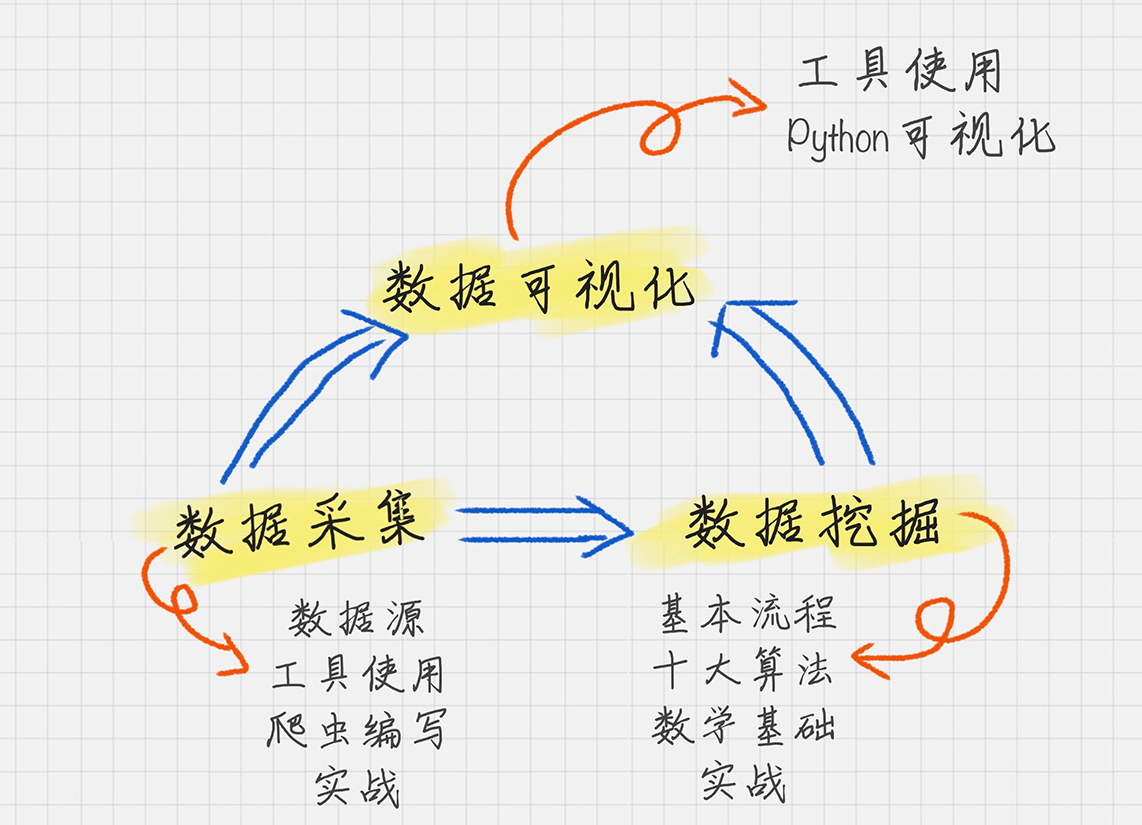
数据分析全景图
1. 数据采集。它是我们的原材料,也是最“接地气”的部分,因为任何分析都要有数据
源。
2. 数据挖掘。它可以说是最“高大上”的部分,也是整个商业价值所在。之所以要进行数
据分析,就是要找到其中的规律,来指导我们的业务。因此数据挖掘的核心是挖掘数据
的商业价值,也就是我们所谈的商业智能 BI。
3. 数据可视化。它可以说是数据领域中万金油的技能,可以让我们直观地了解到数据分析
的结果。
数据采集:
数据挖掘:
数据可视化:
学习数据分析就是从“思
维”到“工具”再到“实践”的一个过程。今天我会从更多的角度来和你分享我的学习经
验,我们可以把今天的内容叫作“修炼指南”。
借用傅盛的话来说,人与人最大的差别在于“认知”,所谓成长就是认知的升级。
很多人存在对“认知“的误解,认为认知不就是概念么?那么你有没有想过,针对同一个
概念,为什么不同的人掌握的程度是不一样的呢?
