
论文原址:https://arxiv.org/abs/1811.07275
摘要
一个训练好的网络模型由于其模型捕捉的特征中存在大量的重叠,可以在不过多的降低其性能的条件下进行压缩剪枝。一些skip/Dense网络结构一定程度上减弱了重叠的现象,但这种做法引入了大量的计算及内存。本文从更改训练方式的角度来解决上述问题。本文发现,通过对模型进行临时裁剪,并对一定的filter进行恢复,重复操作,可以减少特征中的重叠效应,同时提高了模型的泛化能力。本文证明当前的压缩标准在语义上并不是最优的,本文引入filters间的正交性来作为等级标准并以此来决定表达能力不足的filter。本方法不仅适用于卷积网络,同样适用于更复杂的现代模型,尤其是针对小模型的应用。
介绍
卷积网络在不同的视觉任务中都表现的较为出色,归结于其独特的网络结构。尽管网络结构不同,但不同任务的优化方法是相同的。这些方法将每个权重看作是独立的个体,并对其进行单独的更新。针对特定结构的卷积训练过程被确定下来。卷积网络中的filter为基本单元。一个filter并不是单独的权重参数,而是一组空间核。
模型中存在大量的参数,因此,一个训练好的卷积网络中存在大量冗余的filter。模型压缩中对filter进行剪枝,而不是参数这点就可以看出来。大多数剪枝算法在损失一定模型性能的前提下,减少大量的filters。但是如果从头训练一个较少filter的模型,与一个训练过的大型模型经过裁剪后,二者其尺寸相似,但二者性能却不匹配,较小参数的模型性能很难与大型模型的相匹配。而标准的训练过程是通过额外可剪枝的filter进行模型学习,因此,卷积网络的训练过程仍存在较大的提升空间。
本文提出了一种训练机制,在正常训练迭代几轮后,临时丢弃一些filters。reduced后的网络经过额外的训练后,将丢弃的filters重新引入。对其以新的权重进行初始化,然后接着进行标准的训练过程。本文发现这样做可以提高模型的性能。本文发现经过一定的标准决定要丢弃哪个filter可以提高模型的性能,如果更准确的标准进行分级,还可以得到更好的性能。根据最近的理论,大型模型的性能与大量子网络的初始化决定。本文方法是保留大量有用的子网络并对作用不大的filters重新进行初始化。
本文的另一个亮点是基于一种可解释性的标准来指导filter剪枝。本文实验发现标准的参数filter剪枝技术不是最优的,本文通过引入准则来进行高效的计算同时提高模型的性能。该标准基于卷积层中filter间的正交性,其效果超过了用于网络剪枝的基于重要性分级的方法。本文观察到即使是小型网络也会有冗余filters,因此,参数冗余不仅存在于参数量较大的模型中,其主要是由于低效的训练方法产生。本文的目标是通过更改训练策略而不是网络结构来提高减少冗余的filters同时提高卷积网络的表示能力。
