| 这个作业属于哪个课程 | 软件工程 https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 对第一次个人编程作业进行总结 |
| 学号 | 031802219 |
| 使用语言 | Java |
一. PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 30 | 80 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 40 | 30 |
| Coding | 具体编码 | 400 | 300 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 220 |
| 合计 | 880 | 1055 |
二. 解题思路
本次题目的要求是制作一个程序统计和分析 GitHub 的用户行为数据,数据规模在 10 GB 以下,以 json 格式给出。一开始拿到这题,我想的是直接使用嵌入式数据库,初始化时将数据插入数据库,后面的查询直接使用 sql 语句,但是经过查询后发现,嵌入式数据库的插入效率普遍较低,对于百万级数据的插入会非常慢,因此直接放弃。之后就采用了常规思路,将统计结果存储在 json 文件中,使用时直接解析 json 文件。
1. 项目任务分解及技术学习和选型
- 这次的任务可以分解为五个步骤: 命令行参数解析, json 文件的读取, 数据统计, json 文件的存储和查询。以前写代码的时候没有用到过命令行参数,所以先上网寻找了解析命令行参数的方法,查到了 Apache 的 Commons-cli 这个库可以用来解析命令行,主要是花时间学习了这个库解析命令行的方法。此外,因为我之前只用过 Maven, Gradle 只在某一个别人用 Gradle 配置好的这个项目里用过(还几乎不用额外配置), 所以还花了一些时间去学习Gradle的配置。 因为 Java 本身的 IO 流比较复杂,所以文件的 IO 选用了 Apache 的 Commons-io。 json 的解析则采用了速度较快的 fastjson 库 (fastjson 库因为其各种远程漏洞层出不穷而饱受争议,但这次的项目并不需要联网,所以,不用考虑这方面的风险)。后面两个库因为我平时接触的比较多,所以看着 api 文档就可以开始编码,不需要花费太多时间进行学习
2. 具体思路
- 通过 Commons-cli 解析命令行参数后调用对应的方法。 如果是 init 方法就通过 Commons-io 读取json 文件并将结果暂存在 HashMap 中,待全部统计完毕后, 将 HashMap 序列化为 json, 并存储到文件中。如果是查询操作,就读取对应的存储结果的 json 文件进行解析。
三. 设计实现过程
整个项目进行了一轮的迭代开发。初始版本为单线程版本,目前的版本为多线程优化版本。
1. 单线程版
为了完成最基本的任务要求,项目最初采用了较为简单的单线程模型。单线程的代码结构也较为简单,只有 Main 和 Result 两个类, 其中前者负责所有的业务逻辑,后者只是单纯的用于数据存储的数据类。