我们只有把知识转化为自己的语言,它才真正变成了我们自己的东西。这个转换的过程,
就是认知的过程。
先思考模型算法---选择工具---
画图软件SketchBook
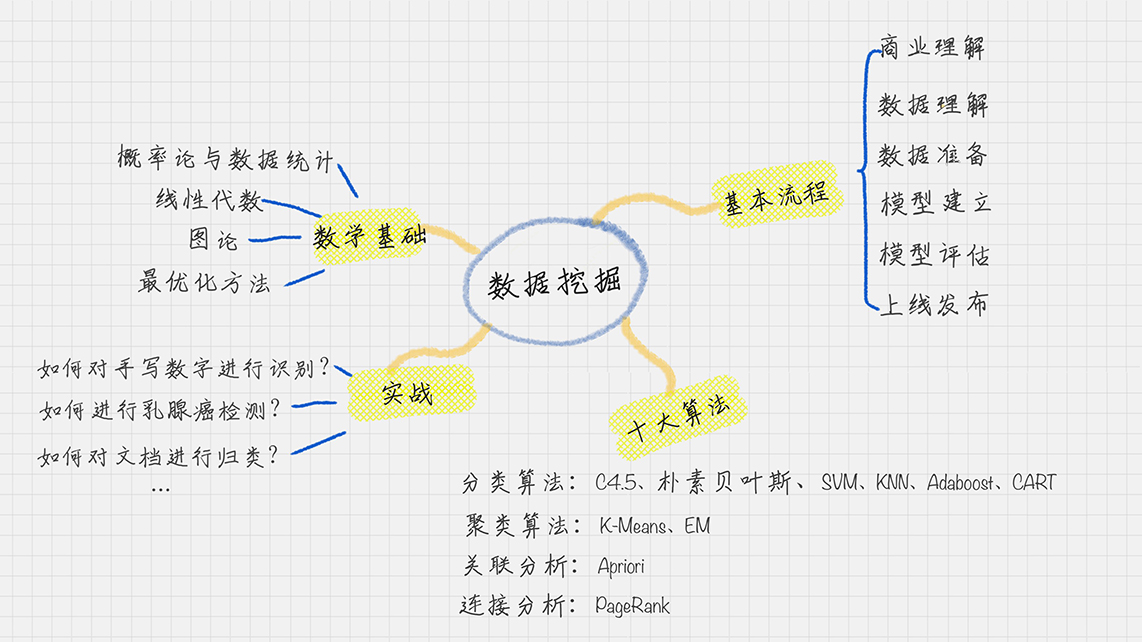
数据挖掘知识清单
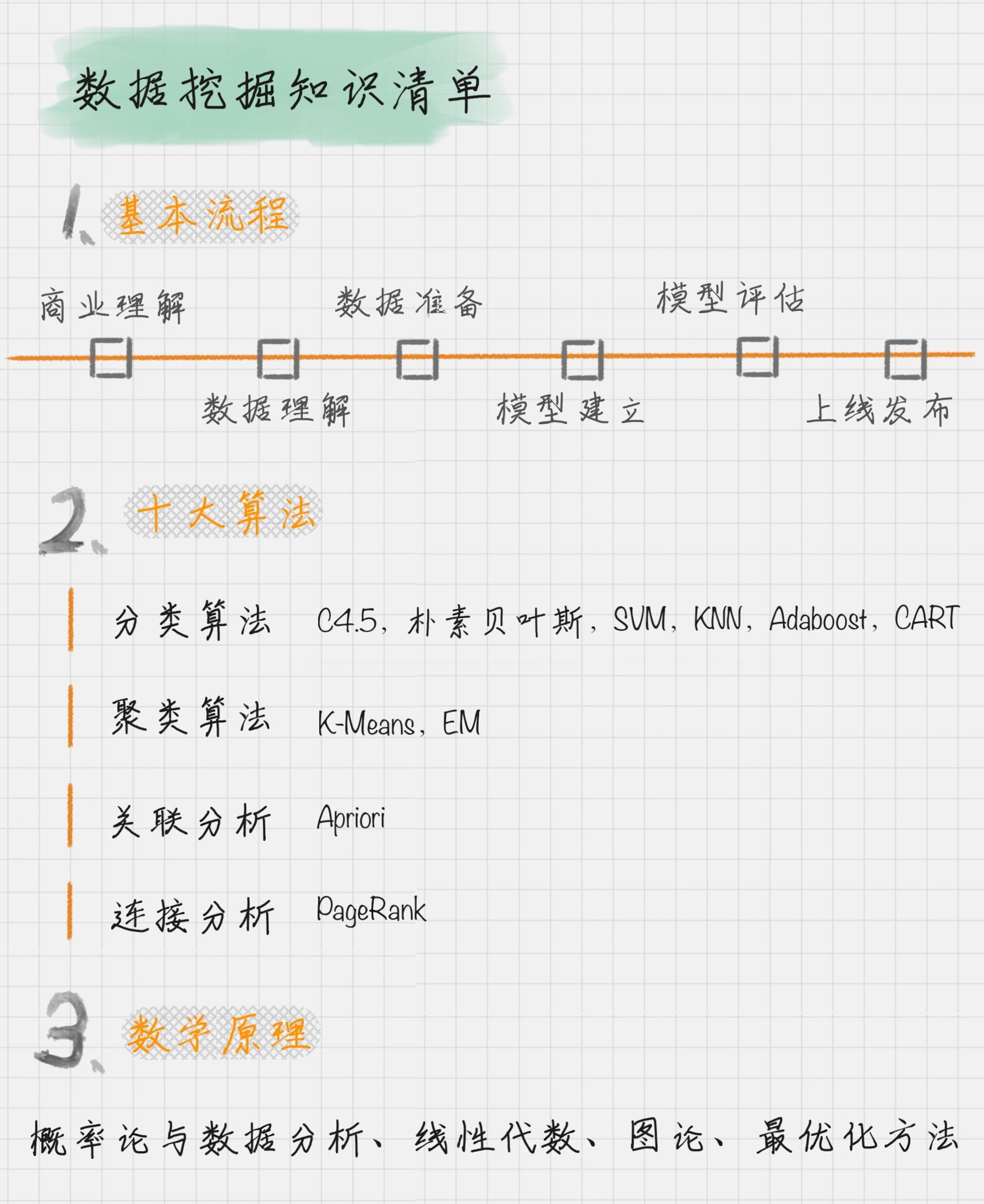
基本流程:

数据分析的基本概念
如今在超市中,我们还能看到不少组合的套装打包在一起卖,比如宝洁的产品:飘柔洗发水 + 玉兰油沐浴露、海飞丝洗发水 + 舒肤佳沐浴露等等。
商品的捆绑销售是个很有用的营销方式,背后都是数据分析在发挥作用。
商业智能 BI、数据仓库 DW、数据挖掘 DM 三者之间的关系


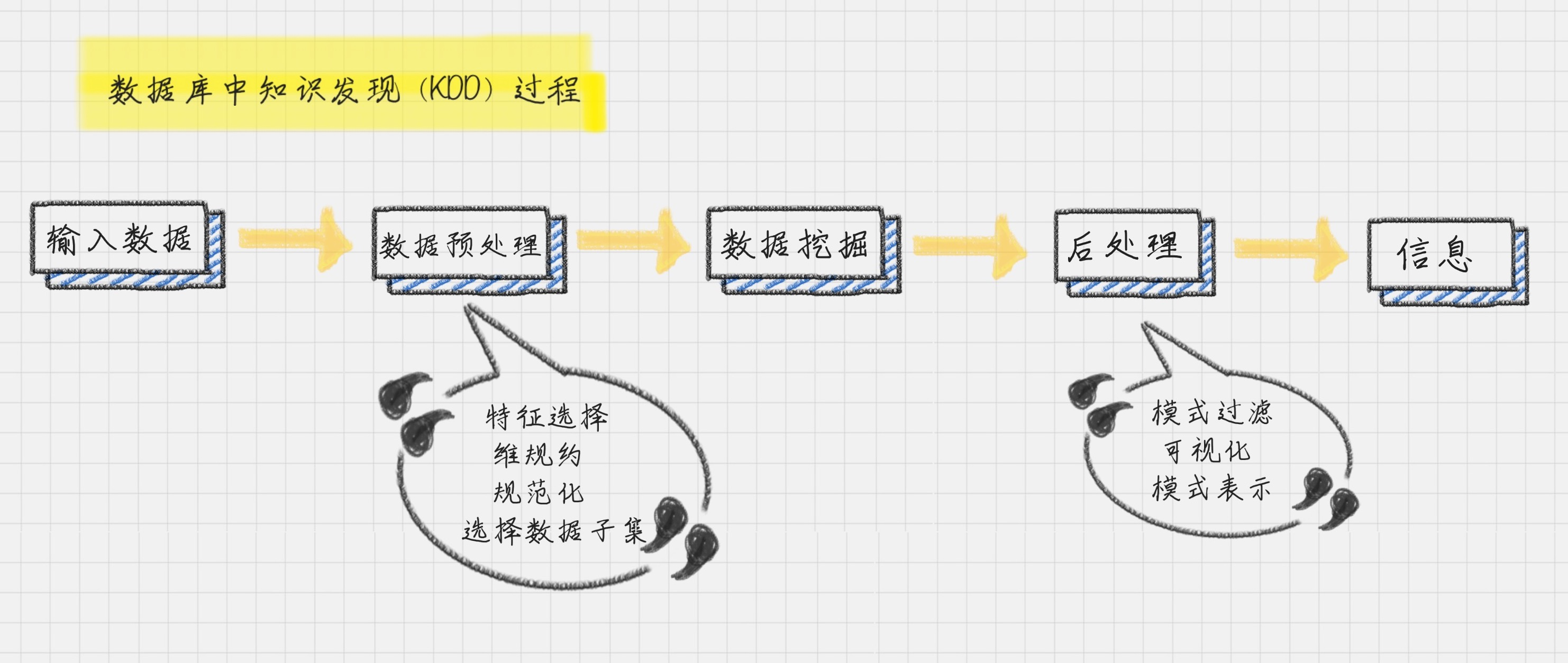
数据挖掘的流程:
