转载自:https://zhuanlan.zhihu.com/p/25110150
TLDR (or the take-away)
Weight Initialization matters!!! 深度学习中的weight initialization对模型收敛速度和模型质量有重要影响!
- 在ReLU activation function中推荐使用Xavier Initialization的变种,暂且称之为He Initialization:
import numpy as np
W = np.random.randn(node_in, node_out) / np.sqrt(node_in / 2)
- 使用Batch Normalization Layer可以有效降低深度网络对weight初始化的依赖:
import tensorflow as tf
# put this before nonlinear transformation
layer = tf.contrib.layers.batch_norm(layer, center=True, scale=True,
is_training=True)
实验代码请参见我的Github。
背景
深度学习模型训练的过程本质是对weight(即参数 W)进行更新,这需要每个参数有相应的初始值。有人可能会说:“参数初始化有什么难点?直接将所有weight初始化为0或者初始化为随机数!” 对一些简单的机器学习模型,或当optimization function是convex function时,这些简单的方法确实有效。然而对于深度学习而言,非线性函数被疯狂叠加,产生如本文题图所示的non-convex function,如何选择参数初始值便成为一个值得探讨的问题 --- 其本质是初始参数的选择应使得objective function便于被优化。事实上,在学术界这也是一个被actively研究的领域。
TLDR里已经涵盖了本文的核心要点,下面在正文中,我们来深入了解一下前因后果。
初始化为0的可行性?
答案是不可行。 这是一道送分题 哈哈!为什么将所有W初始化为0是错误的呢?是因为如果所有的参数都是0,那么所有神经元的输出都将是相同的,那在back propagation的时候同一层内所有神经元的行为也是相同的 --- gradient相同,weight update也相同。这显然是一个不可接受的结果。
可行的几种初始化方式
- pre-training