- 遇到的一些困难
- 项目最初的时候还设计了一个实体类用于存放用户名和仓库名作为 HashMap 的键,存储的时候都是正常的,但是无法进行反序列化。 在百度查询以后,有几个博客提到 fastjson 反序列化的时候键不能是对象,因此,我就删去了这个类,直接使用了 用户名 + "_" + 仓库名 作为 HashMap 的键。
2. 多线程优化版
在完成单线程版本并进行测试后,我开始了多线程版本的迭代,相比于之前的版本,代码复杂度有较为明显的上升,因此,对代码进行了更多模块化的设计,详见代码结构
-
代码结构
- Main: 整个项目的入口类,init() 方法和三个查询方法也在该类中实现
- Result: 暂存统计结果的数据类,记录着四种事件的数量
- ThreadPoolFactory: 自定义的线程池工厂,通过工厂方法生产线程池
- FileHandler: json 文件的解析类,继承了 Runnable 接口, 作为提交给线程池的任务
-
设计思路:这里主要是 init() 方法的设计思路。首先获取文件夹下的 json 文件数量,若数量大于0,则通过工厂方法创建线程池,对于每一个 json 文件,实例化一个 FileHandler ,并提交给线程池。 待所有任务执行完毕后,将暂存在 ConcurrentHashMap 中的数据序列化为 json, 并转存到文件中
-
关键流程图(init() 方法)
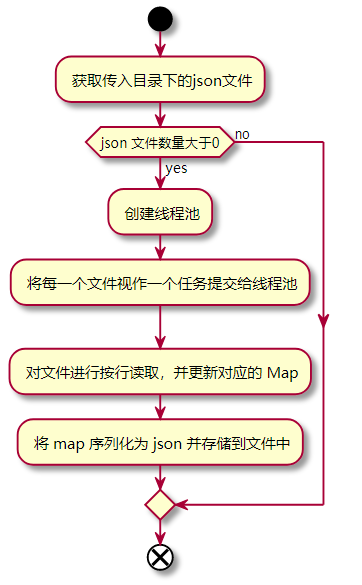
-
遇到的困难
详见下面的性能优化
四. 代码说明
1. main() 方法
public static void main(String[] args) throws Exception {
CommandLineParser parser = new DefaultParser();
Options options = new Options();
options.addOption("i", "init", true, "init");
options.addOption("u", "user", true, "user");
options.addOption("e", "event", true, "event");
options.addOption("r", "repo", true, "repo");
CommandLine commandLine = parser.parse(options, args);
if (commandLine.hasOption("i")) {
// 初始化事件
init(commandLine.getOptionValue("i"));
} else {
String user = commandLine.getOptionValue("u");
String repo = commandLine.getOptionValue("r");
String event = commandLine.getOptionValue("e");
if (commandLine.hasOption("u") && commandLine.hasOption("e") && commandLine.hasOption("repo")) {