训练机制:许多训练方法被提出来用于防止模型过拟合同时提高模型的泛化能力。在训练深度网络时Dropout是一种常用的方法。通过随机丢弃一些神经元可以防止feature detectors之间的相互影响。相似的,一些研究通过提出概率pooling卷积网络的激活值来实现相似的dropout。一些随机训练建议随机丢弃一些层来防止极端的过拟合情况。相对的,本文使用的是线性组合的特征,而不是对特征进行复制。Dense-Sparse-Dense,一种相似的训练机制,在训练的中间阶段进行权重正则化来建立稀疏权重,然后,移除正则化来恢复dense权重。DSD主要作用于单个参数,而本文的方法是应用于整个卷积核上。
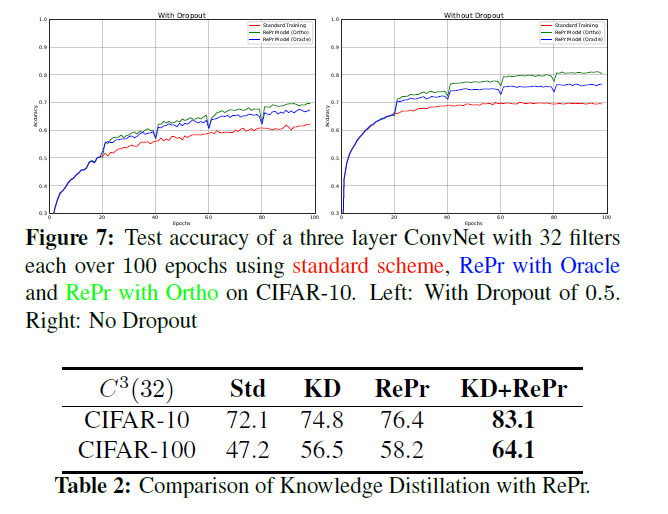
模型压缩: Knowledg Ditillation是一种训练机制,利用来自大型预训练模型(teacher)的soft logits来训练较小的模型(student)。soft logits捕获的目标物的分级信息并提供一个平滑的损失函数进行优化。使小模型更易于训练与收敛。然而,Born-Again-Network结果显示,如果一个学生模型与教师模型的体量相近,则其可以超越teacher模型。知识蒸馏的其他模型需要训练几个模型,而本文的训练机制不依赖于教师,同时,相比KD,需要的训练较少。同时,将本文的方法与KD进行结合可以得到更好的性能。
神经元分级: 寻找响应最大的权重或者神经元已经有很长时间了。LeCun等人使用具有二阶导的Hessian矩阵,其可以识别较弱的神经元,而且要比使用权重表现较好。而计算Hessian需要大量的计算资源,因此,该方法并未广泛的使用。对权重进行正则化处理可以有效的进行分级评判进而产生稀疏的模型。稀疏模型并不会加速inference,但作为神经元分级准则,其是有效的。利用激活层中的Average percentage of Zeros以及数据驱动的阈值来决定cut-off。
结构搜索: 网络结构搜索是在训练过程中模型结构发生变化,同时,对于一个给定的数据集,搜索多个网络结构从而得到一个最好的。如果网络的结构是固定的,则该方法并没有任何作用。本文对于一个给定的结构,更好的使用可利用的参数。如果在最终结构灵活变化,则可以将本文的方法与结构搜索结合使用,当由于内存等限制使网络结构固定时,该方法可以用于自身。