pre-training是早期训练神经网络的有效初始化方法,一个便于理解的例子是先使用greedy layerwise auto-encoder做unsupervised pre-training,然后再做fine-tuning。具体过程可以参见UFLDL的一个tutorial,因为这不是本文重点,就在这里简略的说一下:(1)pre-training阶段,将神经网络中的每一层取出,构造一个auto-encoder做训练,使得输入层和输出层保持一致。在这一过程中,参数得以更新,形成初始值(2)fine-tuning阶段,将pre-train过的每一层放回神经网络,利用pre-train阶段得到的参数初始值和训练数据对模型进行整体调整。在这一过程中,参数进一步被更新,形成最终模型。
随着数据量的增加以及activation function (参见我的另一篇文章) 的发展,pre-training的概念已经渐渐发生变化。目前,从零开始训练神经网络时我们也很少采用auto-encoder进行pre-training,而是直奔主题做模型训练。不想从零开始训练神经网络时,我们往往选择一个已经训练好的在任务A上的模型(称为pre-trained model),将其放在任务B上做模型调整(称为fine-tuning)。
- random initialization
随机初始化是很多人目前经常使用的方法,然而这是有弊端的,一旦随机分布选择不当,就会导致网络优化陷入困境。下面举几个例子。
核心代码见下方,完整代码请参见我的Github。
data = tf.constant(np.random.randn(2000, 800))
layer_sizes = [800 - 50 * i for i in range(0,10)]
num_layers = len(layer_sizes)
fcs = [] # To store fully connected layers' output
for i in range(0, num_layers - 1):
X = data if i == 0 else fcs[i - 1]
node_in = layer_sizes[i]
node_out = layer_sizes[i + 1]
W = tf.Variable(np.random.randn(node_in, node_out)) * 0.01
fc = tf.matmul(X, W)