// 查询每一个人在每一个项目的 4 种事件的数量。
int result = countByUserAndRepo(user, repo, event);
System.out.println(result);
} else if (commandLine.hasOption("u") && commandLine.hasOption("e")) {
// 查询个人的 4 种事件的数量。
int result = countByUser(user, event);
System.out.println(result);
} else if (commandLine.hasOption("r") && commandLine.hasOption("e")) {
// 查询每一个项目的 4 种事件的数量
int result = countByRepo(repo, event);
System.out.println(result);
}
}
}
- 主方法通过 Commons-cli 提供的 DefaultParser 类和 Options 类进行参数的解析,并根据参数解析的结果调用不同的方法。
2. init() 方法
public static void init(String path) throws IOException, InterruptedException {
File Dir = new File(path);
// 获取后缀是json格式的文件列表
File[] files = Dir.listFiles(file -> file.getName().endsWith(".json"));
if(files == null){
throw new FileNotFoundException();
}
ThreadPoolExecutor pool = ThreadPoolFactory.getPool();
CountDownLatch countDownLatch = new CountDownLatch(files.length);
for (File file : files) {
pool.execute(new FileHandler(file, countDownLatch));
}
// 利用 CountDownLatch 实现线程同步
countDownLatch.await();
String s1 = JSONObject.toJSONString(map1);
String s2 = JSONObject.toJSONString(map2);
String s3 = JSONObject.toJSONString(map3);
// 将json写入文件
FileUtils.writeStringToFile(new File("out1.json"), s1, "UTF-8");
FileUtils.writeStringToFile(new File("out2.json"), s2, "UTF-8");
