https://www.cnblogs.com/gaoxiaoniu/p/10675927.html
结构体及内存对齐
1、什么是结构体
定义:结构体是一系列数据的集合,这些数据可能描述了一个物体,也可能是对一个问题的抽象。
举个栗子,简单的说,对于人,人有名字,性别,年龄,身高,体重等个人信息,那么,我们在定义这种个体的时候,就不能说它能用一个字符或整型变量来定义。 这时候,就需要结构体闪亮登场了。
基本语法:

struct 结构体名字 {
类型 名字;
类型 名字;
类型 名字;
...
}结构体变量1,结构体变量2……;
方式一:
struct People{
int age;
float height;
float weight;
NSString *name;
};
初始化及赋值:
struct People pe = {12,164.60,65.15,@"小米"};
NSLog(@"%@",pe.name);
方式二:通过结构体变量
struct Worker{
NSString *postOfDuty;
NSString *department;
} Worker1,Worker2;//这里的Worker1 Worker2 相当于方式1中创建的pe
//用这种方式 定义的结构体 只能使用点语法的方式去赋值
Worker1.postOfDuty = @"保安";
Worker2.department = @"研发部门";
NSLog(@"%@---%@", Worker1.postOfDuty, Worker2.department);
方式三:通过typedef的方式创建新类型
typedef struct{
NSString *name;
int number;
}Student;//这里的Student就是一个代表这个结构体的新类型
Student stu ={@"小明",12311};
NSLog(@"%@",stu.name);
需要注意的有一点,结构体名称和结构体变量可以同时存在 也可以只存在一个,方式一中只存在结构体名称不存在结构体变量,方式二中即存在结构体名称也存在结构体变量,下面的方式只存在结构体变量而不存在结构体名称:
struct{
NSString *nickName;
int age;
} cat,dog;
cat.nickName = @"叮当";
NSLog(@"%@",cat.nickName);
2、结构体和类的区别
1、类是引用类型,结构体是值类型,值类型的传递和赋值时是复制操作(不会改变原始对象),而引用类型则只会使用引用对象的一个指向,即对象的地址(会改变原始对象);(详见下面分析)
2、结构体只能封装属性,类却不仅可以封装属性也可以封装方法。如果一个封装的数据有属性也有行为,就只能用类了;
3、结构体变量分配在栈,而OC对象分配在栈的空间相对于堆来说是比较小的,但是存储在栈中的数据访问效率相对于堆而言是比较高。所以,我们使用结构体的时候最好是属性比较少的结构体对象,如果属性较多的话就要使用类了。
4、类可以集成,这样子类可以使用父类的特性和方法,而结构体不可以;

