一、背景
进入多核时代已经很久了,大数据概念也吵得沸沸扬扬,不管你喜欢不喜欢,不管你遇到没遇到,big-data或bigger-data都必须正视.
处理大数据,基本都离不开分布式计算和分布式存储,这其中以hadoop最为使用广泛和经典。

分布式系统,就离不开计算系统、网络系统、文件系统和数据库系统。
这么多系统,之间又是如何协作的呢?
通讯过程又是如何保障高性能的呢?
1.单处理器###
在以前的单核心cpu下,我们要实现文件I/O、网络I/O,可以妥妥的使用单线程循环处理任务。
但是如果想“同时”做点其它事情,就得多开线程,比如:
在下载远程文件的同时,显示下载进度。
2.多线程###
我们会用主线程a来更新界面元素,这里是更新下载进度条,同时用一个额外的线程b去下载远程文件。
3.阻塞###
当需要下载的时候,我们必须使a阻塞,否则,我们的下载线程b将无法获得cpu时间。
而当需要更新界面时,我们必须使b阻塞,原因也是为了获得cpu时间。
阻塞:使一个线程进入阻塞或等待的状态,释放它所占有的cpu时间.
阻塞的原因,是因为任何操作,无论是更新界面还是下载文件(网络I/O+磁盘I/O),都会转化成为一条一条cpu可以执行的指令,而这些指令的读取、执行都需要消耗cpu的时钟周期。
事实上,我们可以使用类似wait、await、sleep、read、write等操作使当前调用的线程进入阻塞。
显然
阻塞的目的是
1.当前有更重要的事情要交给别的线程来做.
2.调用线程可能面临一个长时间的I/O操作,占据cpu时间显然是一种浪费.
3.同步需求.
虽然用户看起来是下载文件和更新界面“同时”运行,但实际上,任何一个时刻,在单核心cpu环境下,都只有一个线程会真正的运行,所以多线程之间是“并发”而非真正的“并行”。
4.多处理器###
单核心时代早已过去,多核、多处理无论在企业级服务器还是家用桌面电脑、平板和智能手机上都已经是主流。
注:图片来源intel

如果多处理器的核心是真实的而非虚拟化的,那么多线程就可以真正的并行。

可以看到,(t_1、t_2、t_3)的运行时间可以出现重叠.
但实际上,操作中运行的进程远不止几个,那么相应的线程数会远大于cpu的核心数,所以即使上图中假设是4核心处理器,那么真正能同时执行的线程也只有4个,所以也会出现运行的中断,即阻塞。
二、高性能通讯
在了解了多核、多处理器、多线程、阻塞的概念后,我们来看看通讯,显然,任何一个通讯框架都试图追求高性能、高吞吐、高tps能力。
但是,任何一个来自用户或其它服务器的请求都不可能只是要求一个简单的echo返回,所以请求执行的任务几乎都会包含:
1.计算 比如MapReduce、SQL、坐标计算等等.
2.I/O 访问数据库、磁盘、缓存、内存或者其它设备.
站在用户的角度,总是希望自己的请求会被优先、快速的响应,而站在服务器的角度,总是希望所有的请求同时能够被处理.
1.同步/异步###
同步的意思如字面一般简单:
同步就是多个对象的步调一致,这种步调是一种约定。
比如,时间上约定10点同时到达,先到达的就会等待。
比如,逻辑上约定必须取得结果,调用才能返回。
比如,资源上约定read和write不可同时进行,但read之间可同时执行。
下面的图显示了时间上的同步约定:

而异步,就是步调无须一致:
异步,就是多个对象之间的行为无须遵守显式或隐式的约定。
比如,老婆没到,你也可以进场看电影。
比如,可以不必等结果真正出现,就立即返回。
比如,read和read之间可以乱序访问文件或资源。
2.同步与阻塞的关系###
服务器的能力是有限的,为了能够满足所有用户的请求,服务器必须能够进行高并发的处理。这一点可以通过两种方式达到:
1.单线程 + 异步I/O. (node.js)
多线程的建立是需要开销的,线程数越多,线程上下文的切换就会越频繁,而异步I/O在“理想”情况下不会阻塞,调用完毕即返回,通过回调callback或事件通知来处理结果.
