前面介绍了两个文本检测的网络,分别为RRCNN和CTPN,接下来鄙人会介绍语义分割的一些经典网络,同样也是论文+代码实现的过程,这里记录一下自己学到的东西,首先从论文下手吧。
英文论文原文地址:https://arxiv.org/abs/1505.04597
前面的论文忘记介绍大佬的名字了,在这里先抱个歉。。。那么接下来有请提出U-Net的大佬们一一列席:Olaf Ronneberger, Philipp Fischer, and Thomas Brox
这里依次是三位大佬的主页 https://lmb.informatik.uni-freiburg.de/people/ronneber/
https://lmb.informatik.uni-freiburg.de/people/fischer/ https://lmb.informatik.uni-freiburg.de/people/brox/ 其中,有他们的论文及代码实现,感兴趣的可以进行学习实现一下。
下面进入正文,首先作者开头就提到了,通过使用数据增强可以更加高效的使用标记的样本。结构包括一个压缩路径 用于捕捉上下文信息,还有一个对称的展开路径 用于精确的定位。这种网络的特点就是可以对很少的几张图片进行end-to-end训练并且表现的较好。在医学图像上需要对每个像素进行分类,有位大佬提出了用滑动窗口的方法,通过一个patch(该像素周围)的类别对像素进行分类,要求是一是网络可以进行定位,二是patch的数量远大于训练的图片,结果还是喜人的。但接下来,作者就开始进行批斗了,首先作者认为这个做法很慢,网络必须经过每个patch,这就会因为很多重叠造成很多冗余。再就是,在定位的准确性和上下文的使用二者要进行权衡,更大的pathc需要更多的最大池化层来减少定位精度,而小的patch包含的上下文信息就较少。
然而作者想到了机智的方法可以解决上述问题,作者提出的 结构是建立在全卷积网络。作者对其进行修改和扩展,使其可以在很少的训练图像下 进行工作,同时产生更精确的分割。
网络结构如下:
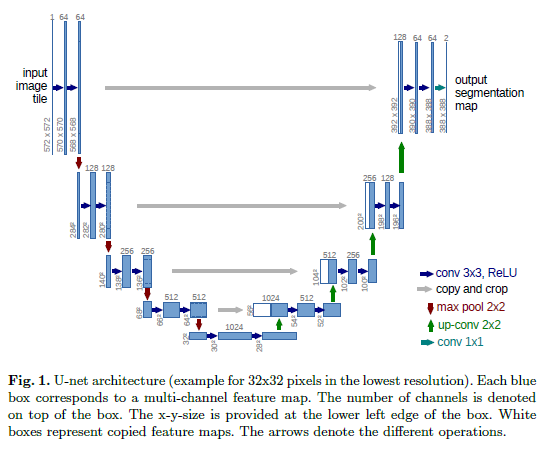
全卷积网络的主要思路是通过连续层来补充通常 的压缩网络。这里池化操作被上采样取代。这些层增加了输出的分辨率,因此,为了定位,从压缩路径中获得的高分辨率特征与上采样的输出结合。一系列卷积层会根据这些信息组合学习到更精确的输出。
作者在结构的上采样部分进行了修改,有大量特征通道,允许网络将上下文信息传播到更高分辨率的层。结构上,压缩路径与展开路径或多或少的有些对称,形成一个U形。这个U网比较奇葩,没有全连接层,而且仅使用每个卷积层的有效部分通过重叠+平铺,可以实现任意大小图片的无缝分割。为了预测图像边界区域中的像素,可以通过输入图像的镜像操作来推断遗失的上下文。前面说的这个策略很适合于大的图片。作者将训练图片进行弹性变换(个人感觉是各种图像处理的套路)来实现数据增强。
下面大体说一说网络的结构,摆在你面前的有两条路,一条为压缩路径,另一条为扩展路径,压缩路径的结构和卷积结构相同,包括两次3*3卷积,每个卷积后接一个RELU,和一个2*2的最大池化层(stride=2)用于下采样。在每个下采样的过程中,将特征通道数加倍,扩张路径中的每一步都包括上采样,然后进行2*2的反卷积,其特征通道数减半,与来自压缩路径中相对应的裁剪feature map级联,同时进行两个3*3的卷积,并捎带个RELU。由于卷积边界上像素有丢失,因此,进行裁剪是必要的。在最后一层,用大小为1*1的卷积将64维的特征向量映射到目标的类别数目上。次网络总共有23个卷积层。
Unet网络介绍到这里,这里提一下,Unet网络十分适合于生物医学上的处理,同时由于医学影像较少,因此作者进行了数据增强,使Unet能够发挥的更加出色。