数据挖掘的一个英文解释叫 Knowledge Discovery in Database,简称KDD,也就是数据库中的知识发现
在数据挖掘中,有几个非常重要的任务,就是分类、聚类、预测和关联分析。我来解释下
这些概念。
分类属于监督学习,聚类属于无监督学习
(1)分类:
就是通过训练集得到一个分类模型,然后用这个模型可以对其他数据进行分类。
(2)聚类
人以群分,物以类聚。聚类就是将数据自动聚类成几个类别,聚到一起的相似度大,不在
一起的差异性大。我们往往利用聚类来做数据划分。
(3)预测
顾名思义,就是通过当前和历史数据来预测未来趋势,它可以更好地帮助我们识别机遇和
风险。
(4)关联分析
就是发现数据中的关联规则,它被广泛应用在购物篮分析,或事务数据分析中。
上帝不会告诉我们规律,而是展示给我们数据
用户画像:标签化就是数据的抽象能力
如果说互联网的上半场是粗狂运营,因为有流量红利不需要考虑细节。那么在下半场,精
细化运营将是长久的主题。有数据,有数据分析能力才能让用户得到更好的体验。
所以,用户是根本,也是数据分析的出发点。
为业务赋予能量
用户画像的准则
首先就是将自己企业的用户画像做个白描,告诉他这些用户“都是谁”“从哪来”“要去
哪”。
你可以这么和老板说:“老板啊,用户画像建模是个系统的工程,我们要解决三个问题。
第一,就是用户从哪里来,这里我们需要统一标识用户 ID,方便我们对用户后续行为进
行跟踪。我们要了解这些羊肉串的用户从哪里来,他们是为了聚餐,还是自己吃宵夜,这
些场景我们都要做统计分析。
第二,这些用户是谁?我们需要对这些用户进行标签化,
方便我们对用户行为进行理解。
第三,就是用户要到哪里去?我们要将这些用户画像与
我们的业务相关联,提升我们的转化率,或者降低我们的流失率。”
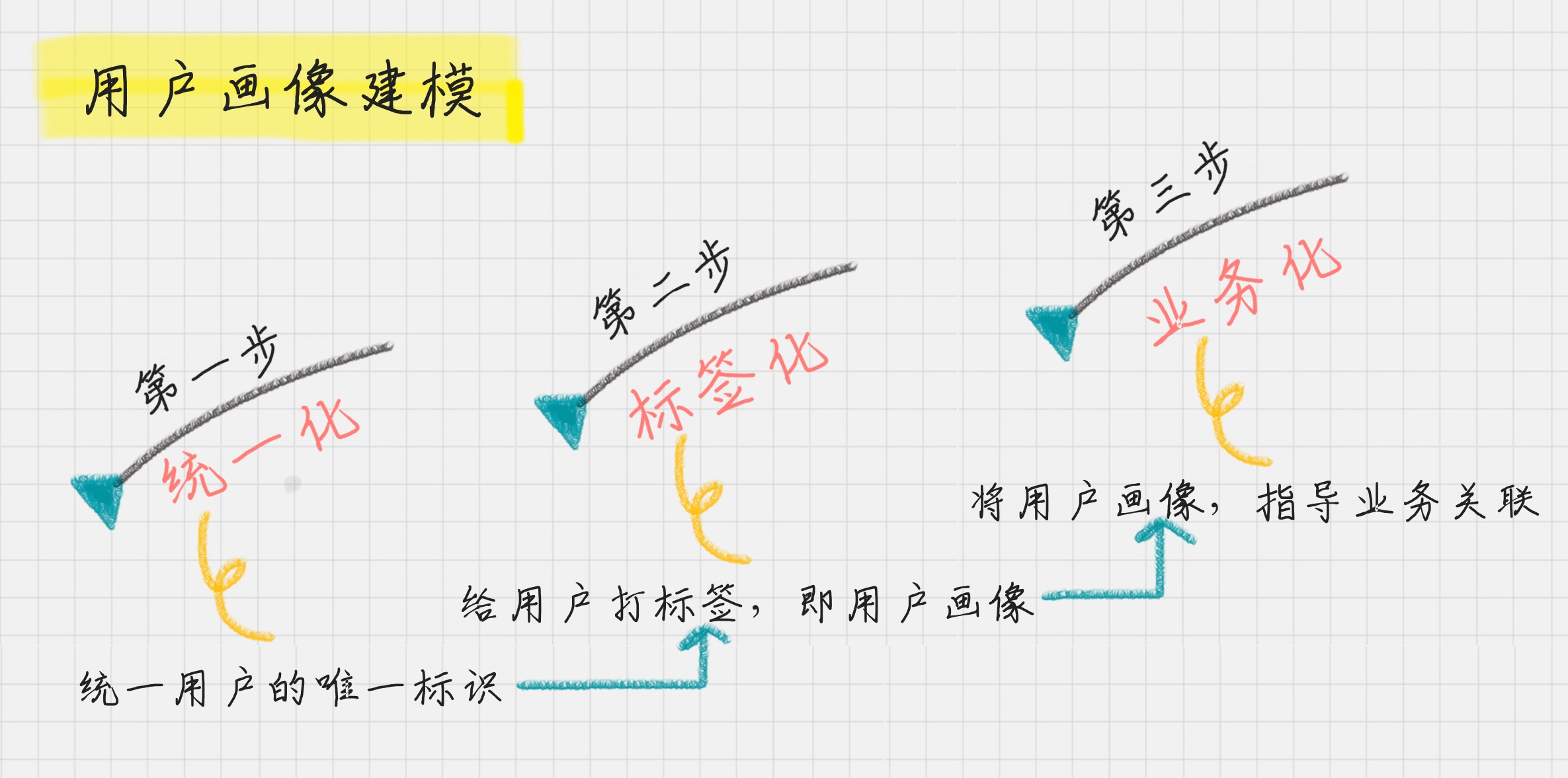