特征相关性: 卷积网络的一个显著缺点是其相关的feature maps,Inception-Net用于分析各个层之间特征的统计相关性。通过拼接不同尺寸filter的feature map来减少层与层之间的相关性。ResNet以及DenseNet等通过与以前的层的激活层进行相加或者拼接来减少层之间的相关性。但这种做法需要大量的计算及内存。本文的做法是在不改变网络结构的前提下引入非相关性特征。
正交特征的启发
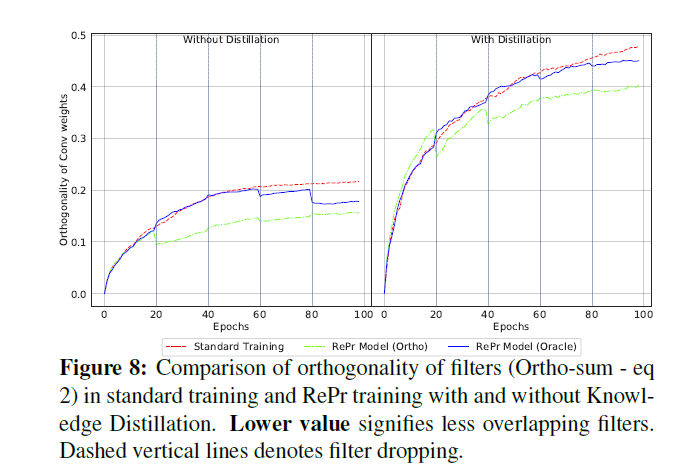
一个卷积filter中的特征定义为filter中个别filter的激活值的相加和。如果一个feature可以提高模型的泛化能力,则说明此feature是有用的。泛化能力较弱的一个模型其在激活空间捕捉的方向是有限的。另一方面,如果一个模型的特征与另一个特征正交,则可以在激活空间中捕捉不同方向的信息,从而提高了模型的泛化能力。对于一个常规的卷积网络,可以通过分析层与层之间特征的相关性来计算得到最大表示的filters,然后将这些filters进行组合。然而,这些措施对于卷积网络应用到实际场景中需要大量的计算资源。一种替代方法是对于基于SGD的训练的损失增加了一个正则化处理从而促进了激活值最小化收敛,但这种方法对于模型的提升效果有限。一种相似的做法是促进filter weights之间的正交性。有研究发现,低层次的filter与对应的相反阶段是重复的,让filters趋于正交化则会减少重复性,同时有利于提高模型的性能及泛化能力,同时也有利于训练时收敛的稳定性。由于RNN对初始条件较为敏感,因此,需要进行正交化初始化,但此举并不完全适用于卷积网络。上述因素促使本文思考如何将正交初始化用于卷积网络中,同时将偏差进行分级评价。由于输入数据的feature map是相互独立的,因此要得到正交需要在整个训练过程中计算数据的统计分布,这里计算量有点庞大。而本文只计算filter weights之间的正交。本文通过实验发现通过对权重加正则化不足以促进用于捕捉整个输入数据范围的特征的建立。本文减少filters重叠性可以看作是一种隐式的正则化,同时,在不影响收敛的前提下,提高了filter weight的正交性。
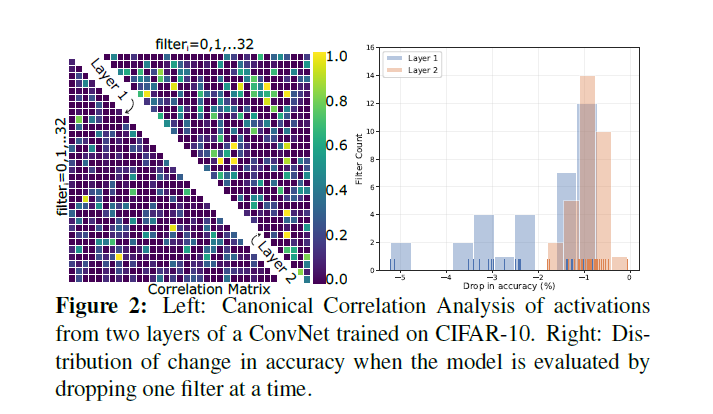