FileUtils.writeStringToFile(new File("out3.json"), s3, "UTF-8");
}
- init() 方法主要负责读取传入路径下面的文件, 若 目录下的 json 文件数目大于 0,则创建线程池(ThreadPoolFactory.getPool() 方法),之后,为每一个 json文件创建一个任务, 并送入线程池执行。线程间的同步使用了 CountDownLatch 这个类,主线程调用了它的 await 方法,每次执行完成一个任务, CountDownLatch 值减1,只有当它的值为 0 的时候才不会阻塞主线程,从而达到线程的同步。当读取完毕后,将 map 反序列化为 json,并进行存储。
3. FileHandler 的 run() 方法
@Override
public void run(){
LineIterator it = null;
try {
// 按行读取防止 OOM
it = FileUtils.lineIterator(file, "UTF-8");
} catch (IOException e) {
e.printStackTrace();
countDownLatch.countDown();
return;
}
try {
while (it.hasNext()) {
String line = it.nextLine();
JSONObject jsonObject = JSONObject.parseObject(line);
String type = jsonObject.getString("type");
if (Main.attention(type)) {
// 解析json
String userStr = jsonObject.getJSONObject("actor").getString("login");
String repoStr = jsonObject.getJSONObject("repo").getString("name");
Main.map1.compute(userStr, updateResult(type));
Main.map2.compute(repoStr, updateResult(type));
Main.map3.compute(userStr + "_" + repoStr, updateResult(type));
}
}
} finally {
LineIterator.closeQuietly(it);
countDownLatch.countDown();
}
}
- FIleHandler 实现了 Runnable 接口,作为提供给线程池的任务。在 run() 方法中,通过 LineIterator 实现对 json 文件的读取,该类是通过流对 json 文件进行一行一行的读取,而不会一次性将所有文件读到内存中。之后, 利用 fastjson提供的静态方法解析 json,并使用 ConcurrentHashMap 的 compute() 方法实现对值的原子更新。
五. 单元测试
1. 单元测试概述
单元测试里对初始化和三个查询方法均进行了测试。每个测试均进行了正常使用的和值为空的分支测试。