fc = tf.nn.tanh(fc)
fcs.append(fc)
这里我们创建了一个10层的神经网络,非线性变换为tanh,每一层的参数都是随机正态分布,均值为0,标准差为0.01。下图给出了每一层输出值分布的直方图。
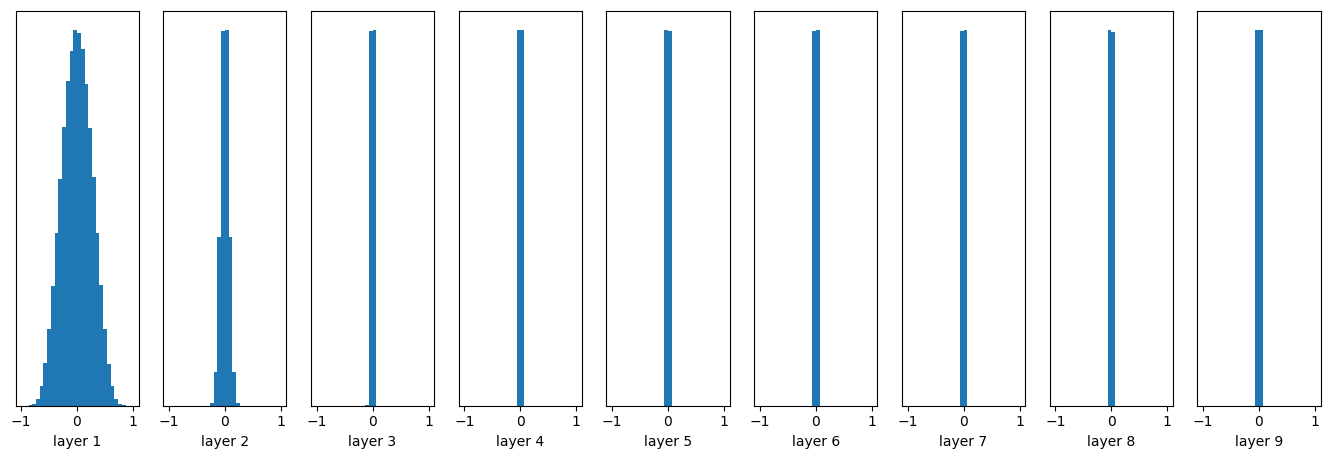
随着层数的增加,我们看到输出值迅速向0靠拢,在后几层中,几乎所有的输出值都很接近0!回忆优化神经网络的back propagation算法,根据链式法则,gradient等于当前函数的gradient乘以后一层的gradient,这意味着输出值是计算gradient中的乘法因子,直接导致gradient很小,使得参数难以被更新!
让我们将初始值调大一些:
W = tf.Variable(np.random.randn(node_in, node_out))
均值仍然为0,标准差现在变为1,下图是每一层输出值分布的直方图:
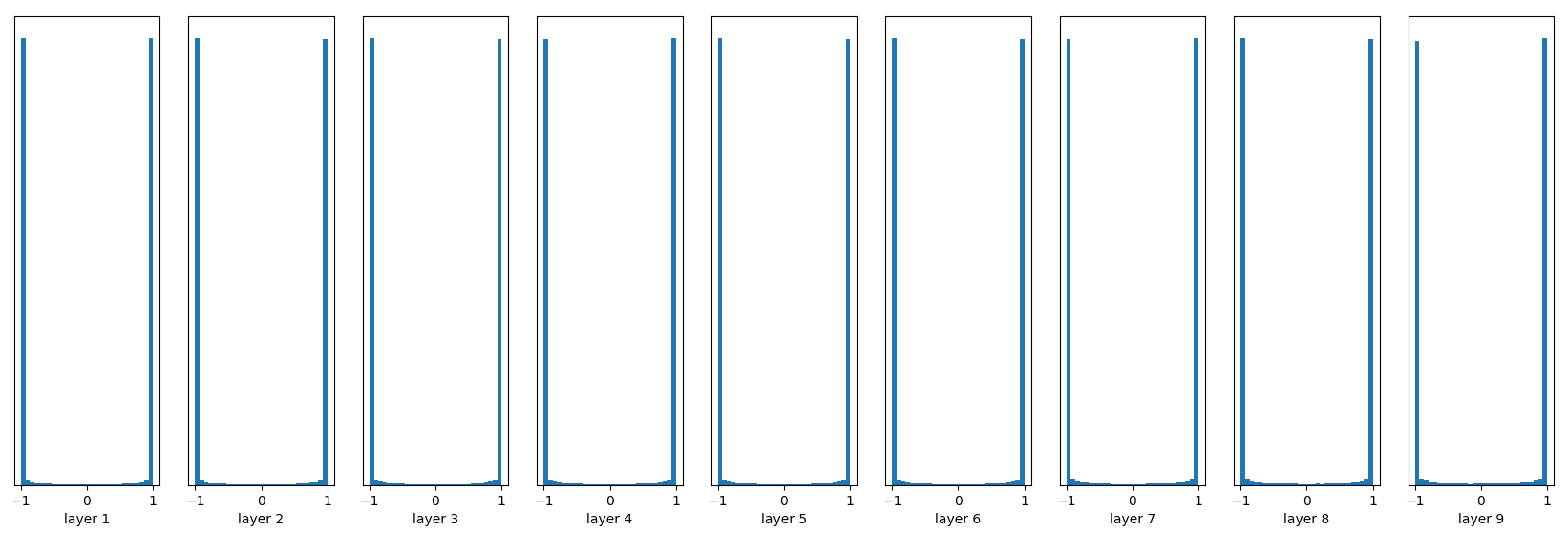
几乎所有的值集中在-1或1附近,神经元saturated了!注意到tanh在-1和1附近的gradient都接近0,这同样导致了gradient太小,参数难以被更新。
- Xavier initialization
Xavier initialization可以解决上面的问题!其初始化方式也并不复杂。Xavier初始化的基本思想是保持输入和输出的方差一致,这样就避免了所有输出值都趋向于0。注意,为了问题的简便,Xavier初始化的推导过程是基于线性函数的,但是它在一些非线性神经元中也很有效。让我们试一下:
W = tf.Variable(np.random.randn(node_in, node_out)) / np.sqrt(node_in)
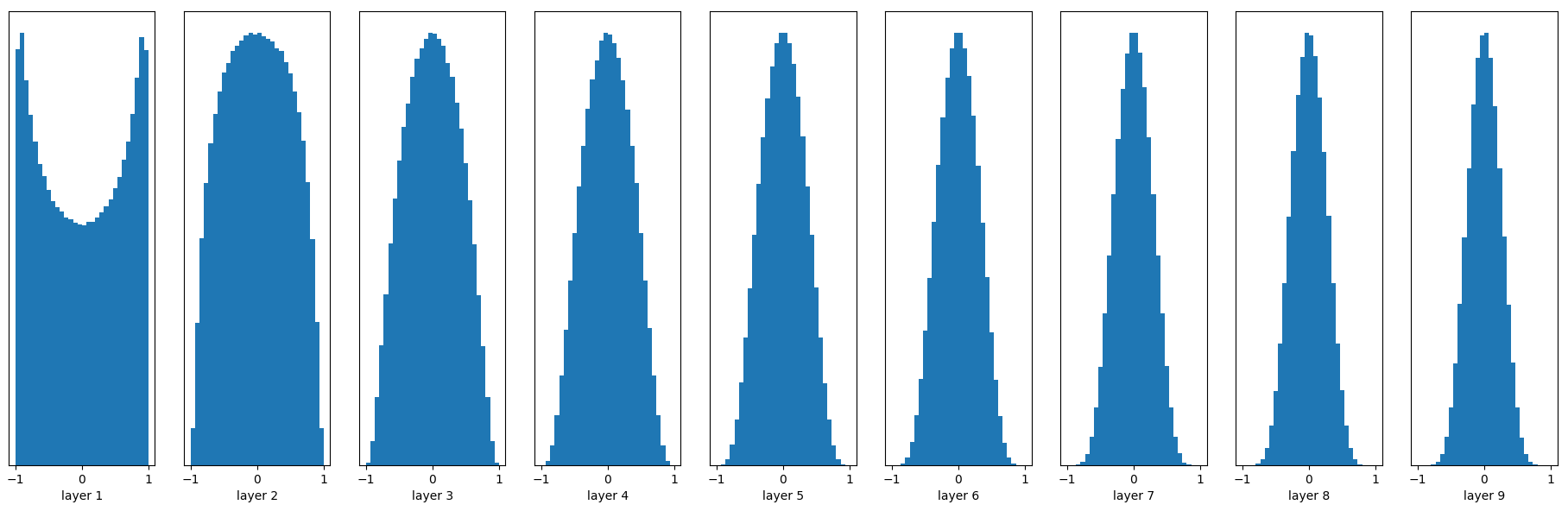
Woohoo!输出值在很多层之后依然保持着良好的分布,这很有利于我们优化神经网络!之前谈到Xavier initialization是在线性函数上推导得出,这说明它对非线性函数并不具有普适性,所以这个例子仅仅说明它对tanh很有效,那么对于目前最常用的ReLU神经元呢(关于不同非线性神经元的比较请参考这里)?继续做一下实验:
W = tf.Variable(np.random.randn(node_in, node_out)) / np.sqrt(node_in)
......
