前半部分muduo笔记 日志库(一),中提到muduo异步日志库分为两部分:前端和后端。这部分描述后端。
后端
前端主要实现异步日志中的日志功能,为用户提供将日志内容转换为字符串,封装为一条完整的log消息存放到RAM中;
而实现异步,核心是通过专门的后端线程,与前端线程并发运行,将RAM中的大量日志消息写到磁盘上。
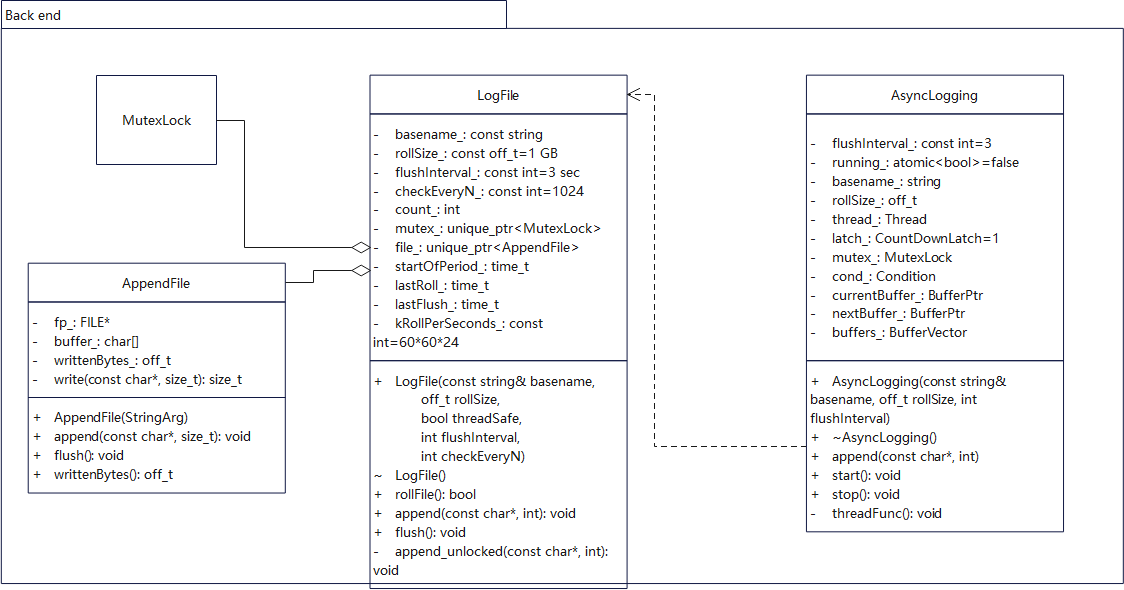
后端主要包括:AsyncLogging, LogFile, AppendFile,MutexLock。
AsyncLogging 提供后端线程,定时将log缓冲写到磁盘,维护缓冲及缓冲队列。
LogFile 提供日志文件滚动功能,写文件功能。
AppendFile 封装了OS提供的基础的写文件功能。
类图关系如下:
AsyncLogging类
AsyncLogging 主要职责:提供大缓冲Large Buffer(默认4MB)存放多条日志消息,缓冲队列BufferVector用于存放多个Large Buffer,为前端线程提供线程安全的写Large Buffer操作;提供专门的后端线程,用于定时或缓冲队列非空时,将缓冲队列中的Large Buffer通过LogFile提供的日志文件操作接口,逐个写到磁盘上。
数据成员
/**
* Provide async logging function. backend.
* Background thread (just only one) call this module to write log to file.