本文采用Canonical Correlation Analysis(CCA)来分析一层网络中的特征的重叠度。CCA评估发现,对于随机变量的线性组合之间表现出最大的相关性。CCA可以很好的判断学习到的特征是否重复。有研究通过分析不同层的激活发现,卷积网络结构学习相似的表达力。将CCA与SVD结合起来分析不同层中激活值的相关性发现,增加模型的深度不一定增加模型的维度。这是由于学习到的特征有几层是相关的。比如VGG16这种参数量较多的网络。其中几层卷积,每层有512个卷积核,其filter必定存在大量的相关性,其中50%的卷积核被丢弃后,其性能仍可以保持。本文为了验证冗余问题不仅存在在大参数模型中,后面有设计了一个小型的模型,通过分析发现,该模型仍无法完整的捕捉训练数据的整个空间。因此,该问题与网络参数规模不太相关,与训练的姿势有关。
对于一个训练的模型,可以通过一个个移除filter来验证模型性能的损失来评估该filter的作用。这种标准被称为greedy Oracle。本文对模型中的每个核应用该方法。结果如下图2右所示。前两层中的大部分filter对模型准确率的贡献不足1%,个别的filter超过4%。这就表明即使是小型模型也可以在降低损失的前提下对filter进行剪枝。如下左图所示,不同层激活值的线性组合的相关性,其中,有几层具有较强的相关性。第二层相比第一层具有更多重叠的特征。总之,通过正常的训练无法最大化网络的表示能力。
训练机制:RePR
本文更改训练过程,循环的将filter进行裁剪,然后进行再训练,接着对剪裁的filter进行重初始化。如此循环。本文将每个Filter(3D张量)作为一个单独的单元。同时,将其看作是一个长向量f,定义M为一个具有F个filters的模型传播L层。![]() 代表F的一个子集。
代表F的一个子集。![]() 表示一个完整的模型,而
表示一个完整的模型,而![]() 表示移除
表示移除![]() 个filters后的模型。本文的训练机制再完整模型及子模型之间进行替换。这里引入了两个参数,第一个是交换前需要训练迭代的次数。S1代表完整模型的迭代次数,S2代表子模型的迭代次数。这两个数值需要进行精心设计,从而可以使网络再前面网络的基础上性能有所提升。第二个超参数是控制该训练机制交替的次数。这里定义为N。该值具有超出范围的最小影响,同时不需要进行微调。
个filters后的模型。本文的训练机制再完整模型及子模型之间进行替换。这里引入了两个参数,第一个是交换前需要训练迭代的次数。S1代表完整模型的迭代次数,S2代表子模型的迭代次数。这两个数值需要进行精心设计,从而可以使网络再前面网络的基础上性能有所提升。第二个超参数是控制该训练机制交替的次数。这里定义为N。该值具有超出范围的最小影响,同时不需要进行微调。
