使用C#的同学对List应该并不陌生,我们不需要初始化它的大小,并且可以方便的使用Add和Remove方法执行添加和删除操作,但却可以使用下标来访问它的数据,它是我们常说的链表吗?
List<int> ls = new List<int>();
ls.Add(1);
Console.WriteLine(ls[0]); //输出 1
先简单回顾一下链表的概念。
什么是链表
链表是一种线性表数据结构,在内存中它可以是非连续的,通过在每个结点中使用指针存储下一个结点的地址来实现逻辑顺序。一个结点由两部分组成:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
链表由很多种类,常见的有:单链表、双链表和循环链表,它们实现的原理差别不大,相对于单链表只是多添加了一些特定的功能,所以今天主要讲解最简单、最常用的单链表。
单链表添加、删除结点
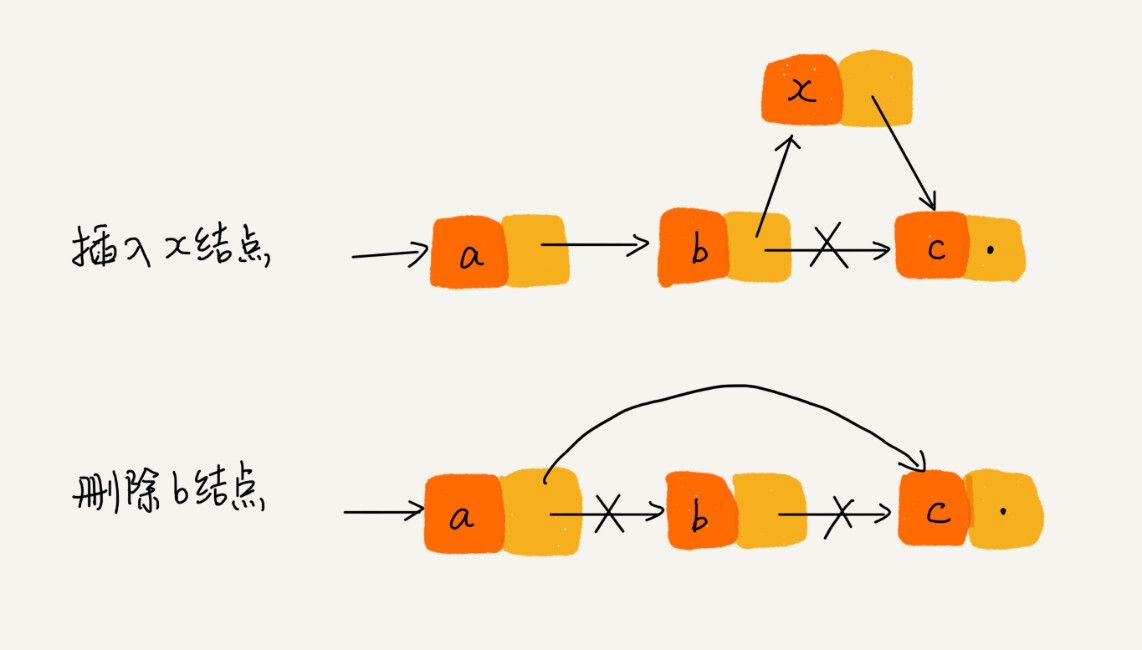
单链表查找指定结点
数组可以通过下标和寻址公式使用O(1)的时间复杂度来访问指定结点,但是由于链表结点在内存中可以是非连续的,无法通过寻址公式计算对应的内存地址,所以要查找一个结点就只能依次遍历,时间复杂度为O(n).
C#中的List
既然链表不能通过下标访问,那上面例子中ls[0]为什么会输出1呢?
查看源码,首先从它的Add方法开始,在vs中点击f12进入,发现跳转到List类内部的SynchronizedList类中,Add函数定义如下
public void Add(T item)
{
lock (_root)
{
_list.Add(item);
}
}
目前还没有看出什么问题,继续查看 _list.Add方法
public void Add(T item)
{
if (_size == _items.Length)
{
//确保不超出容量,否则会执行扩容操作
EnsureCapacity(_size + 1);
}
_items[_size++] = item;
_version++;
}
_items[_size++] = item这句看起来是不是很眼熟,不就是向数组中添加一个元素嘛。为了严谨,我们再查看_items是什么
private const int _defaultCapacity = 4;
private T[] _items;
private int _size;
private int _version;
果不其然,_items就是一个泛型数组,并且还有_size、_version等其他字段
原来List其实并不是链表,在内存中它也是使用数组来进行存储的,只是对添加、删除等操作进行了封装,并且使其能够“自动扩容”。
LinkedList链表
这才是C#中真正的链表,不过它不是最简单的单链表,而是一个双链表。单链表只有一个指针结点指向它的下一个元素,而双链表中每个结点有两个指针结点,一个指向它的下一个元素,另一个指向它的上一个元素。

下面是LinkedListNode的部分源码,可以看到它包含一个next指针和一个prev指针。
internal LinkedList<T> list;
internal LinkedListNode<T> next;
internal LinkedListNode<T> prev;
具体怎么使用,这里就不具体讲解了,看官方文档也比较容易理解。
链表和数组的区别
ok,现在我们对数组和链表都有了一定程度上的了解,那能不能归纳出它们之间有哪些区别呢?对数组有不清楚的地方,可以查看文章
-
从逻辑结构上看,它们都是属于线性表这个数据结构
-
从内存上来看,数组是顺序存储,占用一块连续的内存,大小固定,扩容成本大;链表是链式存储,也就是非连续的,并且因为它多了一个指针,所以不存在大小限制,天然支持动态扩容,但占用的内存也更大。
-
访问操作:数组可以支持“随机访问”,O(1)的时间复杂度;链表需要按顺序逐个访问,O(n)的时间复杂度.
-
添加和删除操作:数组的时间复杂度为O(n); 链表的时间复杂度为O(1)
-
操作系统内存管理方面,借助CPU的缓存机制,可以预读数组的内容,所以访问效率更高,而链表则不行。
总结