fc = tf.nn.relu(fc)
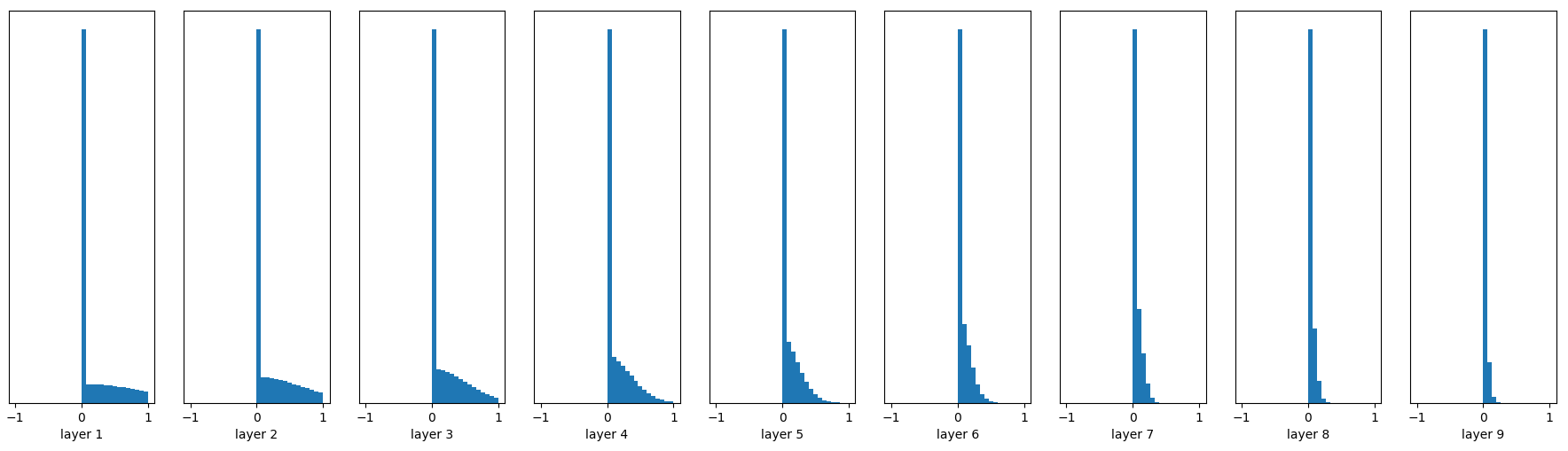
前面看起来还不错,后面的趋势却是越来越接近0。幸运的是,He initialization可以用来解决ReLU初始化的问题。
- He initialization
He initialization的思想是:在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0,所以,要保持variance不变,只需要在Xavier的基础上再除以2:
W = tf.Variable(np.random.randn(node_in,node_out)) / np.sqrt(node_in/2)
......