我们在代码中看一下结构体和类在传递和赋值中的区别:
//首先,我们分别定义一个结构体和类
//结构体
struct Worker{
NSString *postOfDuty;
NSString *department;
} Worker1,Worker2;
//类
@interface Progremer :NSObject{
@public
NSString *_name;
}
@end
@implementation Progremer
@end
//然后进行赋值和传递
Worker1.postOfDuty = @"保安";
Worker2 = Worker1;
Worker1.postOfDuty = @"业务员";
NSLog(@"%@---%@", Worker1.postOfDuty,Worker2.postOfDuty);
Progremer *p1 = [[Progremer alloc]init];
p1->_name = @"狸猫";
Progremer *p2 = p1;
p1->_name = @"橘猫";
NSLog(@"%@---%@",p1->_name,p2->_name);
//打印结果
2019-04-09 11:28:47.992811+0800 demo1[14951:7433233] 业务员---保安
2019-04-09 11:28:47.992837+0800 demo1[14951:7433233] 橘猫---橘猫
//因为结构体是值传递类型 所以再把worker1复制给worker2的时候 他是把worker1的值复制一遍再给的worker2 也就是1和2是两个一样的独立个体 我们接下来对1进行修改不会影响2 即对值传递类型进行赋值和传递时不会影响到原始对象
//类是引用类型 我们把p1赋值给p2时 他实际上是把p2的指针指到了p1上面 也就是p1和p2本身是指向同一个对象的 所以对p1的成员变量进行修改也会影响p2的输出 即引用类行的赋值和传递会影响原始对象
3、内存对齐的意义与原则
结构体内存对齐:元素是按照定义顺序一个一个放到内存中去的,但并不是紧密排列的。从结构体存储的首地址开始,每个元素放置到内存中时,它都会认为内存是按照自己的大小来划分的,因此元素放置的位置一定会在自己宽度的整数倍上开始。
内存对齐可以大大提升内存访问速度,是一种用空间换时间的方法。
内存不对齐会导致每次读取数据都会读取两次,使得内存读取速度减慢。
cpu把内存当成是一块一块的,块的大小可以是2,4,8,16 个字节,因此CPU在读取内存的时候是一块一块进行读取的,块的大小称为(memory granularity)内存读取粒度。
我们再来看看为什么内存不对齐会影响读取速度?
假设CPU要读取一个4字节大小的数据到寄存器中(假设内存读取粒度是4),分两种情况讨论:
1.数据从0字节开始(内存对齐)
2.数据从1字节开始(内存不对齐)
解析:当数据从0字节开始的时候,直接将0-3四个字节完全读取到寄存器,结算完成了(一遍即可)。
当数据从1字节开始的时候,问题很复杂,首先先将前4个字节读到寄存器,并再次读取4-7字节的数据进寄存器,接着把0字节,4,6,7字节的数据剔除,最后合并1,2,3,4字节的数据进寄存器,对一个内存未对齐的寄存器进行了这么多额外操作,大大降低了CPU 的性能。
但是这还属于乐观情况,内存对齐的作用之一是平台的移植原因,因为只有部分CPU肯干,其他部分CPU遇到未对齐边界就直接罢工了。
A、结构体的内存对齐
1.在有#pragma pack宏的情况下
有宏定义的情况下 结构体的自身宽度 就是宏上规定的数值大小 所有内存都按照这个宽度去布局
#pragma pack 参数只能是 '1', '2', '4', '8', or '16'
2.在没有#pragma pack宏的情况下
没有宏定义的情况下 结构体的自身宽度有最大成员属性的宽度决定
内存对齐原则:
1、第一个成员的首地址为0.
2、每个成员的首地址是自身大小的整数倍
3、结构体的总大小,为其成员中所含最大类型的整数倍。
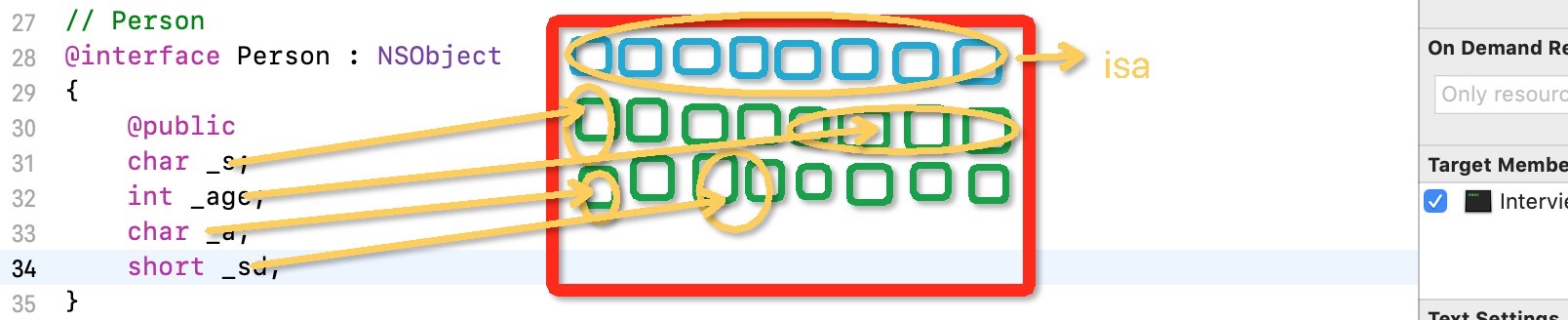
视频讲解 (这个讲解的比较清楚 但是画质不太好 这里面有个点我觉得讲的不够清晰 ↓↓↓ 例1例2中忽略了isa指针)