*/
class AsyncLogging : noncopyable
{
...
private:
typedef muduo::detail::FixedBuffer<muduo::detail::kLargeBuffer> Buffer; // Large Buffer Type
typedef std::vector<std::unique_ptr<Buffer>> BufferVector; // 已满缓冲队列类型
typedef BufferVector::value_type BufferPtr;
const int flushInterval_; // 冲刷缓冲数据到文件的超时时间, 默认3秒
std::atomic<bool> running_; // 后端线程loop是否运行标志
const string basename_; // 日志文件基本名称
const off_t rollSize_; // 日志文件滚动大小
muduo::Thread thread_; // 后端线程
muduo::CountDownLatch latch_; // 门阀, 同步调用线程与新建的后端线程
muduo::MutexLock mutex_; // 互斥锁, 功能相当于std::mutex
muduo::Condition cond_ GUARDED_BY(mutex_); // 条件变量, 与mutex_配合使用, 等待特定条件满足
BufferPtr currentBuffer_ GUARDED_BY(mutex_); // 当前缓冲
BufferPtr nextBuffer_ GUARDED_BY(mutex_); // 空闲缓冲
BufferVector buffers_ GUARDED_BY(mutex_); // 已满缓冲队列
}
AsyncLogging数据按功能主要分为3部分:1)维护存放log消息的大缓冲Large Buffer;2)后端线程;3)传递给其他类对象的参数,如basename_,rollSize_;
LargeBuffer 存放大量log消息
Large Buffer(FixedBuffermuduo::detail::kLargeBuffer)默认大小4MB,用于存储多条log消息;相对的,还有Small Buffer(FixedBuffermuduo::detail::kSmallBuffer)默认大小4KB,用于存储一条log消息。
当前端线程通过调用LOG_XXX << "..."时,如何将log消息传递给后端呢?
可以通过调用AsyncLogging::append()
void AsyncLogging::append(const char *logline, int len)
{
muduo::MutexLockGuard lock(mutex_);
if (currentBuffer_->avail() > len)
{ // current buffer's free space is enough to fill C string logline[0..len-1]
currentBuffer_->append(logline, static_cast<size_t>(len));
}
else
{ // current buffer's free space is not enough
buffers_.push_back(std::move(currentBuffer_));
if (nextBuffer_)
{
currentBuffer_ = std::move(nextBuffer_);
}
else
{
currentBuffer_.reset(new Buffer); // rarely happens
}
currentBuffer_->append(logline, static_cast<size_t>(len));
cond_.notify();
}
}
append()可能会被多个前端线程调用,因此必须考虑线程安全,可以用mutex_加锁。
append()基本思路:当前缓冲(currentBuffer_)剩余空间(avail())足够存放新log消息大小(len)时,就直接存放到当前缓冲;当前缓冲剩余空间不够时,说明当前缓冲已满(或者接近已满),就将当前缓冲move到已满缓冲队列(buffers_),将空闲缓冲move到当前缓冲,再把新log消息存放到当前缓冲中(此时当前缓冲为空,剩余空间肯定够用),最后唤醒等待中的后端线程。
注意:Large Buffer是通过std::unique_ptr指向的,move操作后,原来的 std::unique_ptr就会值为空。
问题:
1)为什么最后要通过cond_唤醒后端线程?
因为没有log消息要记录时,后端线程很可能阻塞等待log消息,当有缓冲满时,及时唤醒后端将已满缓冲数据写到磁盘上,能有效改善新能;否则,短时间内产生大量log消息,可能造成数据堆积,甚至丢失,而后端线程一直休眠(直到3秒超时唤醒)。
2)为什么调用notify()而不是notifyAll(),只唤醒一个线程,而不是唤醒所有线程?
