"id","123") print(p.id) # 从对象中删除属性 delattr(p,"id") print(p.id)
3.使用场景
反射其实就是对属性的增删改查,但是如果直接使用内置的__dict__来操作,语法繁琐,不好理解
另外一个最主要的问题是,如果对象不是我自己写的,而是另一方提供的,我就必须判断这个对象是否满足我的要求,也就是是否具备我需要的属性和方法
4.框架设计方式
反射被称为框架的基石,为什么?
因为框架的设计者,不可能提前知道你的对象到底是怎么设计的
所以你提供给框架的对象,必须通过判断验证之后才能正常使用,判断验证就是反射要做的事情
当然通过__dict__也是可以实现的, 其实这些方法也就是对__dict__的操作进行了封装


""" 需求:要实现一个用于处理用户的终端指令的小框架 框架就是已经实现了最基础的构架,就是所有项目都一样的部分 """ import plugins # 导入插件所在文件 # 框架已经实现的部分 def run(plugin): while True: cmd = input("请输入指令:") if cmd == "exit": break # 因为无法确定框架使用者是否传入正确的对象所以需要使用反射来检测 # 判断对象是否具备处理这个指令的方法 if hasattr(plugin,cmd): # 取出对应方法方法 func = getattr(plugin,cmd) func() # 执行方法处理指令 else: print("该指令不受支持...") print("see you la la!") # 创建一个插件对象 调用框架来使用它 # wincmd = plugins.WinCMD() # 框架之外的部分就由自定义对象来完成 linux = plugins.LinuxCMD() run(linux) # 插件部分: class WinCMD: def cd(self): print("wincmd 切换目录....") def delete(self): print("wincmd 要不要删库跑路?") def dir(self): print("wincmd 列出所有文件....") class LinuxCMD: def cd(self): print("Linuxcmd 切换目录....") def rm(self): print("Linuxcmd 要不要删库跑路?") def ls(self): print("Linuxcmd 列出所有文件....")
5.动态导入
上述框架代码中,写死了必须使用某个类,这是不合理的,因为无法提前知道对方的类在什么地方,以及类叫什么
所以我们应该为框架的使用者提供一个配置文件,要求对方将类的信息写入配置文件
然后框架自己去加载需要的模块
# 最后的框架代码: import importlib import settings # 框架已经实现的部分 def run(plugin): while True: cmd = input("请输入指令:") if cmd == "exit": break # 因为无法确定框架使用者是否传入正确的对象所以需要使用反射来检测 # 判断对象是否具备处理这个指令的方法 if hasattr(plugin,cmd): # 取出对应方法方法 func = getattr(plugin,cmd) func() # 执行方法处理指令 else: print("该指令不受支持...") print("see you la la!") # 创建一个插件对象 调用框架来使用它 # wincmd = plugins.WinCMD() # 框架之外的部分就由自定义对象来完成 # 框架得根据配置文件拿到需要的类 path = settings.CLASS_PATH # 从配置中单独拿出来 模块路径和 类名称 module_path,class_name = path.rsplit(".",1) #拿到模块 mk = importlib.import_module(module_path) # 拿到类 cls = getattr(mk,class_name) # 实例化对象 obj = cls() #调用框架 run(obj)
如此一来,框架就与实现代码彻底解耦了,只剩下配置文件
元类
1.元类是什么
用于创建类的类
万物皆对象,类当然也是对象
对象是通过类实例化产生的,如果类也是对象的话,必然类对象也是由另一个类实例化产生的
默认情况下所有类的元类都是type
class Person: pass p = Person() print(type(p)) print(type(Person)) # Person类是通过type类实例化产生的