用户唯一标识是整个用户画像的核心。
设计唯一标识可以从这些项中选择:用户名、注册手机号、联系人手机号、邮箱、设备
号、CookieID 等。

其次,给用户打标签。是核心
用户消费行为分析”。我们可以从这 4 个维度来进行标签划
分。
1. 用户标签:它包括了性别、年龄、地域、收入、学历、职业等。这些包括了用户的基础
属性。
2. 消费标签:消费习惯、购买意向、是否对促销敏感。这些统计分析用户的消费习惯。
3. 行为标签:时间段、频次、时长、访问路径。这些是通过分析用户行为,来得到他们使
用 App 的习惯。
4. 内容分析:对用户平时浏览的内容,尤其是停留时间长、浏览次数多的内容进行分析,
分析出用户对哪些内容感兴趣,比如,金融、娱乐、教育、体育、时尚、科技等。
可以说,用户画像是现实世界中的用户的数学建模,我们正是将海量数据进行标签化,来
得到精准的用户画像,从而为企业更精准地解决问题。
最后,当你有了用户画像,可以为企业带来什么业务价值呢?
我们可以从用户生命周期的三个阶段来划分业务价值,包括:获客、粘客和留客。
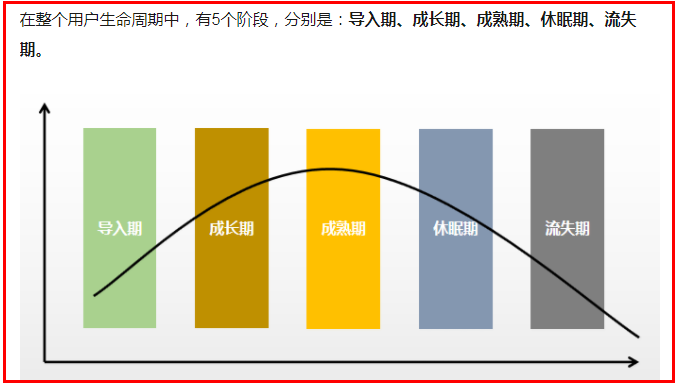
1. 获客:如何进行拉新,通过更精准的营销获取客户。
2. 粘客:个性化推荐,搜索排序,场景运营等。
3. 留客:流失率预测,分析关键节点降低流失率。
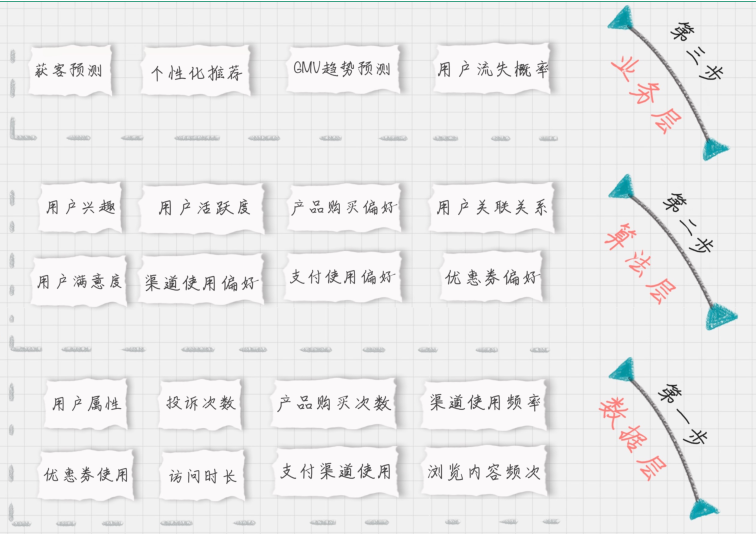
如果按照数据流处理的阶段来划分用户画像建模的过程,可以分为数据层、算法层和业务
层。你会发现在不同的层,都需要打上不同的标签。
数据层指的是用户消费行为里的标签。我们可以打上“事实标签”,作为数据客观的记
录。
算法层指的是透过这些行为算出的用户建模。我们可以打上“模型标签”,作为用户画像
的分类标识。