本文算法最重要的部分是用于将filters进行分级的准则。![]() 代表该标准,与filter的值有关。可以是正则化的权重,或者权重的梯度,或者本文的标准,一层中filter间的相关性。
代表该标准,与filter的值有关。可以是正则化的权重,或者权重的梯度,或者本文的标准,一层中filter间的相关性。
本文的算法是一个微观层级的同时并不是一个权重更新准则。因此不属于SGD或者Adam,RmsProp等调整方法。本文方法可以任何算法结合使用,但如果优化算法需要对学习率进行初始化,最好需要对剪枝的权重的相关学习率重新进行初始化。同样对于BN相关的也需要进行重新初始化。本文将![]() filter被剪裁前初始化为正交的。同样初始化为被剪裁的filters
filter被剪裁前初始化为正交的。同样初始化为被剪裁的filters![]() ,通过对来自相同层的权重进行QR分解来找的null-space同时,使用基于此找到正交初始化点。
,通过对来自相同层的权重进行QR分解来找的null-space同时,使用基于此找到正交初始化点。
本文算法全程:Re-initailizing-Pruning-Repr,算法流程如下

本文选用一个浅层模型来分析我们训练机制的动态变化及该机制再训练测试上的作用。浅层的模型可以计算每个filter的greedy Oracle ranking。这样可以确定训练机制对结果的影响,而不会应为排名标准而混淆结果。
考虑一个n层没有skip及dense结构的卷积网络,每个含有X个filter,表示如下。定义该结构为![]() ,因此,
,因此,![]() 表示含有96个卷积核。基于学习率为0.01的SGD进行训练,得到0.73的测试准确率。结果如下图所示。
表示含有96个卷积核。基于学习率为0.01的SGD进行训练,得到0.73的测试准确率。结果如下图所示。
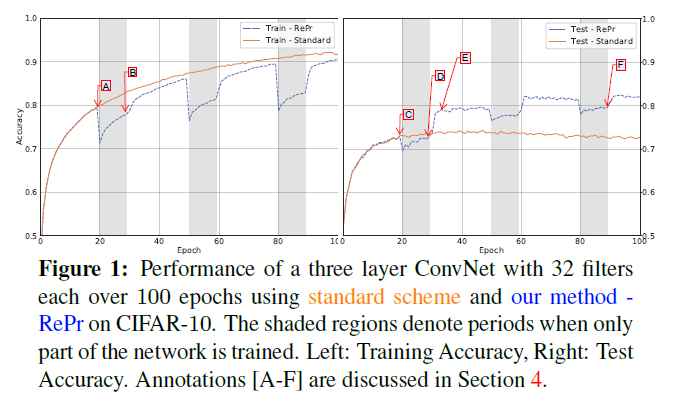
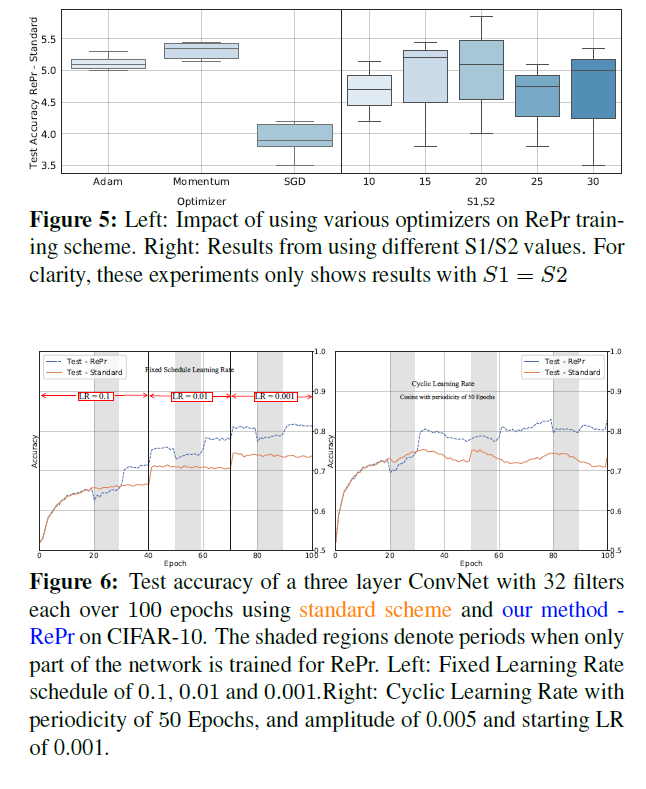
本例中,RePr机制设置S1=20,S2=10,N=3,p%=30,以及分级标准R为greedy Orcale。从训练集中移除5k张图片作为validation用于计算oracle分级。在training plot中标记A标出了权重第一次被剪裁的位置。标记C表示该点测试的准确率。该点的准确率比训练的点A的准确率要低。这是由于大部分模型都处于过拟合。而D点的准确率与C相同,而D模型参数只有C的70%。
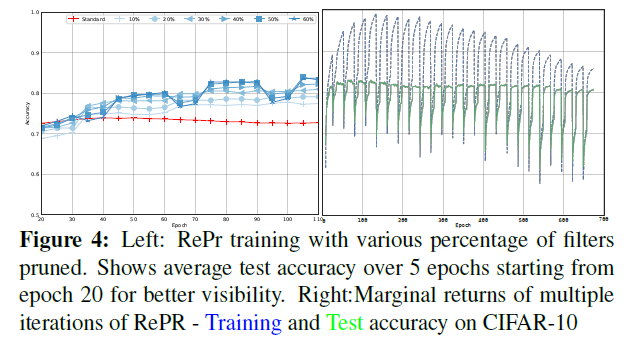