因为一个应用程序通常只有一个日志库后端,而一个后端通常只有一个后端线程,也只会有一个后端线程在该条件变量上等待,因此唤醒一个线程足以。
后端线程 异步写数据到log文件
后端线程的创建就是启动,是在start()中,通过调用Thread::start()完成。门阀latch_目的在于让调用start()线程等待线程函数启动完成,而线程函数中调用latch_.countDown()表示启动完成,当然,前提是latch_计数器初值为1。
// Control background thread
void start()
{
running_ = true;
thread_.start();
latch_.wait();
}
void stop() NO_THREAD_SAFETY_ANALYSIS
{
running_ = false;
cond_.notify();
thread_.join();
}
而AsyncLogging::stop()用于关闭后端线程,通常是在析构函数中,调用AsyncLogging::stop() 停止后端线程。
~AsyncLogging()
{
if (running_)
{
stop();
}
}
后端线程函数threadFunc,会构建1个LogFile对象,用于控制log文件创建、写日志数据,创建2个空闲缓冲区buffer1、buffer2,和一个待写缓冲队列buffersToWrite,分别用于替换当前缓冲currentBuffer_、空闲缓冲nextBuffer_、已满缓冲队列buffers_,避免在写文件过程中,锁住缓冲和队列,导致前端无法写数据到后端缓冲。
threadFunc中,提供了一个loop,基本流程是这样的:
1)每次当已满缓冲队列中有数据时,或者即使没有数据但3秒超时,就将当前缓冲加入到已满缓冲队列(即使当前缓冲没满),将buffer1移动给当前缓冲,buffer2移动给空闲缓冲(如果空闲缓冲已移动的话)。
2)然后,再交换已满缓冲队列和待写缓冲队列,这样已满缓冲队列就为空,待写缓冲队列就有数据了。
3)接着,将待写缓冲队列的所有缓冲通过LogFile对象,写入log文件。
4)此时,待写缓冲队列中的缓冲,已经全部写到LogFile指定的文件中(也可能在内核缓冲中),擦除多余缓冲,只用保留两个,归还给buffer1和buffer2。
5)此时,待写缓冲队列中的缓冲没有任何用处,直接clear即可。
6)将内核高速缓存中的数据flush到磁盘,防止意外情况造成数据丢失。
后端线程函数threadFunc,会构建1个LogFile对象,用于控制log文件创建、写日志数据,创建2个空闲缓冲区buffer1、buffer2,和一个待写缓冲队列buffersToWrite,分别用于替换当前缓冲currentBuffer_、空闲缓冲nextBuffer_、已满缓冲队列buffers_,避免在写文件过程中,锁住缓冲和队列,导致前端无法写数据到后端缓冲。
threadFunc中,提供了一个loop,基本流程是这样的:
1)每次当已满缓冲队列中有数据时,或者即使没有数据但3秒超时,就将当前缓冲加入到已满缓冲队列(即使当前缓冲没满),将buffer1移动给当前缓冲,buffer2移动给空闲缓冲(如果空闲缓冲已移动的话)。
2)然后,再交换已满缓冲队列和待写缓冲队列,这样已满缓冲队列就为空,待写缓冲队列就有数据了。
3)接着,将待写缓冲队列的所有缓冲通过LogFile对象,写入log文件。
4)此时,待写缓冲队列中的缓冲,已经全部写到LogFile指定的文件中(也可能在内核缓冲中),擦除多余缓冲,只用保留两个,归还给buffer1和buffer2。
5)此时,待写缓冲队列中的缓冲没有任何用处,直接clear即可。
6)将内核高速缓存中的数据flush到磁盘,防止意外情况造成数据丢失。
void AsyncLogging::threadFunc()
{
assert(running_ == true);
latch_.countDown();
LogFile output(basename_, rollSize_, false); // only called by this thread, so no need to use thread safe
BufferPtr newBuffer1(new Buffer);
BufferPtr newBuffer2(new Buffer);
newBuffer1->bzero();
newBuffer2->bzero();
BufferVector buffersToWrite;
static const int kBuffersToWriteMaxSize = 25;
buffersToWrite.reserve(16); // FIXME: why 16?
while (running_)
{
// ensure empty buffer
assert(newBuffer1 && newBuffer1->length() == 0);
assert(newBuffer2 && newBuffer2->length() == 0);
// ensure buffersToWrite is empty
assert(buffersToWrite.empty());
{ // push buffer to vector buffersToWrite
muduo::MutexLockGuard lock(mutex_);
if (buffers_.empty())
{ // unusual usage!
