1、基本概念
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单。
不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀。
至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year attr_test="yes">2009</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year attr_test="yes">2012</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year attr_test="yes">2012</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
<state>
<name>德州</name>
<population>德州</population>
</state>
</data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
2、遍历xml文档
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()#相当于f.seek(0)
print(root.tag)#输出最开始的date#遍历xml文档
for child in root:
print(child.tag, child.attrib
for i in child:
print(i.tag,i.text)
#------------------------------------------------------
---------- country {'name': 'Liechtenstein'}#child.tag,child.attrib
rank 2
year 2009
gdppc 141100#i.tag,i.text
neighbor None
neighbor None
---------- country {'name': 'Singapore'}
rank 5
year 2012
gdppc 59900
neighbor None
---------- country {'name': 'Panama'}
rank 69
year 2012
gdppc 13600
neighbor None
neighbor None
---------- state {}
name 德州
population 德州
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#-----------------------------------
year 2009
year 2012
year 2012
3、修改和删除xml文档内容
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml')
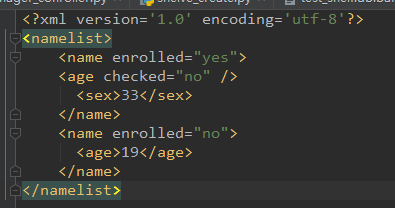
4、自己创建xml文档
import xml.etree.ElementTree as ET new_xml = ET.Element("namelist") name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") sex.text = '33' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age = ET.SubElement(name2,"age") age.text = '19 et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式