- Multihop Attention Networks (MANs)
-
- 以往基于注意力的方法的一个共同特点是,问题由一个特征向量表示,并应用一轮注意力来学习答案的表示。然而,在许多情况下,答案的不同部分可能与问题的不同部分有关。作者根据这一点展开本文的工作,构建一个attention,也就是标题说的multihop attention来获得问题的不同部分的语义,然后再通过sequentional attention获得答案的语义表示;进行多次匹配得出score,最后将score相加得到最终的score表示。
COPY ATTENTION MECHANIC:
《pointing the unknown words》
https://zhuanlan.zhihu.com/p/36368316
https://arxiv.org/pdf/1603.08148.pdf、
《pointer networks》
https://arxiv.org/pdf/1506.03134.pdf
https://www.jianshu.com/p/bff3a19c59be
《How to construct deep recurrent neural networks》
https://arxiv.org/pdf/1312.6026.pdf
《Generating Natural Answers by IncorporatingCopying and Retrieving Mechanisms in Sequence-to-Sequence Learning》
https://aclweb.org/anthology/P17-1019
https://zhuanlan.zhihu.com/p/26826765
MEMORY NETWORK:
https://zhuanlan.zhihu.com/c_129532277
《End-To-End Memory Networks》
https://zhuanlan.zhihu.com/p/29679742
https://arxiv.org/pdf/1503.08895.pdf
《Memory Network》
https://zhuanlan.zhihu.com/p/29590286
《Key-Value Memory Networks for Directly Reading Documents》
https://arxiv.org/pdf/1606.03126.pdf
《Tracking The World State With Recurrent Entity Networks》
https://arxiv.org/pdf/1612.03969.pdf
《Hierarchical Memory Networks》
https://arxiv.org/pdf/1605.07427v1.pdf
https://zhuanlan.zhihu.com/p/30117735
《Hierarchical Memory Networks for Answer Selection on Unknown Words》
https://www.aclweb.org/anthology/C16-1216
《Neural Turing Machines》
https://arxiv.org/pdf/1410.5401.pdf
正文:《Mem2Seq: Effectively Incorporating Knowledge Bases into End-to-EndTask-Oriented Dialog Systems》
https://arxiv.org/pdf/1804.08217.pdf
https://zhuanlan.zhihu.com/p/44110616
introduction
任务型对话系统一般由几个流水线模型组成:语言理解,对话管理,知识查询和语言生成。
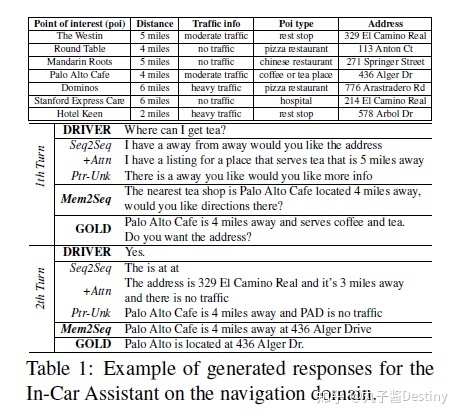
目前现有的