2.多线程 + 异步或同步I/O. (nginx)
单线程的一个缺点就是无法充分利用多处理器的并行能力,同时异步I/O不是在任何情况下都是真正异步的。
比如文件在缓存中(通过映射到内存)、文件压缩、扩展、缓冲区拷贝等操作,会使得异步I/O被操作系统偷偷地转换为同步。
假如文件已经在缓存中,使用同步I/O的结果会更快。
这里你可能会疑惑,同步看起来很像“阻塞”,但仔细看本篇中对它们的说明,就会发现:
阻塞是调用线程的一种状态或行为,它的作用是放弃占用的cpu.
同步是多个线程之间的协调机制,它的作用是为了保证操作的顺序是正确可预期。
同步可以使用阻塞来实现,也可以使用非阻塞来实现。
而有的情况下,因为同步是不得已的行为,比如要hold住一个来自其他服务器的session,以防止立即返回后的上下文失效,我们往往会这样:
//还没有结果
bool haveResponse = false;
//调用异步I/O,从远程数据库执行sql,并返回结果
rpc.callAsync(database,sql,
function(resp){
response = resp;
haveResponse = true;
});
//通过循环阻塞来hold住这个线程的上下文和session
while(!response){
//这里将阻塞100毫秒
if(!response){
await(100);
}else{
break;
}
}
//通过请求的session返回结果
httpContext.currentSession.Respond(response);
这是一种 多线程 + 异步 转为了 多线程 + 同步的方式,因为Web应用服务器处理session时采用的往往是线程池技术,而我们又没有服务器推(server push)或者用户的调用请求一直在等待结果,所以,即使访问数据库采用的是异步I/O,也不得不通过这种方法来变成同步。
与其如此,还不如:
//调用同步I/O,从远程数据库执行sql,并返回结果
//调用时,此线程阻塞
response = rpc.callSync(database,sql);
//通过请求的session返回结果
httpContext.currentSession.Respond(response);
上面的代码,使用了简单的同步I/O模型,因为一般的访问数据库操作是很费时的操作,所以处理当前session的线程符合被阻塞的目的,那么同步调用就被实现为阻塞的方式。
事实上,从用户的角度来看,用户发出请求后总是期待会返回一个确定的结果,无论服务端如何处理用户的请求,都必须将结果返回给用户,所以采用异步I/O虽然是最理想的状态,但必须考虑整个应用的设计,即使你这里使用了异步,别的地方也可能需要同步,如果这种“额外”同步的设计复杂性远高于使用异步带来的好处,那么请考虑“同步/阻塞式”设计。
如果业务逻辑上,要求依赖性调用,比如DAG,那么同步也是必须的。
三、IOCP和epoll
1. IOCP(完成端口)###
windows提供了高效的异步I/O的线程模型,完成端口:

完成端口可以关联很多的文件句柄(这里的文件是广义的,文件、socket或者命名管道都可以是)到一个完成端口上,称为关联完成端口的引用,,这些引用都必须支持(Overlapped I/O,重叠式I/O)。
重叠式I/O是异步I/O的基石,通过进行重叠I/O,可以让调用I/O操作的线程与I/O操作线程并行执行而无须阻塞。