让人惊讶的点是E点。在引入剪裁后的filters的迭代几轮后其性能超过了C点。而C点与E点的容量是形同的。而且E更高的准确率并不是由于模型的收敛。在进行正常训练时,测试准确率并未发生变化。模型首先增加网络,然后进行剪枝,其不再适用于另一个阶段,因此间接提高性能。然而这种做法不利于获得小型模型。基于RePr再进行两次迭代,则F点处70%的模型得到的性能与100%的模型的效果是相似的。
从图中还可以看出来Repr模型训练的准确率更低,这表示模型某种形式上的正则化。如下图右边所示。虽然测试准确率下降很快,但训练与测试之间的差距不断减少。
评价标准:inter-filter 正交性
搜索的目的是找到至少两个方面的重要的filters,(1)计算大型网络的greedy oracel不会产生过多的计算量。(2)greedy oracel可能不是最优标准。如果一个filter捕捉一个特殊的方向,则其无法用其他filters线性组合将其进行替代。在接下来的再初始化及训练后,可能很难恢复到原来的方向设置中。
由激活层捕捉的方向用于描述模型的容量。生成正交化特征可以最大化捕捉的方向以及网络的表示能力。在密集层中,正交权重会得到正交化的特征。然而,无法确定的是如何捕捉卷积网络中的正交性。一个卷积层的参数组成一个sparse kernel,同时共享输入的激活层。一个卷积层中的所有参数是否都应该考虑其正交性?促进权重正交初始化的理论基于密集连接。同时遵循深度学习库将卷积层看作一个巨型向量。最近研究卷积filters正交性其动力在于深层网络的收敛性,同时,其并不是特征正交性。本文实验发现较好的性能是一层中filter之间的正交性,而不是kernel级别的正交性。
一个kxk的卷积核通常是3D的张量kxkxc,将此张量拉伸未1D张量。其大小未k*k*c,并将其表示为f.![]() 表示第l层filters的数量。
表示第l层filters的数量。![]() L为卷积网络的层数。
L为卷积网络的层数。![]() 为l层的拉伸向量。
为l层的拉伸向量。![]() 代表正则化后的权重。则l层中的filter f按如下等式计算。
代表正则化后的权重。则l层中的filter f按如下等式计算。
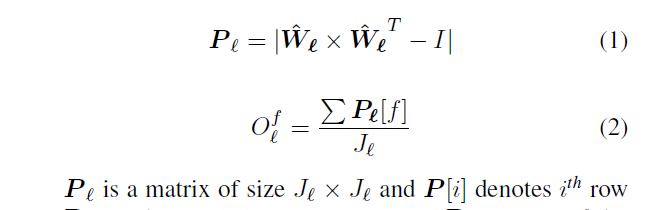