fc = tf.nn.relu(fc)
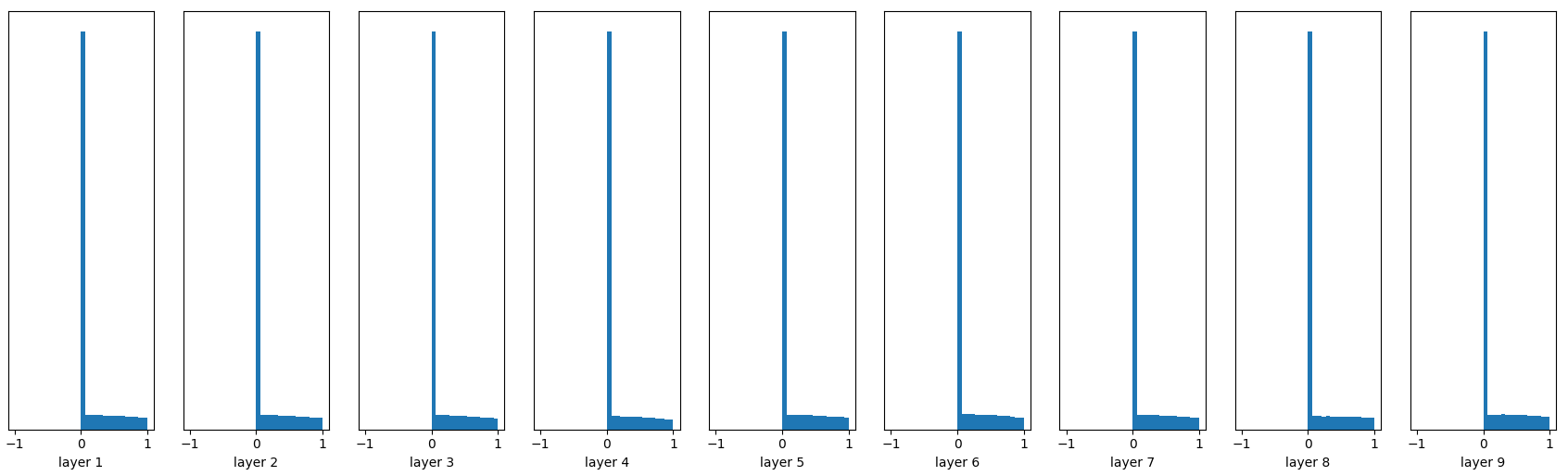
看起来效果非常好,推荐在ReLU网络中使用!
Batch Normalization Layer
Batch Normalization是一种巧妙而粗暴的方法来削弱bad initialization的影响,其基本思想是:If you want it, just make it!
我们想要的是在非线性activation之前,输出值应该有比较好的分布(例如高斯分布),以便于back propagation时计算gradient,更新weight。Batch Normalization将输出值强行做一次Gaussian Normalization和线性变换:

Batch Normalization中所有的操作都是平滑可导,这使得back propagation可以有效运行并学到相应的参数,。需要注意的一点是Batch Normalization在training和testing时行为有所差别。Training时和由当前batch计算得出;在Testing时和应使用Training时保存的均值或类似的经过处理的值,而不是由当前batch计算。
随机初始化,无Batch Normalization:
W = tf.Variable(np.random.randn(node_in, node_out)) * 0.01
......
fc = tf.nn.relu(fc)
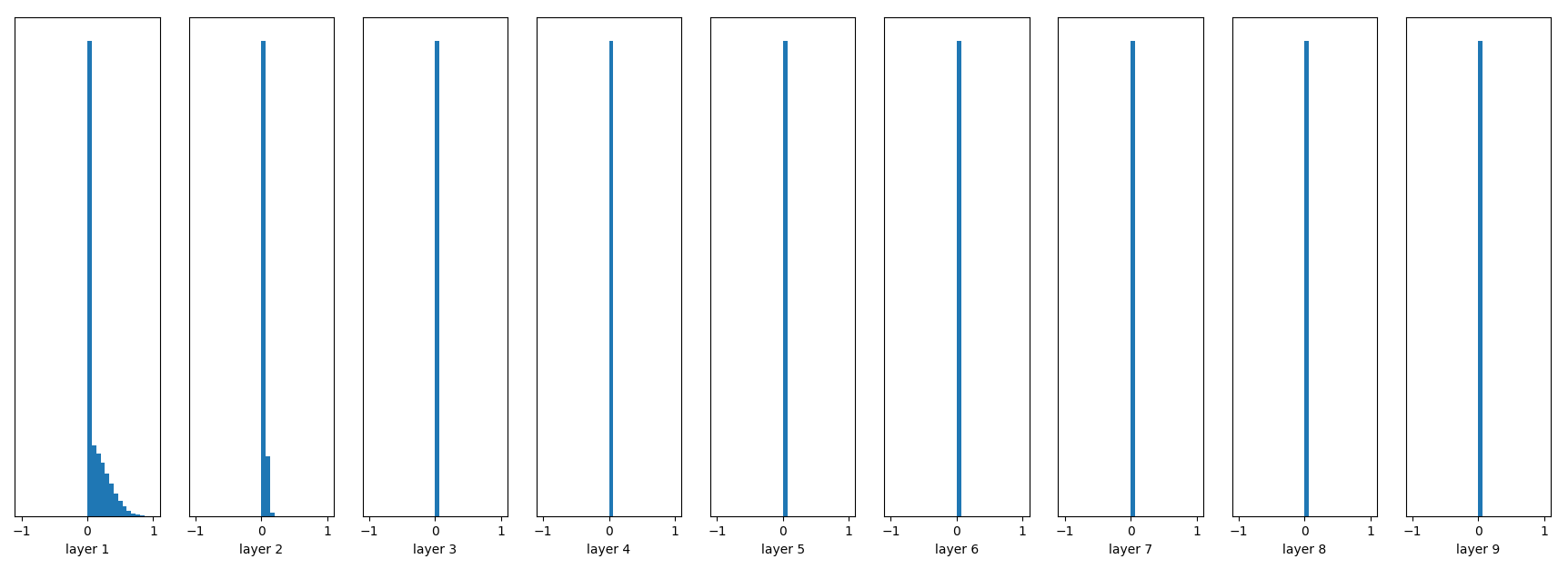
随机初始化,有Batch Normalization:
W = tf.Variable(np.random.randn(node_in, node_out)) * 0.01
......
