Schema是什么
DataFrame中的数据结构信息,即为schema。DataFrame中提供了详细的数据结构信息,从而使得SparkSQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
自动推断生成schema
使用spark的示例文件people.json, 查看数据:
[root@hadoop01 resources]# head -5 people.json {"name":"Michael"} {"name":"Andy", "age":30} {"name":"Justin", "age":19}
创建dataframe,查看该dataframe的schema:
>>>df=spark.read.format("json").load("/opt/module/spark/examples/src/main/resources/people.json") >>> df.printSchema() root |-- age: long (nullable = true) --age列,long型,可以为null |-- name: string (nullable = true) --name列,string型,可以为null
换一种schema查看方式
>>>spark.read.format("json").load("/opt/module/spark/examples/src/main/resources/people.json").schema StructType(List(StructField(age,LongType,true),StructField(name,StringType,true))) # 模式Schema是多个字段构成的StructType,字段是StructField,每个StructField信息包括名称、类型、能否为null. 还可以指定与列关联的元数据
指定schema
>>> from pyspark.sql.types import StructField,StructType,StringType,IntegerType >>> myschema=StructType([StructField("nianling",IntegerType(), True),StructField("xingming",StringType(), True)]) # 这里注意是[]、StringType()、True,而不是List、StringType、true >>>df=spark.read.format("json").schema(myschema).load("/opt/module/spark/examples/src/main/resources/people.json") >>> df.take(5) [Row(nianling=None, xingming=None), Row(nianling=None, xingming=None), Row(nianling=None, xingming=None)] # 为什么数据没有加载进去???
可能是指定的字段与json中的key值不一致??有可能
# 这里就只是把年龄类型由默认推断的long改成了int,可以读取成功 >>> myschema=StructType([StructField("age",IntegerType(), True),StructField("name",StringType(), True)]) >>> df=spark.read.format("json").schema(myschema).load("/opt/module/spark/examples/src/main/resources/people.json") >>> df.take(5) [Row(age=None, name=u'Michael'), Row(age=30, name=u'Andy'), Row(age=19, name=u'Justin')]
(以上示例用的是pyspark)
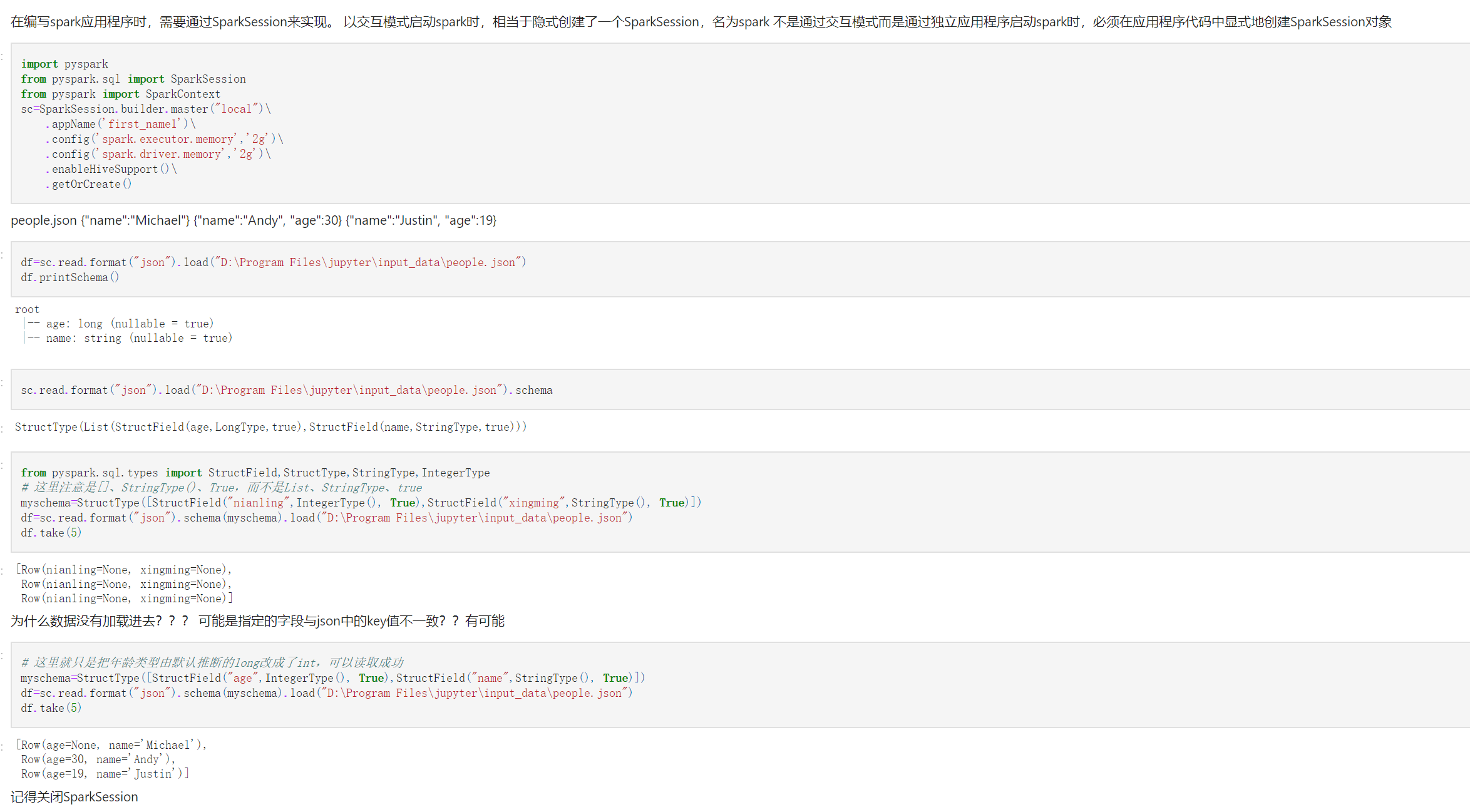
jupyter需要自己创建SparkSession
关闭sc.stop()