filter中P的某一行非对角线元素表示与f相同层中其他filter的映射。当对于给定的filter,其他filters是正交的,则该行的和最小。对filters进行排序,并将最重要的filter进行剪枝。虽然计算一个层中的单个filter,但排序作用在网络的整个filters中。本文并不强制对每层进行排序,因为需要对每层学习一个产参数p%,而其中一些层要比其他层更为敏感。本文对deeper的网络层相比earlyer层剪枝更多的filters。这很符合给定网络中每个filter分布一致。
本文标准的计算并不需要很多的计算量,比如Hessian的反矩阵及二阶导,而且该标准对任意尺寸的网络该标准都适用。最大的计算量是矩阵L,其大小为![]() ,而本文的计算仍比权重的正则化,激活值及Average percentage of Zeros的计算量大。有了正交的filter后,一个问题应运而生就是是否可以在损失函数上增加一个soft惩罚来改进训练。本文实验在损失函数中增加了
,而本文的计算仍比权重的正则化,激活值及Average percentage of Zeros的计算量大。有了正交的filter后,一个问题应运而生就是是否可以在损失函数上增加一个soft惩罚来改进训练。本文实验在损失函数中增加了![]() ,但并未看到任何提升。对所有filters进行正则化惩罚,同时改变损失函数的外形使权重进行随机正交,并未有所改进。
,但并未看到任何提升。对所有filters进行正则化惩罚,同时改变损失函数的外形使权重进行随机正交,并未有所改进。
实验


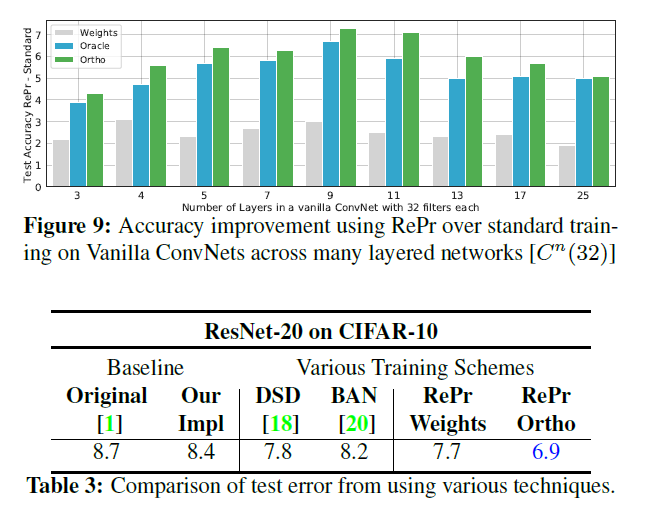

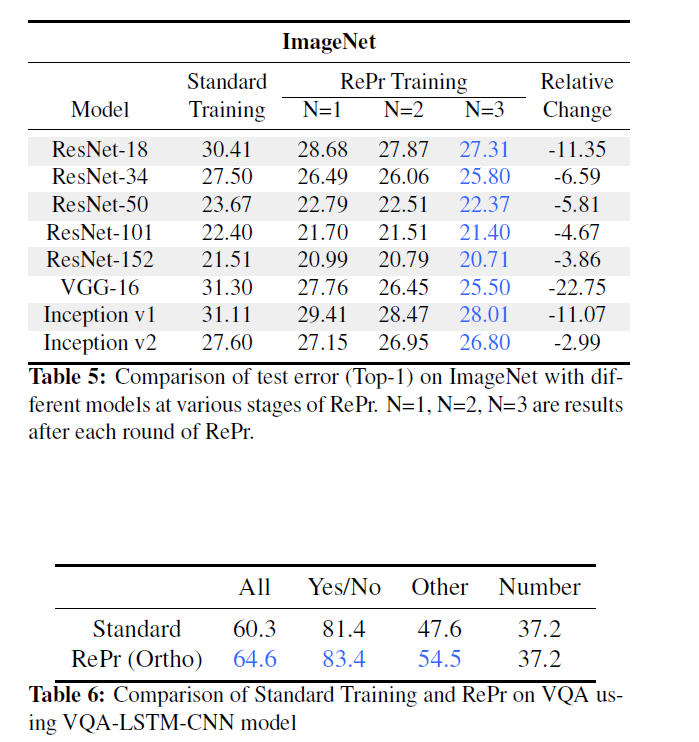
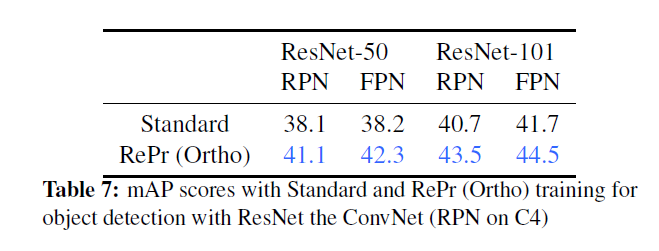
Reference
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 1, 2, 8
[2] Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He,and Piotr Doll´ar. Focal loss for dense object detection. IEEE transactions on pattern analysis and machine intelligence,2018. 1
[3] Kaiming He, Georgia Gkioxari, Piotr Doll´ar, and Ross B.Girshick. Mask r-cnn. 2017 IEEE International Conference on Computer Vision (ICCV), 2017. 1