cond_.waitForSeconds(flushInterval_); // wait condition or timeout
}
// not empty or timeout
buffers_.push_back(std::move(currentBuffer_));
currentBuffer_ = std::move(newBuffer1);
buffersToWrite.swap(buffers_);
if (!nextBuffer_)
{
nextBuffer_ = std::move(newBuffer2);
}
}
// ensure buffersToWrite is not empty
assert(!buffersToWrite.empty());
if (buffersToWrite.size() > kBuffersToWriteMaxSize) // FIXME: why 25? 25x4MB = 100MB, 也就是说, 从上次loop到本次loop已经堆积超过100MB, 就丢弃多余缓冲
{
char buf[256];
snprintf(buf, sizeof(buf), "Dropped log message at %s, %zd larger buffers\n",
Timestamp::now().toFormattedString().c_str(),
buffersToWrite.size() - 2);
fputs(buf, stderr);
output.append(buf, static_cast<int>(strlen(buf)));
buffersToWrite.erase(buffersToWrite.begin() + 2, buffersToWrite.end()); // keep 2 buffer
}
// append buffer content to logfile
for (const auto& buffer : buffersToWrite)
{
// FIXME: use unbuffered stdio FILE? or use ::writev ?
output.append(buffer->data(), buffer->length());
}
if (buffersToWrite.size() > 2)
{
// drop non-bzero-ed buffers, avoid trashing
buffersToWrite.resize(2);
}
// move vector buffersToWrite's last buffer to newBuffer1
if (!newBuffer1)
{
assert(!buffersToWrite.empty());
newBuffer1 = std::move(buffersToWrite.back());
buffersToWrite.pop_back();
newBuffer1->reset(); // reset buffer
}
// move vector buffersToWrite's last buffer to newBuffer2
if (!newBuffer2)
{
assert(!buffersToWrite.empty());
newBuffer2 = std::move(buffersToWrite.back());
buffersToWrite.pop_back();
newBuffer2->reset(); // reset buffer
}
buffersToWrite.clear();
output.flush();
}
output.flush();
}
异常处理:
当已满缓冲队列中的数据堆积(默认缓冲数超过25),就会丢弃多余缓冲,只保留最开始2个。
为什么保留2个?个人觉得2个~16个都是可以的,不过,为了有效减轻log导致的负担,丢弃多余的也未尝不可。
25的含义:
25个缓冲,每个4MB,共100MB。也就是说,上次处理周期到本次,已经堆积了超过100MB数据待处理。
假设磁盘的写速度100MB/S,要堆积100MB有2种极端情况:
1)1S内产生200MB数据;
2)25秒内,平均每秒产生104MB数据;
不论哪种情况,都是要超过磁盘的处理速度。而实际应用中,只有产生数据速度不到磁盘写速度的1/10,应用程序性能才不会受到明显影响。
[======]
LogFile类
LogFile 主要职责:提供对日志文件的操作,包括滚动日志文件、将log数据写到当前log文件、flush log数据到当前log文件。
构造函数
LogFile::LogFile(const std::string &basename,
off_t rollSize,
bool threadSafe, // 线程安全控制项, 默认为true. 当只有一个后端AsnycLogging和后端线程时, 该项可置为false
int flushInterval,
int checkEveryN)
: basename_(basename), // 基础文件名, 用于新log文件命名
rollSize_(rollSize), // 滚动文件大小
flushInterval_(flushInterval), // 冲刷时间限值, 默认3 (秒)
checkEveryN_(checkEveryN), // 写数据次数限值, 默认1024
count_(0), // 写数据次数计数, 超过限值checkEveryN_时清除, 然后重新计数
mutex_(threadSafe ? new MutexLock : NULL), // 互斥锁指针, 根据是否需要线程安全来初始化
startOfPeriod_(0), // 本次写log周期的起始时间(秒)
lastRoll_(0), // 上次roll日志文件时间(秒)
lastFlush_(0) // 上次flush日志文件时间(秒)
{
assert(basename.find('/') == string::npos); // basename不应该包含'/', 这是路径分隔符
rollFile();
}
重新启动时,可能并没有log文件,因此在构建LogFile对象时,直接调用rollFile()以创建一个全新的日志文件。