- RNN 编码器-解码器模型:它们可以直接将纯文本对话历史映射到输出响应,并且对话状态是潜在的,因此不需要手工标注状态的标签。
- RNN 编码器-解码器模型+基于attention的复制机构:它们直接从输入源复制单词到输出响应。即使未知标记出现在对话历史中,模型仍然能够生成正确且相关的实体。
存在的问题:
1)因为RNN对于长序列是不稳定的。所以难以有效地将外部知识库信息与RNN隐藏状态相结合。
2)处理长序列非常耗时,尤其是在使用注意力机制时。
所以,基于MemNN,本文提出了Mem2Seq模型,以端到端的方式学习任务型对话。简而言之,Mem2Seq模型使用序列生成框架扩充了现有的MemNN框架,使用全局多跳注意力(multi-hop attention)机制直接从对话历史或知识库中复制单词。
主要贡献:
1)Mem2Seq是第一个将多跳注意力机制与指针网络结合起来的模型,并允许我们有效地结合知识库信息。
2)Mem2Seq学习了如何动态生成查询去控制Memory的访问,可以可视化memory控制器和attention的跳跃之间的模型动态。
3)Mem2Seq可以更快地进行训练,并在几个任务型对话数据集中实现最先进的结果。
model:
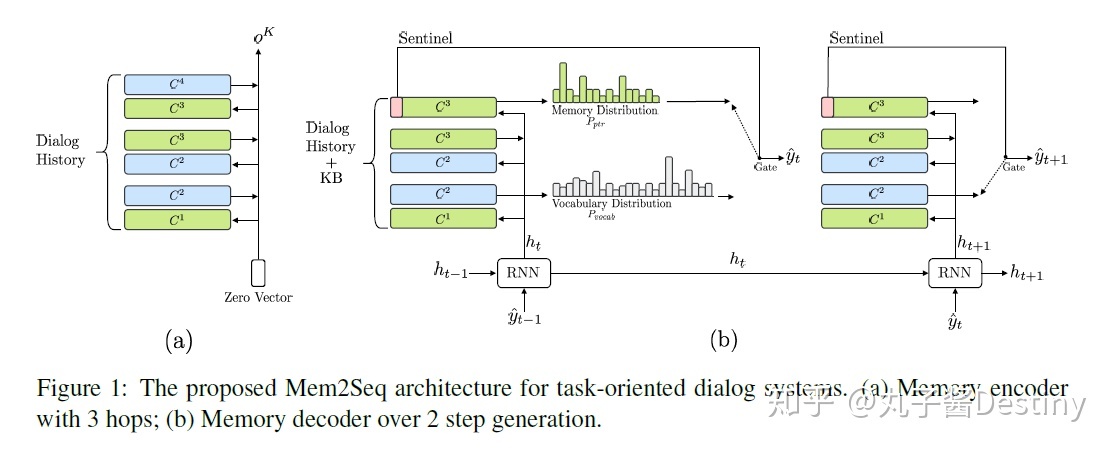
Mem2Seq是第一个结合了multi-hop attention机制和指针网络(pointer network)的生成网络模型。
简单来说,Mem2Seq=MemNN+pointer network,由两个组件组成:memory encoder和memory decoder。如图1所示,MemNN编码器创建对话历史的矢量表示。 然后,存储器解码器读取并复制存储器以产生响应。
实验
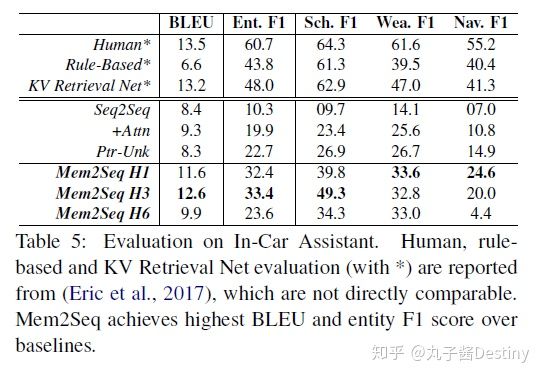
在表5中,我们的模型可以达到最高12.6 BLEU分数。此外,Mem2Seq在Entity F1得分(33.4%)方面显示出有希望的结果,一般来说,远远高于其他基线。 值得注意的是,如Seq2Seq或Ptr-Unk这类在此数据集中的性能尤其差,因为RNN方法编码较长知识库信息的效率非常低,这是Mem2Seq的优势。
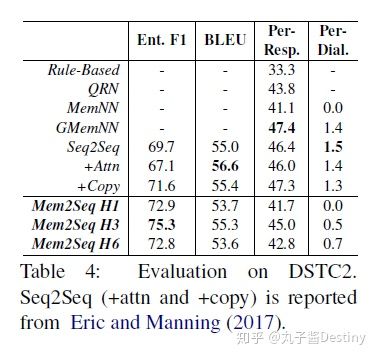
Mem2Seq拥有最高75.3%的Entity F1得分和55.3 BLEU得分。这进一步证实了Mem2Seq在使用多跳机制而不丢失语言建模的情况下可以很好地检索正确的实体。但是可以发现,每个模型的每个响应精度都小于50%,这是因为数据集非常嘈杂,所以很难生成与黄金响应完全相同的响应。
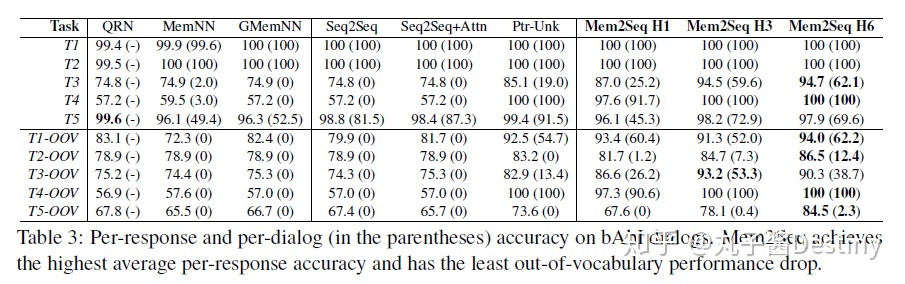
比如,具有6跳的Mem2Seq在T5中可实现每次响应97.9%和每个对话69.6%的准确度,在T5-OOV中达到84.5%和2.3%,这远远超过现有方法。此外,在任务3-5中证明了跳跃的有效性,因为它们需要对知识库信息具有推理能力。请注意,QRN,MemNN和GMemNN将bAbI任务视为分类问题。虽然与我们的生成方法相比,他们的任务更容易,但Mem2Seq模型也仍然可以超越性能。
结论
传统的任务型对话系统需要在系统设计和数据收集方面进行大量的人力工作。另一方面,尽管端到端对话系统还不完善,但它们需要的人为干预少,特别是在数据集构建中,因为原始会话文本和知识库信息可以直接使用而无需大量预处理(例如NER,依赖解析)。在这种程度上,Mem2Seq是一个简单的生成模型,能够将知识库信息与较好的泛化能力结合起来。
本文为任务型对话系统提供了端到端的可训练的Memory-to-Sequence模型。Mem2Seq将端到端memory网络中的多跳注意力机制与指针网络的概念相结合,以结合外部信息。本文显示了模型使用外部知识库信息和预定义词汇表生成相关答案的能力,并将多跳注意机制如何帮助学习记忆之间的相关性可视化。Mem2Seq快速,通用,能够在三个不同的数据集中实现最先进的结果。