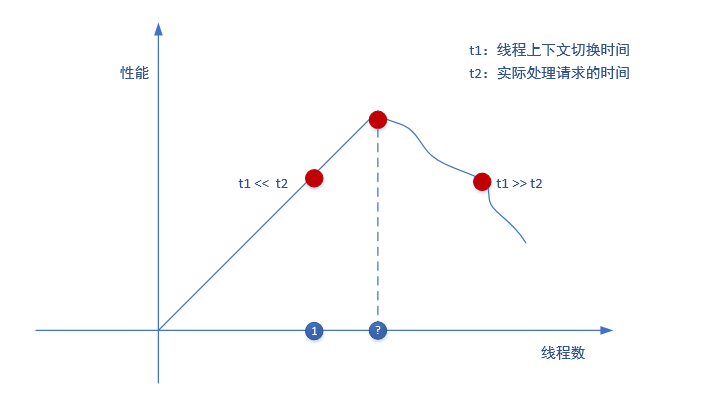
多线程虽然可以充分发挥多处理器的并行优势,但却不是银弹。
当线程数增加,可“同时”处理的请求量上去了,这样吞吐量会很高,但可用于每个用户请求的时间变少,每个用户请求的响应时间随之下降,最后吞吐率下降。
同时,线程的启动和销毁是有开销的,虽然可以通过线程池(ThreadPool)来预先分配一定量的活动线程,但线程越多,其上下文切换(Context Switch)的次数就越频繁。
考虑一种情况:
当线程的栈很大而线程被阻塞的时间很长,操作系统可能会将此线程的堆栈信息置换到硬盘上以节约内存给其它线程使用,这增加了磁盘I/O,而磁盘I/O的速度是非常慢的。
而且,线程的频繁切换也会降低指令和数据的locality(局部性),cpu的缓存命中率会下降,这又加剧了性能的下降。
完成端口的设计目标是:
1.任一给定时刻,对于任一处理器,都有一个活动线程可用。
2.控制活动线程的数量,尽量减少线程上下文的切换。
可以看出,IOCP主要是针对线程模型的优化。
创建完成端口时,需要指定一个Concurrent Value = c的值,来指示:
当活动线程的数量
v >= c,就将其它关联在完成端口上的线程阻塞,直到活动线程的数量v < c.
当一个活动线程进行I/O时,会阻塞,活动线程数量v就会下降.
这一点是IOCP的精髓。
完成端口的原理是:
在创建了完成端口后,将socket关联到这个端口上,一旦socket上的I/O操作完成,操作系统的I/O管理模块会发送一个通知(Notification)给完成端口,并将I/O操作的完成结果(completion packet)送入完成端口的等待队列
WQ,这个队列的顺序是先入先出(FIFO)。
也就是说,调用线程可不比等待socket的I/O操作完成,就立即返回做其它的事情。
而当活动线程的数量下降,小于指定的并发约束(concurrent value)时,操作系统将会唤醒最近被加入阻塞队列
BQ的线程,让它从完成包的等待队列中取出一个最老的I/O结果进行处理。这里可以看出,BQ的顺序是后入先出(LIFO)。
IOCP所谓的异步是:
与完成端口关联的文件(file、socket、named pipeline)句柄上的I/O操作是异步的。
调用线程只负责将socket I/O丢给完成端口,然后就可以做其它事。而无需向同步那样等待。
但是,如果一个调用线程在处理这个从完成队列取出的数据后,又在当前线程进行了其它I/O操作,比如读取文件、访问数据库,那么这个调用线程同样会阻塞,但不是阻塞到完成端口的队列上。
这一点,对数据的处理就涉及不同的业务逻辑需求,I/O线程是否应该与逻辑线程分开,分开后,逻辑线程应该是如何控制数量,如果分开,就要求在拿到数据后,要么另起线程处理数据,要么将数据扔进线程池(Threadpool)。无论是何种方式,都会增加线程上下文切换的次数,反过来影响IOCP的可用资源。
所以,要从应用的实际需求出发,来总体控制整个服务器的并发线程数量,否则,无论多么高效的通讯模型,都会被业务模型(往往需要对文件或数据库的访问)所拖累,那么整个应用的性能就会下降。
2. epoll###
linux上的高效I/O模型则是epoll.
epoll是对select/poll模型的一种改进.
