今年毕业时的毕设是有关大数据及机器学习的题目。因为那个时间已经步入前端的行业自然选择使用JavaScript来实现其中具体的算法。虽然JavaScript不是做大数据处理的最佳语言,相比还没有优势,但是这提升了自己对与js的理解以及弥补了一点点关于数据结构的弱点。对机器学习感兴趣的朋友还是去用 python,最终还是在学校的死板论文格式要求之外,记录一下实现的过程和我自己对于算法的理解。
源码在github:https://github.com/abzerolee/ID3_Bayes_JS
开始学习机器学习算法是通过 Tom M. Mitchel. Machine Learning[M] 1994 一书。喜欢研究机器学习的朋友入门可以看看这本。接下来叙述的也仅仅是个人对于算法的浅薄理解与实现,只是针对没有接触过机器学习的朋友看个乐呵,自己总结记忆一下。当然能引起大家对机器学习算法的研究热情是最好不过的了。
算法原理
实现过程其实是 对训练集合(已知分类)的数据进行分析解析得到一个分类模型,通过输入一条测试数据(未知分类),分类模型可以推断出该条数据的分类结果。训练数据如下图所示

这个数据集合意思为天气状况决定是否要最终去打网球 一个数组代表一条天气情况与对应结果。前四列代表数据的特征属性(天气,温度,湿度,是否刮风),最后一列代表分类结果。根据这个训练集,运用朴素贝叶斯分类和决策树ID3分类则可以得到一个数据模型,然后通过输入一条测试数据:“sunny cool high TRUE” 来判断是否回去打网球。相似的只要特征属性保持一定且有对应的分类结果,不论训练集为什么样的数据,都可以通过特征属性得到分类结果。所谓分类模型,就是通过一些概率论,统计学的理论基础,用编程语言实现。下面简单介绍一下两种算法原理。
一.朴素贝叶斯分类
大学概率论的贝叶斯定理实现了通过计算概率求出假设推理的结论。贝叶斯定理如下图所示:
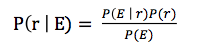
E代表训练集合,r表示一个分类结果(即yes或no),P(E)是一个独立于分类结果r的常量,可以发现P(E)越大,P(r|E)受到训练集影响越小。
即可以得到为 P(r) => P(yes)=9/14,或者P(no)=5/14,
再求的条件概率 P(E|r) => P(wind=TRUE|yes)=3/9 P(wind=FALSE|no)=2/5
这样可以得到每个特征属性在分类结果情况下的条件概率。当输入一条测试数据时,通过计算这条数据特质属性值在某种分类假设的钱以下的条件概率,就可以得到对应的分类假设的概率,然后比较出最大值,称为极大似然假设,对应的分类结果就是测试数据的分类结果。
比如测试数据如上:sunny,cool,high,TRUE则对应的计算为:
P(yes)P(sunny|yes)P(high|yes)P(cool|yes)P(TRUE|yes) = P(yes|E)
P(no)P(sunny|no)P(high|no)P(cool|no)P(TRUE|no) = P(no|E)
推断出 no 。
这里推荐介绍贝叶斯文本分类的博客http://www.cnblogs.com/phinecos/archive/2008/10/21/1315948.html
二.决策树ID3分类法
决策树分类法更像是我们思考的过程:
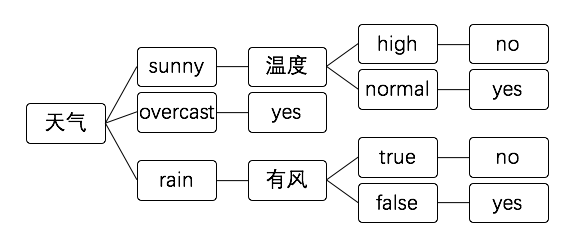
测试数据和上文相同,在天气节点判断 则进入sunny分支 温度节点判断 进入high 分支则直接得出no的结果。
决策树在根据测试数据分类时浅显易懂,关键点在通过训练数据构建决策树,那相应的出现两个问题:
1.选择哪个特征属性作为根节点判断?
2.特征属性值对应的分支上的下一个属性节点如何来判断?