业务层指的是获客、粘客、留客的手段。我们可以打上“预测标签”,作为业务关联的结
果。
所以这个标签化的流程,就是通过数据层的“事实标签”,在算法层进行计算,打上“模
型标签”的分类结果,最后指导业务层,得出“预测标签”。
分析:
用户画像:标签,是一个什么样的人
给羊肉串连锁店进行用户画像分析
消费者行为分析:
用户标签:性别、年龄、电话,家乡,公司、居住地、婚姻
消费标签:消费口味、喜欢类新,消费均价,团购
行为标签:用餐时间,进店消费,外卖消费,平均点藏用时,访问路径
内容标签:基于用户平时浏览的内容进行统计
朋友圈用户画像:
用户标签:性别、年龄、电话,家乡,公司、居住地、婚姻
行为标签:互动,点攒、评论
关系标签:同学、亲戚、
内容标签:原创,转发,文字、图片、视频
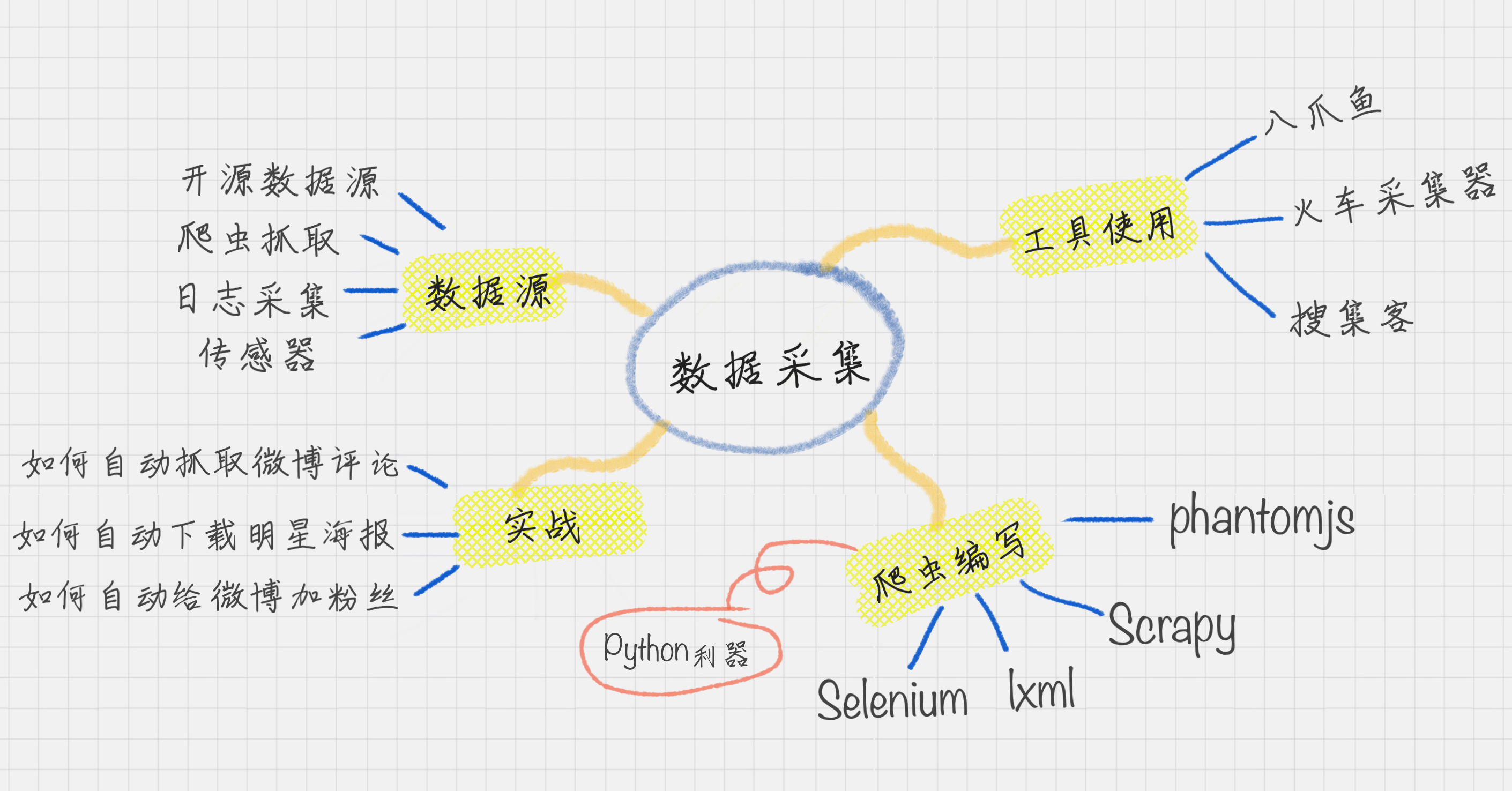
数据如何自动化采集
一个数据的走势,是由多个维度影响的。我们需要通过多源的数据