- 测试类的方法

- 测试截图

2. 单元测试覆盖率
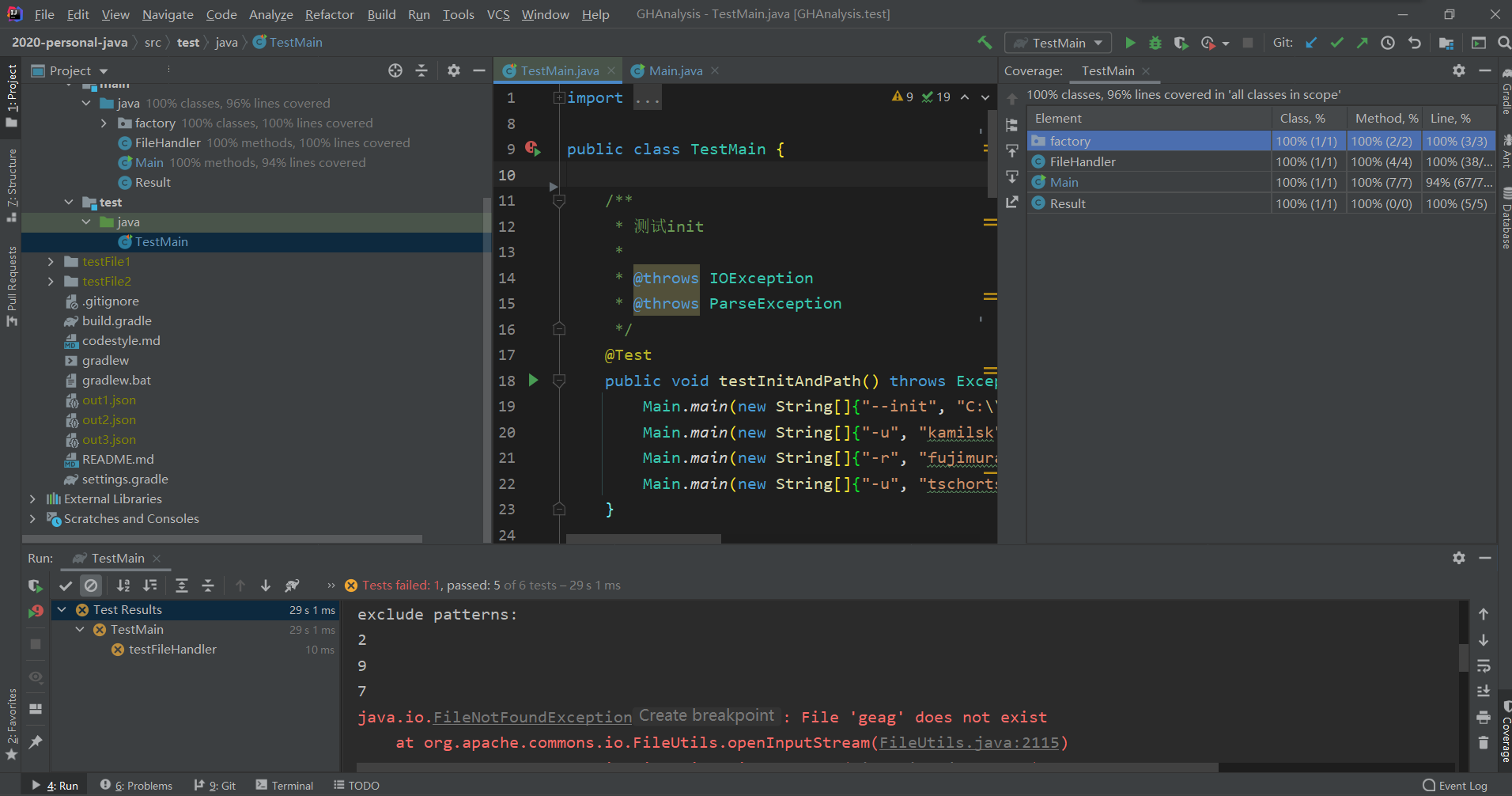
- 可以看到单元测试的覆盖率达到了 90% 以上
- 失败的那个测试方法实际上是符合预期的。失败原因是因为在方法中抛的异常没有转交到最外层进行处理,导致 junit 认为测试失败,事实上这个测试是正常的。
六. 性能优化及性能测试
- 使用的测试数据目录下有 24 个 json 文件,总大小约为 500 MB
- 项目耗费的时间主要集中在 init() 方法,因此下述的时间也仅包括运行 init() 方法所费时间
1. 单线程性能

在单线程环境下,跑完测试数据大约需要 3600ms ~ 4000ms
2. 多线程优化及遇到的困难
- 多线程部分的数据集额外使用了一个自己模拟的超高并发量数据集,以测试线程安全
询问助教后得知评测机是双核的。因此考虑多线程优化。
1. 线程池
- 因为传进来的参数是一个目录,目录里具有的 json 文件数量不定。因此,不能无限制的 new 线程。所以,可以考虑采取线程池。因为 Java 线程池的参数较多,且自带的 Executors 提供的方法不能很好的满足要求,我就自己封装了一个简单的线程池工厂。Java 自带的线程池有一个比较难受的地方就是没有提供异步转同步的方法,因此,必须自己控制线程的同步。这里采取了 CountDownLatch 这个类实现同步,使用也比较简单.

2. Map的并发问题
- Map的并发问题也是本次优化中卡了我很久的一个点。最初想的比较简单,直接把 HashMap 换成了 ConcurrentHashMap,此外没有做任何处理。但是,ConcurrentHashMap 的 put 方法并不保证更新的原子性,还要另做调整。
- 之后把存储结果的 Result 类中的 int 换成了 AtomicInteger. 但是这样做在多个线程先后访问同一个 value 为空并 new 新对象时仍然产生了线程安全问题,而且这样做会导致空间消耗量极大地增长,不能满足任务需求。
- 最后只能求助百度,在百度和 java 的文档中查询了很久之后,我找到了 jdk8 新增的 compute() 方法。这个方法接收一个函数对象,可以通过该函数对象实现对值的原子更新,问题终于解决。

3. 多线程性能测试
- 在多线程环境下, 运行之前单线程使用的大数据集, 时间大约在 1700ms ~ 2000ms 之间,提升幅度约为 100%

- 使用 JConcole 查看内存使用量, 500 MB 的数据集所需内存量在 200 MB 以下. 可以满足任务需求
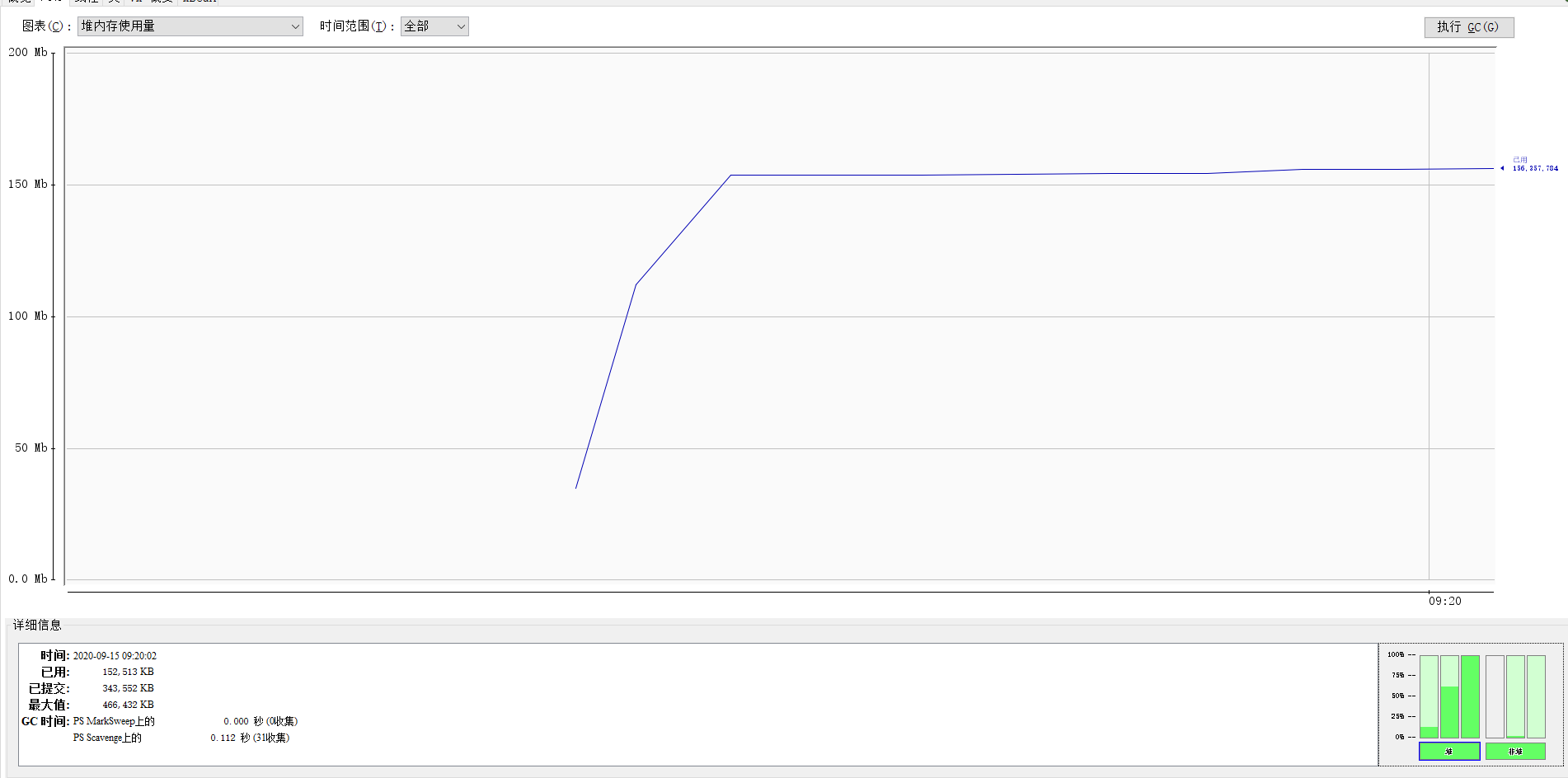
七. 代码规范链接
详见 https://github.com/forestlinji/2020-personal-java/blob/dev/codestyle.md
八. 总结
- 因为我平时课外 Java 自学的比较多,这次作业对我而言难度不是特别大
- 对于测试时间的估计严重不足。原本以为挺快的,结果花了很多时间在写测试用例和改 bug 上(主要是多线程的 bug 比较多)