这两个问题可以总结为 如何判断最优测试属性?在信息论中,期望信息越小,那么信息增益就越大,从而纯度就越高。其实就是特征属性能够为最终的分类结果带来多少信息,带来的信息越多,该特征属性越重要。对一个属性而言,分类时它是否存在会导致分类信息量发生变化,而前后信息量的差值就是这个特征属性给分类带来的信息量。而信息量就是信息熵。信息熵表示每个离散的消息提供的平均信息量。
如上文中的例子:可以表示为
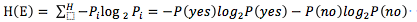
当选取了某个特征属性attr后的信息熵可以表示为
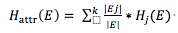
对应该属性的信息增益可以表示为
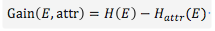
选择最适合树节点的特征属性,就是信息增益最大的属性。应该可以得到Gain(天气)=0.246
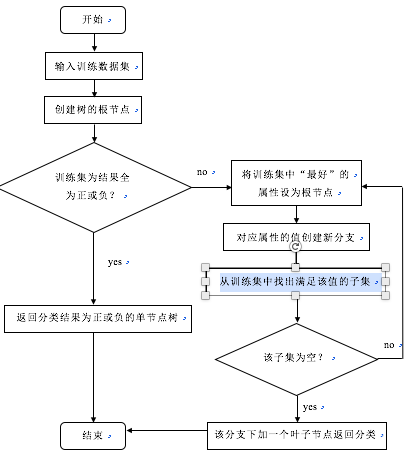
接下来是对该属性值分支的节点选取的判断,从训练集中找出满足该属性值的子集再次进行对于子集的每个属性的信息增益,比较。重复上述步骤,直到子集为空返回最普遍的分类结果。

上图为《Machine Learning》一书中对于ID3算法的介绍,下图为程序流程图
三.分类模型评估
分类模型的评估指标通过混淆矩阵来进行计算
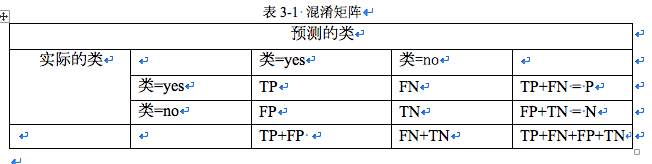
P为样本数据中yes的数量,N为样本数据中no的数量,TP为正确预测yes的数量,FP为把yes预测为no的数量,FN为把yes预测为no的数量,TN为正确预测yes的数目。评估量度为
1.命中率:正确诊断确实患病的的概率 TP/P
2.虚警率:没有患病却诊断为患病概率。FP/N
分类模型的评估方法为交叉验证法与.632的平均抽样法,比如100条原始数据,对训练集有放回的随机抽样100次,并在每次抽样时标注抽取的次数 将大于63.2的数据作为训练集,小于的数据作为测试集,但是实际程序实现中可以样本偏离的太厉害我选择了44次作为标准。
这样将测试集的每一条数据输入,通过训练集得到的分类模型,得出测试数据的分类结果与真实分类进行比较。就可以得到混淆矩阵,最后根据混淆矩阵可以得到决策树与贝叶斯分类的命中率与虚警率。重复评估40次 则可以得到[命中率,虚警率],以命中率为纵坐标,虚警率为横坐标描点可以得到ROC曲线,描出的点越靠近左上角代表分类模型越正确,直观的表现出来两种分类模型差异。我得到的描点图如下所示
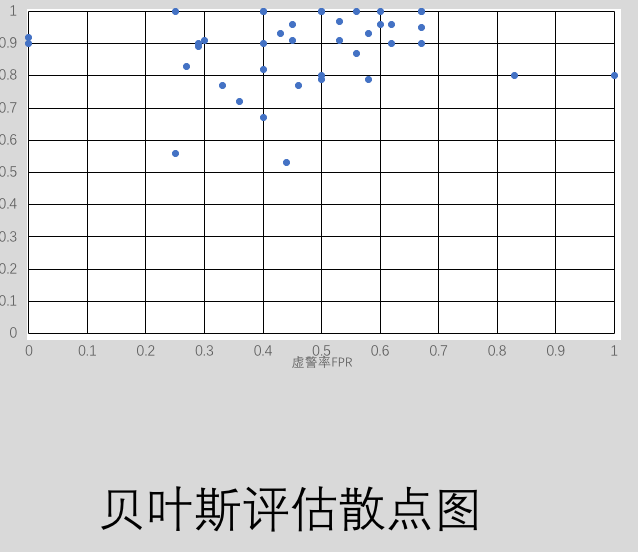
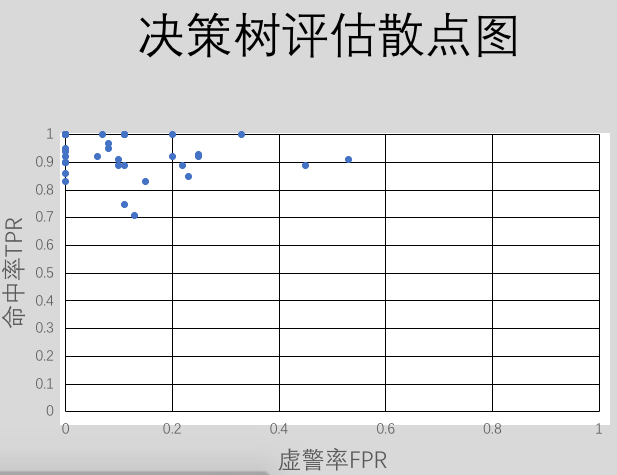
从图中明显可以发现对于小样本的数据,决策树分类模型更为准确。
核心代码
1.朴素贝叶斯分类法
const HashMap = require('./HashMap');
function Bayes($data){
this._DATA = $data;
}
Bayes.prototype = {
/**
* 将训练数据单条数据按类别分类
* @return HashMap<类别,对用类别的训练数据>
*/
dataOfClass: function() {
var map = new HashMap();
var t = [], c = '';
var datas = this._DATA;
if(!(datas instanceof Array)) return;
for(var i = 0; i < datas.length; i++){
t = datas[i];
c = t[t.length - 1];
if(map.hasKey(c)){
var ot = map.get(c);
ot.push(t);
map.put(c, ot);
}else{
var nt = [];
nt.push(t);
map.put(c, nt);
}
}
return map;
},
/**
* 预测测试数据的类别
* @param Array testT 测试数据
* @return String 测试数据对应类别
*/
predictClass: function(testT){
var doc = this.dataOfClass();
var maxP = 0, maxPIndex = -1;
var classes = doc.keys();
for(var i = 0; i < classes.length; i++){
var c = classes[i]
var d = doc.get(c);
var pOfC = d.length / this._DATA.length;
for(var j = 0; j < testT.length; j++){
var pv = this.pOfV(d, testT[j], j);
pOfC = pOfC * pv;
}
if(pOfC > maxP){
maxP = pOfC;
maxPIndex = i;
}
}
if(maxPIndex === -1 || maxPIndex > doc.length){
return '无法分类';
}
return classes[maxPIndex];
},
/**
* 计算指定属性在训练数据中指定值出现的条件概率
* @param d 属于某一类的训练元组
* @param value 指定属性
* @param index 指定属性所在列
* @return 特征属性在某类别下的条件概率
*/
pOfV: function(d, value, index){
var p = 0, count = 0, total = d.length, t = [];
for(var i = 0; i < total; i++){
if(d[i][index] === value)
count++;
}
p = count / total;