1.既然是对select/poll的改进,就是一种I/O多路复用模型。
2.支持的文件(同样是广义)描述符fileDescriptor巨大,具体多大与内存大小直接相关。
3.wait调用在活跃socket数目较少时,可高效返回。
在传统的select/poll模型中,内核会遍历所有的fileDescriptor(这里只说socket),而不管socket是否活跃,这样,随着socket数目的增加,性能会很快下降。
而epoll模型,采用了向内核中断处理注册回调的方式,当某个socket上的I/O就绪,中断就会发出,接着就会将这个结果推入一个
就绪队列Q中,Q采用单链表实现,所以扩展性是天生的。
同时,由于采用了适宜频繁写的平衡树-红黑树的结构来存储fileDescriptors,所以当需要向fileDescriptors中加入、删除、查找socket时,就会非常高效,另外还有一层内核级页高速缓存。
最后,由于活动的socket比较少时,I/O就绪的中断次数相应减少,所以向
就绪队列Q中插入数据的次数相应减少,当wait操作被调用时,内核会考察Q,如果不空就立即返回,同时通过内存映射来讲就绪的I/O数据从内核态拷贝到用户态,达到少而快的效果。
epoll的主要调用接口如下:
/* 创建可保证size个效率epoll,返回epfd*/
int epoll_create(int size);
/* 设置应当注册的事件类型IN/OUT/ET/LT,并设置用于返回事件通知的events */
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/* epoll进入阻塞,events用于设置返回事件通知的events */
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
边沿触发(ET)####
考虑上面的图,随着时间的增加,高低电平交替变化。

所谓边沿触发,就是当达到边沿(一个临界条件)时触发,如同0到1.
epoll中的边沿触发,是指当I/O就绪,中断到达时,执行对应的回调,将结果推入`等待队列Q`中,之后便不再关心这个结果。
这样导致的结果是,当
wait调用返回时,如果对应的事件没有被处理完,比如读操作没有将buffer中的数据读取完,就返回,将没有机会再处理剩余的数据。
水平触发(LT)####
所谓水平触发,就是每到上边沿时就触发,比如每次到1.
epoll中的边沿触发,是指当I/O就绪,中断到达时,执行对应的回调,将结果推入`等待队列Q`中,当队列被清空后,再次将结果推入队列。
这样的结果是,当
wait调用返回时,如果对应的时间没有处理完,比如写数据,写了一部分,就返回,也会在下次wait中收到通知,从而得以继续处理剩余数据。
水平触发流程简单稳定,需要考虑的事情少,且支持阻塞/非阻塞的socket I/O。
而边沿触发,在大并发情况下,更加高效,因为通知只发一次,但只支持非阻塞的socket I/O。
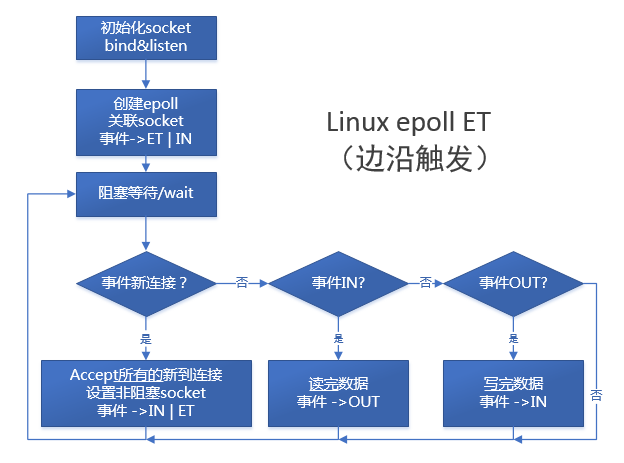
下图是ET方式的epoll简略流程:
【转载请注明出处:版权所有@foreach_break】