作业地址:http://www.cnblogs.com/easteast/p/7604534.html
1)我和我的队友
2)我的Github地址:Github
3)生成的数据:input_data.txt
部分数据截图:

数据生成原理以及考虑的因素:
数据主要是生成标签和学生的空闲时间段,学生和部门的编号取值是依次递增的,所以在定义的时候先自定义10个标签,部门的活动时间和学生的空闲时间也是自定义一天中的4个时间段,然后搭配上一周七天的时间进行随机匹配。

定义:
- 定义两个结构体学生和部门
- 部门中包含自身的编号、招生人数、标签以及活动时间
- 学生中包含学生编号、空闲时间、自身兴趣标签、意愿部门等等。
实现:
- 编号都可以按照一定的顺序递增
- 部门招收人数通过随机函数可以定义在10-15人之间
- 在标签方面,采用二进制的方式来存储信息,随机生成4-6个部门标签
- 部门活动时间采用与标签类似的方法,定义一个二维数组,第一个表示当天是否有空,第二个是表示当天有空的时间段在四个时间段中是哪一个
- 在学生信息定制过程中,意愿部门是随机生成1-5个
- 在整个信息定制过程中,rand()函数用的非常频繁,也是生成信息的核心部分。
处理数据:
- 在完成基本的定制数据后,就是将数据处理成json格式,json数据本身处理起来并不是很麻烦,但是用c语言却是第一次,在没有什么头绪的情况下,参考了部分博客,最终选择引用
 的方式,引用头文件,调用里面的函数生成对象
的方式,引用头文件,调用里面的函数生成对象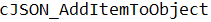 以及数组
以及数组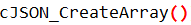 一步步嵌套输出,最终达到要求的数据。
一步步嵌套输出,最终达到要求的数据。
考虑的因素:
- 数据合理:学生的兴趣标签来自部门的兴趣标签;学生的空闲时间一天会有两个时间段,而部门的活动时间一天只能一次。
4)数据建模及匹配程序的思路及实现方式
模型和思路:
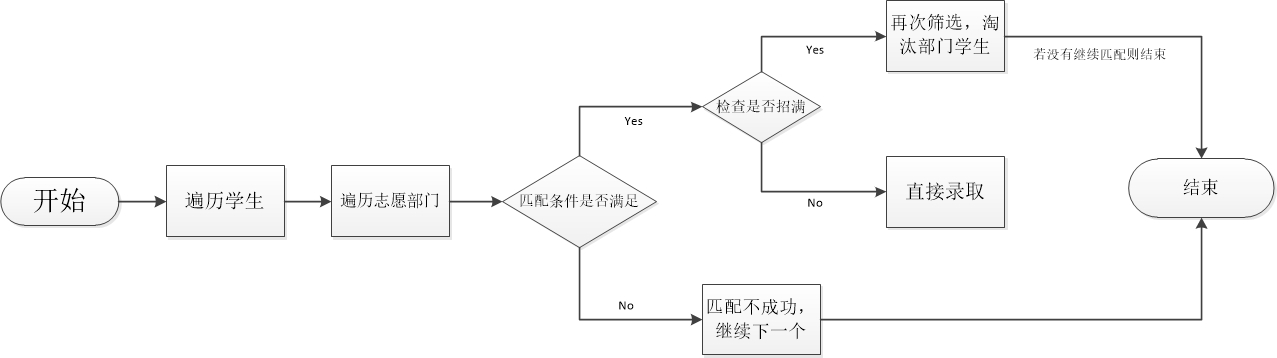
实现:
- 读取文件中的数据并解析,将整体文件保存成字符串,从中取出有用的数据存起来。
- 在匹配中利用时间和标签初步筛选对应的符合学生,时间匹配是利用字符串函数截取有效的时间,将学生的时间和部门的时间比较是否存在包含关系,即可判断是否产生时间冲突。标签的匹配和信息的存储主要是由队友实现,用的是结构体指针,大致的思路就是分别定义部门和学生的结构体,部门的里面有部门编号,纳新人数,已收人数和指向学生结构体的指针,学生的里面有学生在遍历时出现的顺序以及和部门相同的标签个数。开个20大小的部门结构体数组,遍历学生的时候可以纳入就malloc一个学生结构体,初始化有关信息,接到相应部门后面。
- 用一个数组flag[300]存取是否学生被录取信息,如果录取就存为1,否则就是0,最后输出未被录取的flag=0的unlucky-sudent也很好理解。
5)遵循的代码规范
代码规范:
- 变量命名
- 代码段对齐
- 加上适当的注释