滚动日志文件
当日志文件接近指定的滚动限值(rollSize)时,需要换一个新文件写数据,便于后续归档、查看。调用LogFile::rollFile()可以实现文件滚动。
bool LogFile::rollFile()
{
time_t now = 0;
string filename = getLogFileName(basename_, &now);
time_t start = now / kRollPerSeconds_ * kRollPerSeconds_;
if (now > lastRoll_)
{ // to avoid identical roll by roll time
lastRoll_ = now;
lastFlush_ = now;
startOfPeriod_ = start;
// create new log file with new filename
file_.reset(new FileUtil::AppendFile(filename));
return true;
}
return false;
}
滚动日志文件操作的关键是:1)取得新log文件名,文件名全局唯一;2)创建并打开一个新log文件,用指向LogFile对象的unique_ptr指针file_表示。
异常处理:
滚动操作会新建一个文件,而为避免频繁创建新文件,rollFile会确保上次滚动时间到现在如果不到1秒,就不会滚动。
注意:是否滚动日志文件的条件判断,并不在rollFile,而是在写数据到log文件的LogFile::append_unlocked()中,因为写新数据的时候,是判断当前log文件大小是否足够大的最合适时机。而rollFile只用专门负责如何滚动log文件即可。
日志文件名
getLogFileName根据调用者提供的基础名,以及当前时间,得到一个全新的、唯一的log文件名。或许叫nextLogFileName更合适。
string LogFile::getLogFileName(const string &basename, time_t *now) // static
{
string filename;
filename.reserve(basename.size() + 64); // extra 64 bytes for timestamp etc.
filename = basename;
char timebuf[32];
struct tm tmbuf;
*now = time(NULL);
gmtime_r(now, &tmbuf); // FIXME: localtime_r ?
strftime(timebuf, sizeof(timebuf), ".%Y%m%d-%H%M%S.", &tmbuf);
filename += timebuf;
filename += ProcessInfo::hostname();
char pidbuf[32];
snprintf(pidbuf, sizeof(pidbuf), ".%d", ProcessInfo::pid());
filename += pidbuf;
filename += ".log";
return filename;
}
gmtime_r获取的是gmt时区时间,localtime_r获取的是本地时间。
新log文件名格式:
basename + now + hostname + pid + ".log"
basename 基础名, 由用户指定, 通常可设为应用程序名
now 当前时间, 格式: "%Y%m%d-%H%M%S"
hostname 主机名
pid 进程号, 通常由OS提供, 通过getpid获取
".log" 固定后缀名, 表明这是一个log文件
各部分之间, 用"."连接
如下面是一个根据basename为"test_log_mt"生成的log文件名:
test_log_mt.20220218-134000.ubuntu.12426.log
写日志文件操作
LogFile提供了2个接口,用于向当前日志文件file_写入数据。append本质上是通过append_unlocked完成对日志文件写操作,但多了线程安全。用户只需调用第一个接口即可,append会根据线程安全需求,自行判断是否需要加上;第二个是private接口。
void append(const char *logline, int len);
void append_unlocked(const char *logline, int len);
append_unlocked 会先将log消息写入file_文件,之后再判断是否需要滚动日志文件;如果不滚动,就根据append_unlocked的调用次数和时间,确保1)一个log文件超时(默认1天),就创建一个新的;2)flush文件操作,不会频繁执行(默认间隔3秒)。
void LogFile::append_unlocked(const char *logline, int len)
{
file_->append(logline, len);
if (file_->writtenBytes() > rollSize_)
{ // written bytes to file_ > roll threshold (rollSize_)
rollFile();
}
else
{
++count_;
if (count_ >= checkEveryN_)
{
count_ = 0;
time_t now = ::time(NULL);
time_t thisPeriod_ = now / kRollPerSeconds_ * kRollPerSeconds_;
if (thisPeriod_ != startOfPeriod_)
{ // new period, roll file for log
rollFile();
}
else if (now - lastFlush_ > flushInterval_)
{ // timeout ( flushInterval_ = 3 seconds)
lastFlush_ = now;
file_->flush();
}
}
}
}
append如何根据需要选择是否线程安全地调用append_unlocked?