return p;
}
}
module.exports = Bayes;
2.决策树ID3分类法
const HashMap = require('./HashMap');
const $data = require('./data');
const TreeNode = require('./TreeNode');
const InfoGain = require('./InfoGain');
function Iterator(arr){
if(!(arr instanceof Array)){
throw new Error('iterator needs a arguments that type is Array!');
}
this.arr = arr;
this.length = arr.length;
this.index = 0;
}
Iterator.prototype.current = function() {
return this.arr[this.index-1];
}
Iterator.prototype.next = function(){
this.index += 1;
if(this.index > this.length || this.arr[this.index-1] === null)
return false;
return true;
}
function DecisionTree(data, attribute) {
if(!(data instanceof Array) || !(attribute instanceof Array)){
throw new Error('argument needs Array!');
}
this._data = data;
this._attr = attribute;
this._node = this.createDT(this._data,this._attr);
}
DecisionTree.prototype.createDT = function(data, attrList) {
var node = new TreeNode();
var resultMap = this.isPure(this.getTarget(data));
if(resultMap.size() === 1){
node.setType('result');
node.setName(resultMap.keys()[0]);
node.setVals(resultMap.keys()[0]);
// console.log('单节点树:' + node.getVals());
return node;
}
if(attrList.length === 0){
var max = this.getMaxVal(resultMap);
node.setType('result');
node.setName(max)
node.setVals(max);
// console.log('最普遍性结果:'+ max);
return node;
}
var maxGain = this.getMaxGain(data, attrList).maxGain;
var attrIndex = this.getMaxGain(data, attrList).attrIndex
// console.log('选出的最大增益率属性为:'+ attrList[attrIndex]);
// console.log('创建节点:'+attrList[attrIndex])
node.setName(attrList[attrIndex]);
node.setType('attribute');
var remainAttr = new Array();
remainAttr = attrList;
// remainAttr.splice(attrIndex, 1);
var self = this;
var gain = new InfoGain(data, attrList)
var attrValueMap = gain.getAttrValue(attrIndex); //最好分类的属性的值MAP
var possibleValues = attrValueMap.keys();
node_vals = possibleValues.map(function(v) {
// console.log('创建分支:'+v);
var newData = data.filter(function(x) {
return x[attrIndex] === v;
});
// newData = newData.map(function(v) {
// return v.slice(1);
// })
var child_node = new TreeNode(v, 'feature_values');
var leafNode = self.createDT(newData, remainAttr);
child_node.setVals(leafNode);
return child_node;
})
node.setVals(node_vals);
this._node = node;
return node;
}
/**
* 判断训练数据纯度分类是否为一种分类或没有分类
*/
DecisionTree.prototype.getTarget = function(data){
var list = new Array();
var iter = new Iterator(data);
while(iter.next()){
var index = iter.current().length - 1;
var value = iter.current()[index];
list.push(value);
}
return list;
},
/**
* 获取分类结果数组,判断纯度