fc = tf.contrib.layers.batch_norm(fc, center=True, scale=True,
is_training=True)
fc = tf.nn.relu(fc)
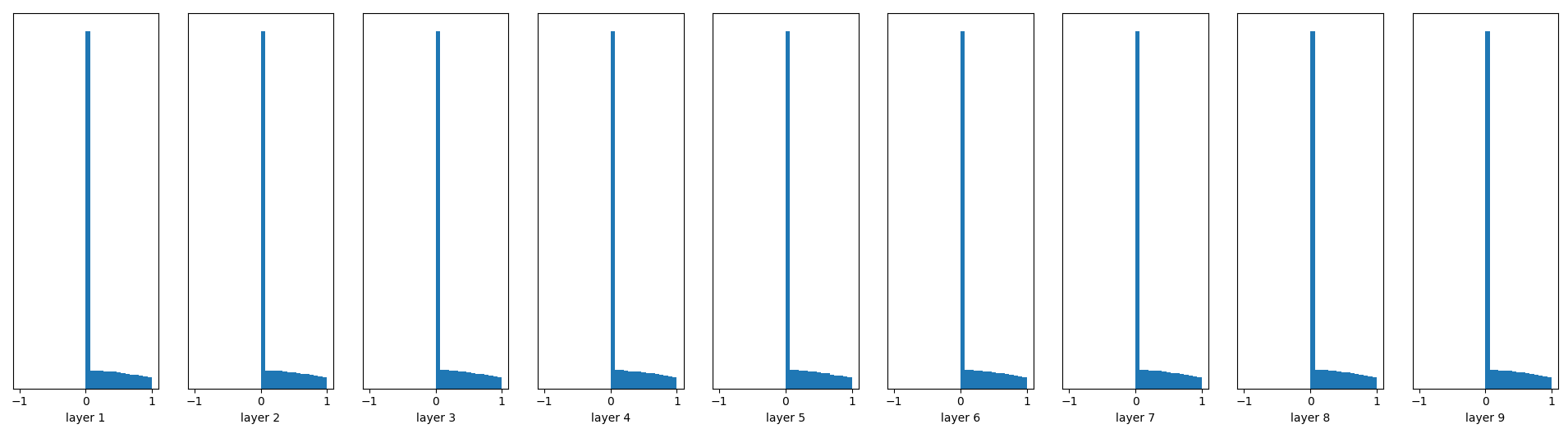
很容易看到,Batch Normalization的效果非常好,推荐使用!
参考资料
Xavier initialization是由Xavier Glorot et al.在2010年提出,He initialization是由Kaiming He et al.在2015年提出,Batch Normalization是由Sergey Ioffe et al.在2015年提出。
另有知乎网友在评论中提到了一些其他相关工作:https://arxiv.org/abs/1511.06422, https://arxiv.org/pdf/1702.08591.pdf
- Xavier Glorot et al., Understanding the Difficult of Training Deep Feedforward Neural Networks
- Kaiming He et al., Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classfication
- Sergey Ioffe et al., Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Standord CS231n