可以根据mutex_是否为空。因为构造时,根据用户传入的threadSafe实参,决定了mutex_是否为空。
void LogFile::append(const char *logline, int len)
{
if (mutex_)
{
MutexLockGuard lock(*mutex_);
append_unlocked(logline, len);
}
else
{
append_unlocked(logline, len);
}
}
flush日志文件
flush操作往往与write文件操作配套。LogFile::flush实际上是通过AppendFile::flush(),完成对日志文件的冲刷。与LogFile::append()类似,flush也能通过mutex_指针是否为空,自动选择线程安全版本,还是非线程安全版本。
void LogFile::flush()
{
if (mutex_)
{
MutexLockGuard lock(*mutex_);
file_->flush();
}
else
{
file_->flush();
}
}
[======]
AppendFile类
AppendFile位于FileUtil.h/.cc,封装了OS提供的,底层的创建/打开文件、写文件、关闭文件等操作接口,并没有专门考虑线程安全问题。线程安全由上一层级调用者,如LogFile来保证。
数据结构
AppendFile的数据结构较简单,
// not thread safe
class AppendFile : public noncopyable
{
public:
explicit AppendFile(StringArg filename);
~AppendFile();
void append(const char* logline, size_t len); // 添加log消息到文件末尾
void flush(); // 冲刷文件到磁盘
off_t writtenBytes() const { return writtenBytes_; } // 返回已写字节数
private:
size_t write(const char* logline, size_t len); // 写数据到文件
FILE* fp_; // 文件指针
char buffer_[ReadSmallFile::kBufferSize]; // 文件操作的缓冲区
off_t writtenBytes_; // 已写字节数
};
RAII方式打开、关闭文件
AppendFile采用RAII方式管理文件资源,构建对象即打开文件,销毁对象即关闭文件。
AppendFile::AppendFile(StringArg filename)
: fp_(::fopen(filename.c_str(), "ae")), // 'e' for O_CLOEXEC
writtenBytes_(0)
{
assert(fp_);
::setbuffer(fp_, buffer_, sizeof(buffer_)); // change stream fp_'s buffer to buffer_
#if 0
// optimization for predeclaring an access pattern for file data
struct stat statbuf;
fstat(fd_, &statbuf);
::posix_fadvise(fp_, 0, statbuf.st_size, POSIX_FADV_DONTNEED);
#endif
}
AppendFile::~AppendFile()
{
::fclose(fp_);
}
为posix_fadvise(2)指定POSIX_FADV_DONTNEED选项,告诉内核在近期不会访问文件的指定数据,以便内核对其进行优化。
写数据到文件
AppendFile有个两个接口:append和write。其中,append()是供用户调用的public接口,确保将指定数据附加到文件末尾,实际的写文件操作是通过write()来完成的;write通过非线程安全的glibc库函数fwrite_unlocked()来完成写文件操作,而没有选择线程安全的fwrite(),主要是出于性能考虑。
一个后端通常只有一个后端线程,一个LogFile对象,一个AppendFile对象,这样,也就只会有一个线程写同一个log文件。
void AppendFile::append(const char *logline, size_t len)
size_t AppendFile::write(const char *logline, size_t len);
append和write实现:
void AppendFile::append(const char *logline, size_t len)
{
size_t written = 0;
/* write len byte to fp_ unless complete writing or error occurs */
while (written != len)
{
size_t remain = len - written;
size_t n = write(logline + written, remain);
if (n != remain)
{
int err = ferror(fp_);
if (err)
{
fprintf(stderr, "AppendFile::append() failed %s\n", strerror_tl(err));
clearerr(fp_); // clear error indicators for fp_
break;
}
}
written += n;
}
writtenBytes_ += written;
}
size_t AppendFile::write(const char *logline, size_t len)
{
// not thread-safe
return ::fwrite_unlocked(logline, 1, len, fp_);
}
可以看出,append是通过一个循环来确保所有数据都写到磁盘文件上,除非发生错误。
[======]
使用异步日志
自此,一个完整的异步日志前端、后端都已完成。但问题在于,应用程序如何使用?