*/
DecisionTree.prototype.isPure = function(list) {
var map = new HashMap(), count = 1;
list.forEach(function(item) {
if(map.get(item)){
count++;
}
map.put(item, count);
});
return map;
}
/**
* 获取最大增益量属性
*/
DecisionTree.prototype.getMaxGain = function(data, attrList) {
var gain = new InfoGain(data, attrList);
var maxGain = 0;
var attrIndex = -1;
for(var i = 0; i < attrList.length; i++){
var temp = gain.getGainRaito(i);
if(maxGain < temp){
maxGain = temp;
attrIndex = i;
}
}
return {attrIndex: attrIndex, maxGain: maxGain};
}
/**
* 获取resultMap中值最大的key
*/
DecisionTree.prototype.getMaxVal = function(map){
var obj = map.obj, temp = 0, okey = '';
for(var key in obj){
if(temp < obj[key] && typeof obj[key] === 'number'){
temp = obj[key];
okey = key;
};
}
return okey;
}
/**
* 预测属性
*/
DecisionTree.prototype.predictClass = function(sample){
var root = this._node;
var map = new HashMap();
var attrList = this._attr;
for(var i = 0; i < attrList.length; i++){
map.put(attrList[i], sample[i]);
}
while(root.type !== 'result'){
if(root.name === undefined){
return root = '无法分类';
}
var attr = root.name;
var sample = map.get(attr);
var childNode = root.vals.filter(function(node) {
return node.name === sample;
});
if(childNode.length === 0){
return root = '无法分类';
}
root = childNode[0].vals; // 只遍历attribute节点
}
return root.vals;
}
module.exports = DecisionTree;
3.增益率计算
const HashMap = require('./HashMap');
function Iterator(arr){
if(!(arr instanceof Array)){
throw new Error('iterator needs a arguments that type is Array!');
}
this.arr = arr;
this.length = arr.length;
this.index = 0;
}
Iterator.prototype.current = function() {
return this.arr[this.index-1];
}
Iterator.prototype.next = function(){
this.index += 1;
if(this.index > this.length || this.arr[this.index-1] === null)
return false;
return true;
}
/**
* 计算信息增益类
* @param Array data 训练数据集
* @param Array data 作用的特征属性
*/
function InfoGain(data, attr) {
if(!(data instanceof Array) || !(attr instanceof Array)){
throw new Error('arguments needs Array!');
}
this._data = data;
this._attr = attr;
}
InfoGain.prototype = {
/**
* 获取训练数据分类个数
* @return hashMap<类别, 该类别数量>
*/
getTargetValue: function() {
var map = new HashMap();
var iter = new Iterator(this._data);
while(iter.next()){
var t = iter.current();
var key = t[t.length-1];
var value = map.get(key);
map.put(key, value !== undefined ? ++value : 1);
}
return map;
},
/**
* 获取训练数据信息熵
* @return 训练数据信息熵
*/
getEntroy: function(){
var targetValueMap = this.getTargetValue();
var targetKey = targetValueMap.keys(), entroy = 0;
var self = this;
var iter = new Iterator(targetKey);