- 写上一段代码后可以利用print来输出结果测试,以便为了后期优化和修正
生成最终Json字符串的代码:
for(i = 0; i < 20; i++) { sp1 = department[i].next; /*生成unlucky_department*/ if(sp1 == NULL) { cJSON_AddItemToArray(unluckyD, cJSON_CreateString(department[i].d_no)); } else { /*生成admitted*/ cJSON *admittedDno, *admittedS; admittedDno = cJSON_CreateObject(); admittedS = cJSON_CreateArray(); cJSON_AddItemToObject(admittedDno, "member", admittedS); while(sp1 != NULL) { cJSON_AddItemToArray(admittedS, cJSON_CreateString(student[sp1->order])); flg[sp1->order] = 1; sp1 = sp1->next; } cJSON_AddStringToObject(admittedDno, "department_no", department[i].d_no); cJSON_AddItemToArray(admitted, admittedDno); } } for(i = 0; i < 300; i++) { if(!flg[i]) { /*生成unlucky_student*/ cJSON_AddItemToArray(unluckyS, cJSON_CreateString(student[i])); } } /*生成输出json字符串*/ char *out = cJSON_Print(rootOut);
6)结果评估
利用作业上提供的input_data.txt用自己的程序匹配结果输出结果如下图:
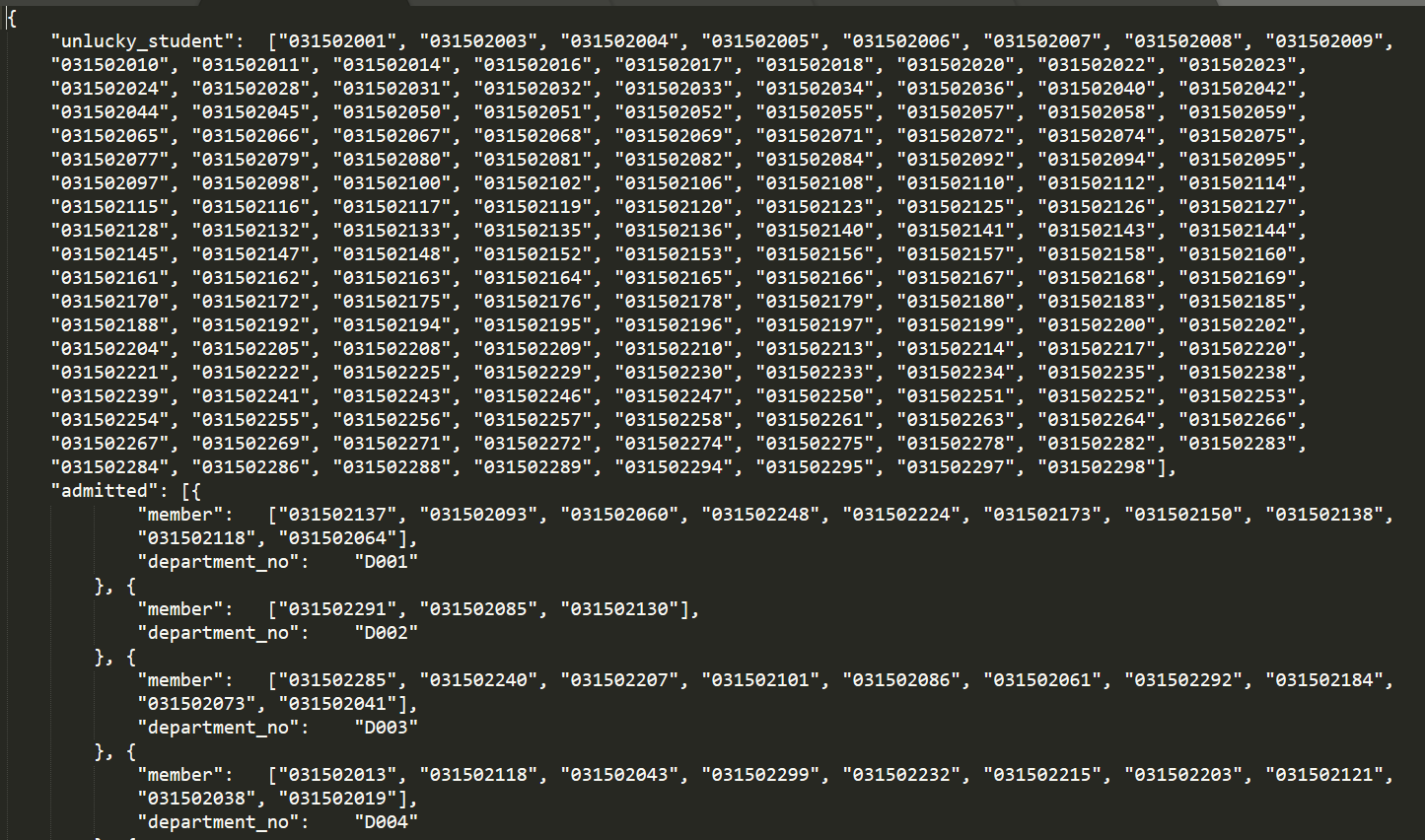
通过助教给出的输入测试样例来测试的话有180多个未被录取的学生,再看看输出的测试样例好像也是180多个,那基本上是可以的,通过自己生成的数据测试,学生录取的会比这个高不少,不过整体上不影响最后的结果,大致的匹配结果对上了就行。
7)结对感受
结对作业已经进行了两次了,从第一次的陌生到慢慢磨合,已经有了一定的默契。这一次的任务跟第一次不一样,需要动手编码,考验自己的代码水平,个人感觉这次作业的难点是在于匹配程序和处理json数据。不过虽然这次作业可供完成的时间周期很长,有一个多礼拜的时间,但是恰逢国庆和中秋两个节日,配合上可能没有很好,大部分都是通过线上交流,不过线上交流有很大的弊端,不是很清楚的表达自己的意思和理解队友的意思,只有后两天才能在宿舍面对面一起讨论还没有解决的一些细节,进度不能够很好把握,好在最后还是讨论出来了最后的结果,不过可能在部分程序优化上没有做的很出色。这次算是比第一次有点进步,下次还要再继续加油吧。