为此,写一个测试程序,对比为前端Logger设置输出回调函数前后不同。
#include "muduo/base/AsyncLogging.h"
#include "muduo/base/Logging.h"
#include "muduo/base/Timestamp.h"
#include <stdio.h>
#include <unistd.h>
using namespace muduo;
static const off_t kRollSize = 1*1024*1024;
AsyncLogging* g_asyncLog = NULL;
inline AsyncLogging* getAsyncLog()
{
return g_asyncLog;
}
void test_Logging()
{
LOG_TRACE << "trace";
LOG_DEBUG << "debug";
LOG_INFO << "info";
LOG_WARN << "warn";
LOG_ERROR << "error";
LOG_SYSERR << "sys error";
// 注意不能轻易使用 LOG_FATAL, LOG_SYSFATAL, 会导致程序abort
const int n = 10;
for (int i = 0; i < n; ++i) {
LOG_INFO << "Hello, " << i << " abc...xyz";
}
}
void test_AsyncLogging()
{
const int n = 3*1024*1024;
for (int i = 0; i < n; ++i) {
LOG_INFO << "Hello, " << i << " abc...xyz";
}
}
void asyncLog(const char* msg, int len)
{
AsyncLogging* logging = getAsyncLog();
if (logging)
{
logging->append(msg, len);
}
}
int main(int argc, char* argv[])
{
printf("pid = %d\n", getpid());
AsyncLogging log(::basename(argv[0]), kRollSize);
test_Logging();
sleep(1);
g_asyncLog = &log;
Logger::setOutput(asyncLog); // 为Logger设置输出回调, 重新配接输出位置
log.start();
test_Logging();
test_AsyncLogging();
sleep(1);
log.stop();
return 0;
}
可以发现,在调用Logger::setOutput设置输出回调前,默认输出位置是stdout(见defaultOutput),而设置了输出位置为自定义asyncLog后,每当Logger要输出log消息时,就会通过asyncLog调用预先设置好的g_asyncLog的append()函数,将log消息输出到AsycnLogging的Large Buffer中。
从这里也可以发现,muduo日志库AsycnLogging类有个bug:AsycnLogging并没有同步设置一个flush函数,这样Logger::flush调用的其实还是默认的flush到stdout,并不能跟AsycnLogging::append()同步。当然,这不是什么难事,直接为其添加一个自定义flush()即可。
[======]
小结
1)AsyncLogging 提供多个Large Buffer缓存多条log消息,前端需要在重新配接输出位置后,将每条log消息输出到Large Buffer中。后端线程也是由AsyncLogging 负责维护。
2)LogFile 提供日志文件操作,包括滚动日志文件、写日志文件。
3)AppendFile 封装了最底层的的写文件操作,供LogFile使用。
[======]
参考
https://blog.csdn.net/luotuo44/article/details/19252535
https://docs.microsoft.com/en-us/previous-versions/af6x78h6(v=vs.140)?redirectedfrom=MSDN