while(iter.next()){
var p = targetValueMap.get(iter.current()) / self._data.length;
entroy += (-1) * p * (Math.log(p) / Math.LN2);
}
return entroy;
},
/**
* 获取属性值在训练数据集中的数量
* @param number index 属性名数组索引
*/
getAttrValue: function(index){
var map = new HashMap();
var iter = new Iterator(this._data);
while(iter.next()){
var t = iter.current();
var key = t[index];
var value = map.get(key);
map.put(key, value !== undefined ? ++value : 1);
}
return map;
},
/**
* 得到属性值在决策空间的比例
* @param string name 属性值
* @param number index 属性所在第几列
*/
getAttrValueTargetValue: function(name, index){
var map = new HashMap();
var iter = new Iterator(this._data);
while(iter.next()){
var t = iter.current();
if(name === t[index]){
var size = t.length;
var key = t[t.length-1];
var value = map.get(key);
map.put(key, value !== undefined ? ++value : 1);
}
}
return map;
},
/**
* 获取特征属性作用于训练数据集后分类出的数据集的熵
* @param number index 属性名数组索引
*/
getInfoAttr: function(index){
var attrValueMap = this.getAttrValue(index);
var infoA = 0;
var c = attrValueMap.keys();
for(var i = 0; i < attrValueMap.size(); i++){
var size = this._data.length;
var attrP = attrValueMap.get(c[i]) / size;
var targetValueMap = this.getAttrValueTargetValue(c[i], index);
var totalCount = 0 ,valueSum = 0;
for(var j = 0; j < targetValueMap.size(); j++){
totalCount += targetValueMap.get(targetValueMap.keys()[j]);
}
for(var k = 0; k < targetValueMap.size(); k++){
var p = targetValueMap.get(targetValueMap.keys()[k]) / totalCount;
valueSum += (Math.log(p) / Math.LN2) * p;
}
infoA += (-1) * attrP * valueSum;
}
return infoA;
},
/**
* 获得信息增益量
*/
getGain: function(index) {
return this.getEntroy() - this.getInfoAttr(index);
},
getSplitInfo: function(index){
var map = this.getAttrValue(index);
var splitA = 0;
for(var i = 0; i < map.size(); i++){
var size = this._data.length;
var attrP = map.get(map.keys()[i]) / size;
splitA += (-1) * attrP * (Math.log(attrP) / Math.LN2);
}
return splitA;
},
/**
* 获得增益率
*/
getGainRaito: function(index){
return this.getGain(index) / this.getSplitInfo(index);
},
getData4Value: function(attrValue, attrIndex){
var resultData = new Array();
var iter = new Iterator(this._data);
while(iter.next()){
var temp = iter.current();
if(temp[attrIndex] === attrValue){
resultData.push(temp);
}
}
return resultData;
}
}
// var gain = new InfoGain($data, ['sunny']);
// console.log(gain.getGainRaito(0), gain.getGainRaito(1),gain.getGainRaito(2),gain.getGainRaito(3))
// console.log(gain.getGain(0),gain.getGain(1),gain.getGain(2),gain.getGain(3))
module.exports = InfoGain;
具体的程序实现我会再继续介绍的,待续。。。。