https://blog.csdn.net/weixin_43087634/article/details/84398036
2、什么是DataFrame
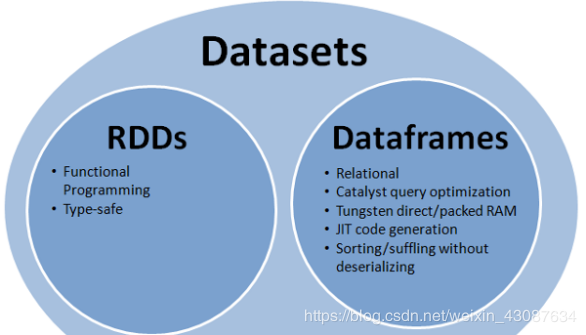
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
3、RDD和DataFrame的区别
DataFrame与RDD的主要区别在于,DataFrame带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。
RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。 DataFrame底层是以RDD为基础的分布式数据集,和RDD的主要区别的是:RDD中没有schema信息,而DataFrame中数据每一行都包含schema
DataFrame = RDD[Row] + shcema
4、什么是DataSet
Dataset是一个由特定领域的对象组成强类型(typedrel)集合,可以使用函数(DSL)或关系运算(SQL)进行并行的转换操作。 每个Dataset 还有一个称为“DataFrame”的无类型(untypedrel)视图,它是[[Row]]的数据集。
5、RDD和Dataset的区别
Dataset与RDD类似,但是,它们不使用Java序列化或Kryo,而是使用专用的Encoder编码器来序列化对象以便通过网络进行处理或传输。虽然Encoder编码器和标准序列化都负责将对象转换为字节,但Encoder编码器是动态生成的代码,并使用一种格式,允许Spark执行许多操作,如过滤,排序和散列,而无需将字节反序列化为对象
6、Dataset和DataFrame的区别与联系
区别:
- Dataset是强类型typedrel的,会在编译的时候进行类型检测;而DataFrame是弱类型untypedrel的,在执行的时候进行类型检测;
- Dataset是通过Encoder进行序列化,支持动态的生成代码,直接在bytes的层面进行排序,过滤等的操作;而DataFrame是采用可选的java的标准序列化或是kyro进行序列化
联系:
- 在spark2.x,DataFrame和Dataset的api进行了统一
- 在语法角度,DataFrame是Dataset中每一个元素为Row类型的特殊情况
type DataFrame = Dataset[Row] - DataFrame和Dataset实质上都是一个逻辑计划,并且是懒加载的,都包含着scahema信息,只有到数据要读取的时候,才会将逻辑计划进行分析和优化,并最终转化为RDD
- 二者由于api是统一的,所以都可以采用DSL和SQL方式进行开发,都可以通过sparksession对象进行创建或者是通过transform转化操作得到