一个爬取网易国内今日热点新闻的小脚本。
需要用到requests、BeautifulSoup、Pandas(用于处理数据和导出Excel)
网易国内新闻url:http://news.163.com/domestic/
get url获得response,requests对象,BeautifulSoup提取出对象。
1 # -*- coding: utf-8 -*- 2 import requests 3 from bs4 import BeautifulSoup 4 import pandas #最后整理数据、导出Excel时会用到。 5 6 urllist = 'http://news.163.com/domestic/' 7 res = requests.get(urllist) 8 print(res.encoding) 9 soup = BeautifulSoup(res.text,'html.parser') 10 print(type(soup)) 11 print(type(res))
一开始,也试着res.encoding = 'utf-8’,但是发现会导致中文字符乱码,后面也就没改了。
打印出res的编码类型,以及soup和res的对象类型。

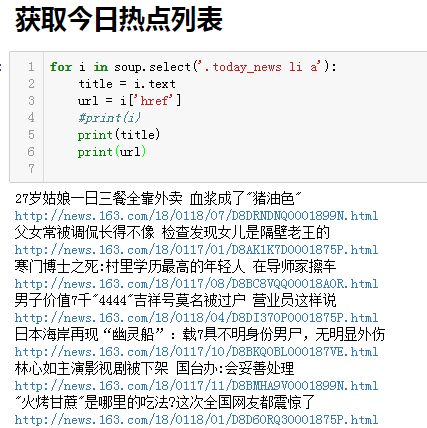
从这个soup中可以获得今日热点新闻的title和url,查询标签后,使用select('.today_news li a')得到:
1 for i in soup.select('.today_news li a'): 2 title = i.text 3 url = i['href'] 4 #print(i) 5 print(title) 6 print(url)
结果是这样的:
接下来就是获取文章内文的内容、时间、来源、以及编辑
1 newsurl = 'http://news.163.com/18/0117/01/D8AK1K7D0001875P.html' 2 response = requests.get(newsurl) 3 soup = BeautifulSoup(response.text,'html.parser') 4 title = soup.select('.post_content_main h1')[0].text 5 article = [] 6 for p in soup.select('.post_text p'): 7 article.append(p.text.strip()) 8 s = soup.select('.post_time_source')[0].text.strip()#时间来源等在class=post_time_source 9 time = s.split('u3000来源')[0]#将s分片,分别取得时间、来源 10 news_source = s.split('u3000来源:')[1] 11 editor = soup.select('.ep-editor')[0].text.split(':')[1]#以:(冒号)来分片,取得编辑名称
已编辑来举例,select得到的是一个这样的数据,一个list,里面有标签等等信息。

所以需要对他进行处理才能得到想要的数据。

到这里主要的就基本没了,将列表里的URL分别传入第二段代码就可以获得想要的信息。
但是会很乱,下面再整理一下,把他们搞成函数,就清晰多了。
首先是获取文章具体内容的:
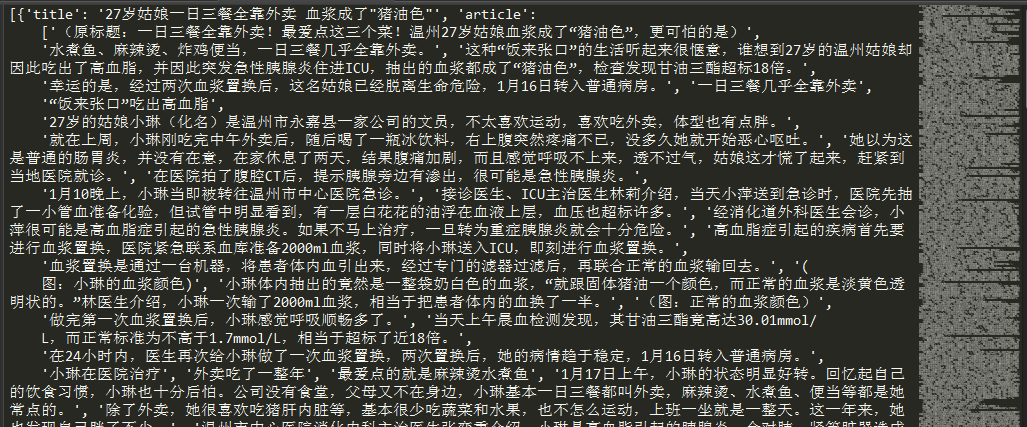
def getNewsDetail(url): result = {} response = requests.get(url) soup = BeautifulSoup(response.text,'html.parser') result['title'] = soup.select('.post_content_main h1')[0].text s = soup.select('.post_time_source')[0].text.strip()#时间来源等在class=post_time_source result['news_source'] = s.split('u3000来源:')[1] result['time'] = s.split('u3000来源')[0]#将s分片,分别取得时间、来源 article = [] for p in soup.select('.post_text p'): article.append(p.text.strip()) result['article'] = article result['editor'] = soup.select('.ep-editor')[0].text.split(':')[1]#以:(冒号)来分片,取得编辑名称 return result
传入一个URL尝试一下。http://news.163.com/18/0117/01/D8AK1K7D0001875P.html

得到了想要的信息,隔壁老王很厉害。
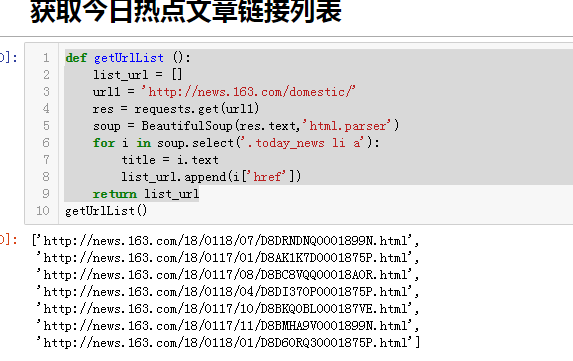
其次就是获取今日热点新闻的链接列表了。
1 def getUrlList (): 2 list_url = [] 3 url1 = 'http://news.163.com/domestic/' 4 res = requests.get(url1) 5 soup = BeautifulSoup(res.text,'html.parser') 6 for i in soup.select('.today_news li a'): 7 title = i.text 8 list_url.append(i['href']) 9 return list_url
执行试下:
最后,来个启动函数start(),把这个url列表传入 getNewsDetail():
1 def start (): 2 news_details = [] 3 for i in getUrlList(): 4 news_details.append(getNewsDetail(i))#将列表中的url分别传入getNewsDetail() 5 return news_details 6 print(start())
输入start(),就可以执行了,但,得到的数据虽正确,却很难看。。。
所以,我在这里又引入了pandas模块。整理后,在jupyter运行得到这样的结果。这就清晰多了。

接下来,就是将得到的数据,导出到Excel。
1 #导出Excel文件 news 2 df = pandas.DataFrame(start()) 3 df.head(5) 4 df.to_excel('news163.xlsx') 5 print('ok')#完成后的提示。
然后查看文档路径:

打开表格:

完成。
除此以外,也可以导出html/sql等等多种文件

不过,一些时间等格式要调整,要引入datetime等模块,来处理问题。
下图是爬取新浪新闻时,生成的sqlite文件。就是这样的一个数据库。