2.一个类的三个基本组成部分
(1)类的名字(字符类型)
(2)类的父类们 (是一个元组或列表)
(3)类的名称空间(字典类型)
# 生成一个类 cls_obj = type("dog",(),{}) # 三个参数对应类的三个基本组成部分 print(cls_obj) # 等价于 class dog: pass
3.学习元类的目的
高度的自定义一个类
例如:控制类的名字必须以大驼峰的方式来书写,元类中的__init__方法
''' 类也是对象,也有自己的类 我们的需求是创建类对象并做一些限制 想到了初始化方法,我们只要找到类对象的类(元类),覆盖其中__init__方法就能实现需求 当然我们不能修改源代码,所以应该继承type来编写自己的元类,同时覆盖__init__来完成需求 ''' # 定义了一个元类,只要继承了type,那么这个类就变成了一个元类 class MyType(type): def __init__(self,clss_name,bases,dict): super().__init__(clss_name,bases,dict) print(clss_name,bases,dict) if not clss_name.istitle(): raise Exception("你丫的,类名不会写吗...") # 为pig类指定了元类为MyType class Pig(metaclass=MyType): # 指定元类的方法 pass class duck(metaclass=MyType): # 类名不遵守大驼峰书写就报错,无法创建 pass
元类中的__call__方法
1.执行时机
当你调用类对象时会自动执行元类中的__call__方法 ,并将这个类本身作为第一个参数传入,以及后面的一堆参数
覆盖元类中的__call__之后,这个类就无法产生对象了,必须调用super().__call__来完成对象的创建,并返回其返回值
2.使用场景
当你想要控制对象的创建过程时,就覆盖__call方法
当你想要控制类的创建过程时,就覆盖__init__方法
3.实现将对象的所有属性名称转为大写
class MyType(type): def __call__(self, *args, **kwargs): new_args = [] for a in args: new_args.append(a.upper()) print(new_args) return super().__call__(*new_args,**kwargs) class Person(metaclass=MyType): def __init__(self,name,gender): self.name = name self.gender = gender p = Person("jack","woman") print(p.name) print(p.gender) # 注意:一旦覆盖了__call__必须调用父类的__call__方法来产生对象并返回这个对象
补充__new__方法
1.执行时机
当你要创建类对象时,会首先执行元类中的__new__方法,拿到一个空对象,然后会自动调用__init__来对这个类进行初始化操作
注意:如果你覆盖了该方法,则必须保证__new__方法必须有返回值,且必须是对应的类对象
2.测试
class Meta(type): def __new__(cls, *args, **kwargs): print(cls) # 元类自己 print(args) # 创建类需要的几个参数 类名,基类,名称空间 print(kwargs) #空的 print("new run") obj = type.__new__(cls,*args,**kwargs) return obj def __init__(self,a,b,c): super().__init__(a,b,c) print("init run") class A(metaclass=Meta): pass print(A)
总结:
__new__方法和__init__都可以实现控制类的创建过程,__init__更简单
单例设计模式
1.什么叫设计模式
用于解决某种固定问题的套路
例如:MVC、MTV等
2.单例
指的是一个类只能产生一个对象
为什么要使用单例:单例是为了节省资源,当一个类的所有对象属性全部相同时,则没有必要创建多个对象
