json文件hive解析落表
不同于Hive学习小记-(5)表字段变动频繁时用json格式 那种简单存成string再解析,参考:
https://www.cnblogs.com/30go/p/8328869.html
https://blog.csdn.net/lsr40/article/details/103020021
(1)json数据准备,xftp到Linux
# test_json_load
{"student": {"name":"king","age":11,"sex":"M"},"sub_score":[{"subject":"语文","score":80},{"subject":"数学","score":80},{"subject":"英语","score":80}]}
{"student": {"name":"king1","age":11,"sex":"M"},"sub_score":[{"subject":"语文","score":81},{"subject":"数学","score":80},{"subject":"英语","score":80}]}
{"student": {"name":"king2","age":12,"sex":"M"},"sub_score":[{"subject":"语文","score":82},{"subject":"数学","score":80},{"subject":"英语","score":80}]}
{"student": {"name":"king3","age":13,"sex":"M"},"sub_score":[{"subject":"语文","score":83},{"subject":"数学","score":80},{"subject":"英语","score":80}]}
{"student": {"name":"king4","age":14,"sex":"M"},"sub_score":[{"subject":"语文","score":84},{"subject":"数学","score":80},{"subject":"英语","score":80}]}
{"student": {"name":"king5","age":15,"sex":"M"},"sub_score":[{"subject":"语文","score":85},{"subject":"数学","score":80},{"subject":"英语","score":80}]}
{"student": {"name":"king5","age":16,"sex":"M"},"sub_score":[{"subject":"语文","score":86},{"subject":"数学","score":80},{"subject":"英语","score":80}]}
{"student": {"name":"king5","age":17,"sex":"M"},"sub_score":[{"subject":"语文","score":87},{"subject":"数学","score":80},{"subject":"英语","score":80}]}
(2)建表
分析json格式数据源,student字段使用map结构,sub_score字段使用array嵌套map的格式,
这样使用的好处是如果数据源中只要第一层字段不会改变,都不会有任何影响,兼容性较强。
创建表语句如下, 注意row format serde中org.apache.hive.hcatalog.data.JsonSerDe这个json包,这样解析json出错时不至于程序挂掉。
tips:对于解析异常时报错的处理,可以加上一下属性:ALTER TABLE dw_stg.stu_score SET SERDEPROPERTIES ( "ignore.malformed.json" = "true");这里暂不涉及。
sc.sql(""" create table if not exists test_youhua.test_json_load( student map<string,string> comment "学生信息", sub_score array<map<string,string>> comment '成绩表' ) comment "json_学生成绩表" row format serde 'org.apache.hive.hcatalog.data.JsonSerDe' """)
# 这样直接使用JsonSerDe类,是会报错的,因为这个类并没有在初始化的时候加载到环境中,报错如下 AnalysisException: 'org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: MetaException(message:java.lang.ClassNotFoundException Class org.apache.hive.hcatalog.data.JsonSerDe not found);'
(3)JsonSerDe类加载
这里执行ADD JAR ${HIVE_HOME}/hcatalog/share/hcatalog/hive-hcatalog-core....jar. 不同版本的jar包路径可能有些差别
[root@hadoop02 hive]# add jar ../hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar -bash: add: 未找到命令 -- 注意这个add jar是在hive里执行的,而不是bash命令 [root@hadoop02 hive]# bin/hive ls: 无法访问/opt/module/spark/lib/spark-assembly-*.jar: 没有那个文件或目录 -- JsonSerDe这个类并没有在初始化的时候加载到环境中 Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties hive> add jar /opt/module/hive/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar; Added [/opt/module/hive/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar] to class path Added resources: [/opt/module/hive/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar]
(4)再建表成功
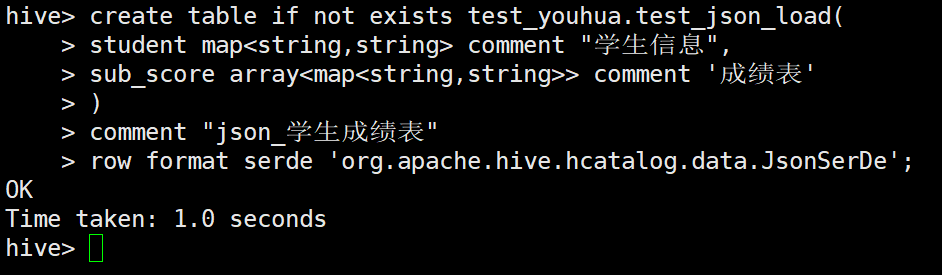
(5)将数据上传HDFS表目录,查询成功
#将文件上传HDFS表目录 [root@hadoop02 hive]# hdfs dfs -put /opt/module/hive/my_input/test_json_load hdfs:///user/hive/warehouse/test_youhua.db/test_json_load; # 登录hive [root@hadoop02 hive]# bin/hive ls: 无法访问/opt/module/spark/lib/spark-assembly-*.jar: 没有那个文件或目录 Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-1.2.1.jar!/hive-log4j.properties # 这里发现每次都要重复导入这个JsonSerDe类,否则会报错,常用的话还是要加一下默认路径避免每次重复操作 hive> select * from test_youhua.test_json_load; FAILED: RuntimeException MetaException(message:java.lang.ClassNotFoundException Class org.apache.hive.hcatalog.data.JsonSerDe not found) hive> add jar /opt/module/hive/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar > ; Added [/opt/module/hive/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar] to class path Added resources: [/opt/module/hive/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar] # 查询成功 hive> select * from test_youhua.test_json_load; OK {"name":"king","age":"11","sex":"M"} [{"subject":"语文","score":"80"},{"subject":"数学","score":"80"},{"subject":"英语","score":"80"}] {"name":"king1","age":"11","sex":"M"} [{"subject":"语文","score":"81"},{"subject":"数学","score":"80"},{"subject":"英语","score":"80"}] {"name":"king2","age":"12","sex":"M"} [{"subject":"语文","score":"82"},{"subject":"数学","score":"80"},{"subject":"英语","score":"80"}] {"name":"king3","age":"13","sex":"M"} [{"subject":"语文","score":"83"},{"subject":"数学","score":"80"},{"subject":"英语","score":"80"}] {"name":"king4","age":"14","sex":"M"} [{"subject":"语文","score":"84"},{"subject":"数学","score":"80"},{"subject":"英语","score":"80"}] {"name":"king5","age":"15","sex":"M"} [{"subject":"语文","score":"85"},{"subject":"数学","score":"80"},{"subject":"英语","score":"80"}] {"name":"king5","age":"16","sex":"M"} [{"subject":"语文","score":"86"},{"subject":"数学","score":"80"},{"subject":"英语","score":"80"}] {"name":"king5","age":"17","sex":"M"} [{"subject":"语文","score":"87"},{"subject":"数学","score":"80"},{"subject":"英语","score":"80"}] Time taken: 0.518 seconds, Fetched: 8 row(s) hive>