采集,收集到尽可能多的数据维度,同时保证数据的质量,这样才能得到高质量的数据挖掘结果
这四类数据源包括了:开放数据源、爬虫抓取、传感器和日志采集
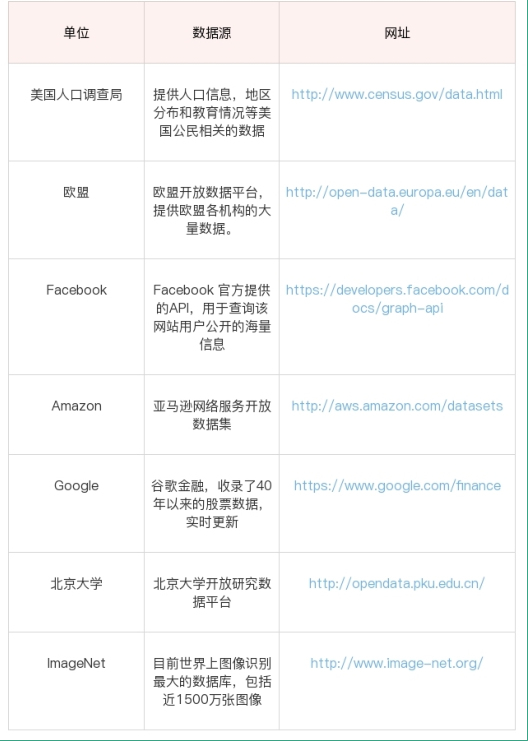
1、如何使用开放数据源
我们先来看下开放数据源,教你个方法,开放数据源可以从两个维度来考虑,
一个是单位的维度,比如政府、企业、高校;
一个就是行业维度,比如交通、金融、能源等领域。
这方面,国外的开放数据源比国内做得好一些,当然近些年国内的政府和高校做开放数据源
的也越来越多。一方面服务社会,另一方面自己的影响力也会越来越大。
2、如何使用爬虫做抓取

第三方爬取网站:
集搜客
3、如何使用日志采集工具

埋点是日志采集的关键步骤,那什么是埋点呢?
埋点就是在有需要的位置采集相应的信息,进行上报。

八爪鱼的基本操作--使用Xpath解析