class Single(type): def __call__(self, *args, **kwargs): if hasattr(self,"obj"): #判断是否存在已经有的对象 return getattr(self,"obj") # 有就返回 obj = super().__call__(*args,**kwargs) # 没有则创建 print("new 了") self.obj = obj # 并存入类中 return obj class Student(metaclass=Single): def __init__(self,name): self.name = name class Person(metaclass=Single): pass stu = Student('jack') print(stu.name) stu = Student('jack') # 只会创建一个对象 Person() Person()
项目生命周期
1.需求分析
明确用户需求,用户到底需要什么样的程序,要实现什么样的功能,很多时候,用户都是在意淫,逻辑上是不正确的,所以需要工程师,与用户当面沟通以确定用户的真实需求,以及需求的可实现性,并根据最终的需求,产生项目需求分析书
2.技术选型
我们需要根据公司的实际情况考虑采用的框架技术,通常要做的业务业界用主流的实现方案,例如各种框架的版本,要考虑兼容性,流行程度,以及工程师的熟练程度
3.项目设计
由于项目不可能一次开发完就完事了,后期需要维护扩展,所以良好的架构设计对后续的维护扩展有重要意义
另外如果你的思路从一开始就不正确,那后期很有可能把整个项目推翻重写
项目的设计当然是越早越好,但是学习阶段,直接按照某种架构来编写,你会觉得非常抽象,为什么要这么设计,好处是什么?会造成一种感觉是,还没开始写代码就已经懵逼了 所以要先明确不进行设计前存在的问题,然后在找相应的解决方案
4.项目开发
项目开发其实是耗时相对较短的一个阶段,前提是需求已经明确,项目设计没有问题,然后根据需求分析书进行代码编写,公司一般都有多个工程师,项目经理负责分配任务,每个工程师开发完自己的模块后提交自己的代码,最后所有代码合并到一起,项目开发完成
5.项目测试
开发完成并不意味着工作结束了,需要将完整的项目交个测试工程师,一些小公司可能没有这个岗位,那就需要开发工程师自己完成测试
6.上线运行
在测试通过后项目就可以上线运行了,上线运行指的是是你的程序能够真正的运行在互联网上,在开发项目阶段一般使用的都是局域网环境,普通用户是无法访问的,需要将项目部署到服务器上,再为服务器获取一个公网ip,并给这个ip绑定域名,至此项目即正常运行了
7.维护更新
后续都需要增加新功能或是修改各种bug,不断地完善项目,进行版本的更新迭代,当然如果公司不幸倒闭了,那么这个项目的生命周期也就结束了
经典三层结构
所有应用程序本质上都是在帮用户处理数据
三层结构:将应用程序分为三层,为了达到高内聚低耦合的目的
1.用户视图层
现在流行前后端分离的设计方式,用户视图层,可能是一个手机APP,可能是浏览器,可能是PC端程序,他们的主要职责是与用户交互,收集用户数据,展示数据给用户,在目前的项目中,python的控制台就是我们的视图
2.业务逻辑层
主要负责接收视图层获取到的数据,并进行判断,验证,处理
3.数据访问层
负责将业务逻辑层处理后的数据存储到文件系统中,同时负责将文件系统中的数据读取到内存,简单的说 负责数据的读写
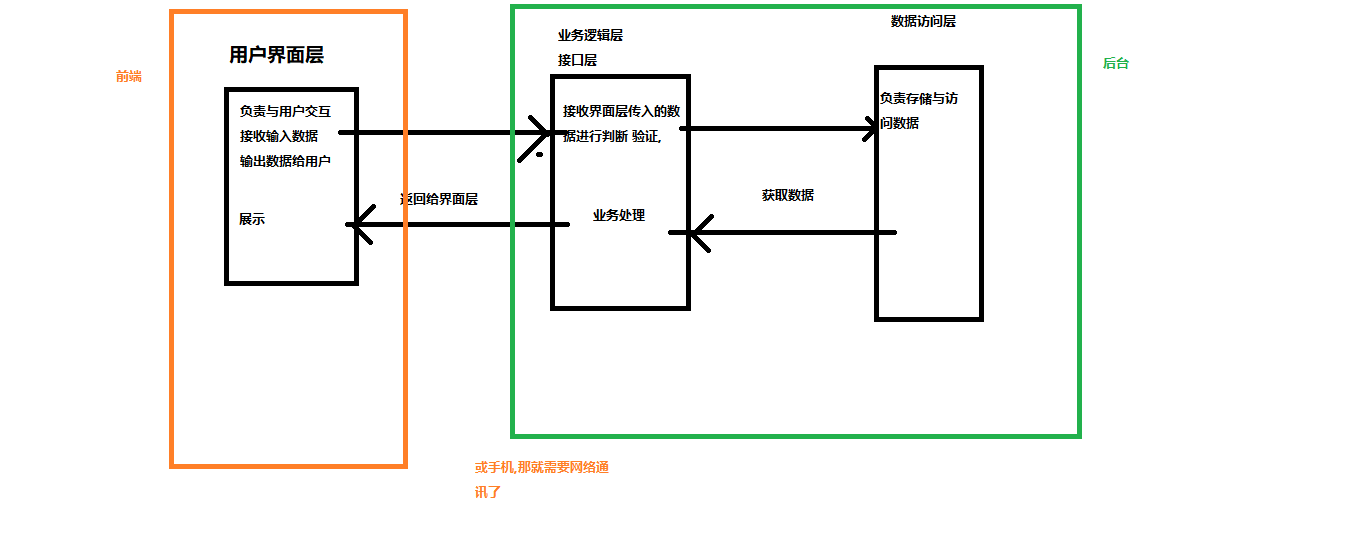
注意:
用户视图层与数据访问层不应直接通讯
当然我们不分任何层级也是可以的,你会发现这么做的问题是:代码结构混乱,可读性差,从而导致维护性差,扩展性差等问题
冒泡排序
""" 冒泡排序 从大到小 第一圈: [2,1,3,5] # 给列表里的元素从大到小排序 第一次 得出2的位置 [2,1,3,5] 第二次 [2,3,1,5] 第三次 [2,3,5,1] 次数为 元素个数 - 1 - (圈数索引为0) 第二圈: [2,3,5,1] 第一次 [3,2,5,1] 第二次 [3,5,2,1] 次数为 元素个数 - 1 - (圈数索引为1) 第三圈: [3,5,2,1] 第一次 [5,3,2,1] 次数为 元素个数 - 1 - (圈数索引为2) 总结规律 圈数 是元素个数减一 次数 元素个数 - 1 - (圈数索引) 我们需要两层循环 一层控制圈数 一层控制次数 """ ls = [2,1,3,5] for i in range(len(ls)-1): for j in range(len(ls)-1-i): # 如果前面的小于后面的则交换位置 if ls[j] < ls[j+1]: ls[j],ls[j+1] = ls[j+1],ls[j] print(ls)