关于例1中 age为什么会间隔name有一个间隔 是因为每个成员距离首地址偏移量应该是自身大小的整倍数 char占用一个字节 所以例2中可以挨着name1继续放 但是 short自身占用两个字节 所以它只能分配在距离首地址2n的位置
接下来看下面两个例子:同一个结构体创建相同的成员变量 所占用内存情况也不近相同

内存分配及使用情况如下图:分配16个 使用16个

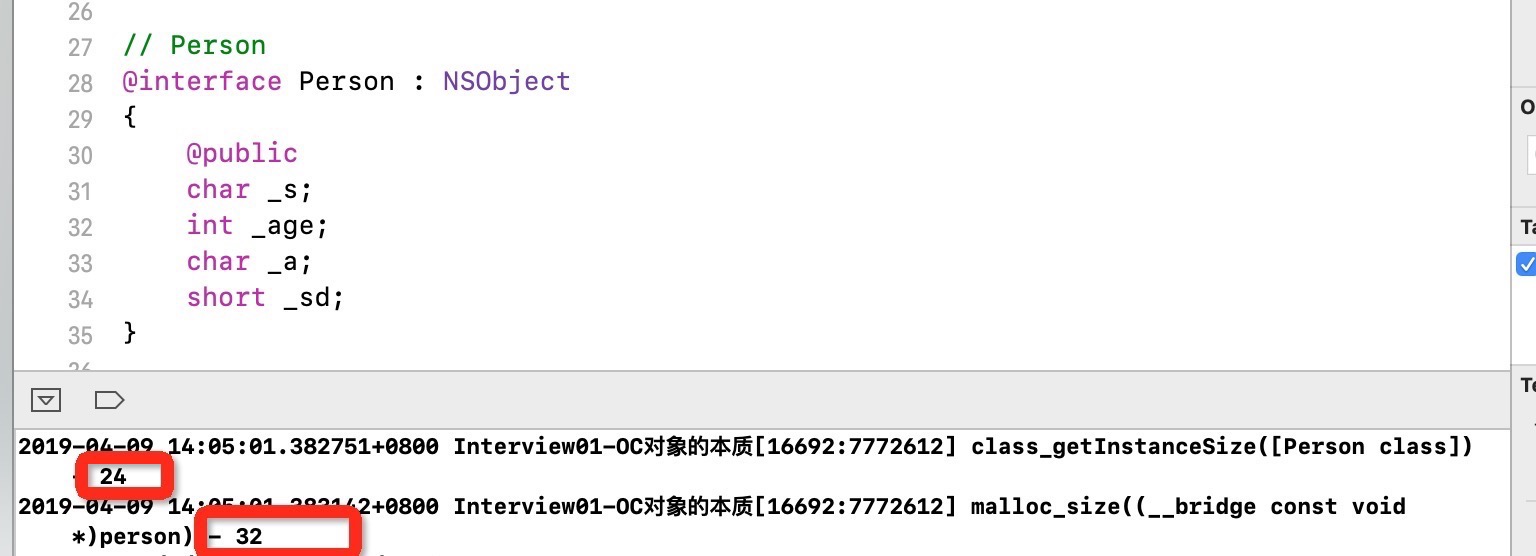
内存分配及使用情况如下图:分配32个 使用24个 (关于分配32个 这个是由于操作系统的内存对齐原则 接下来会讲到)
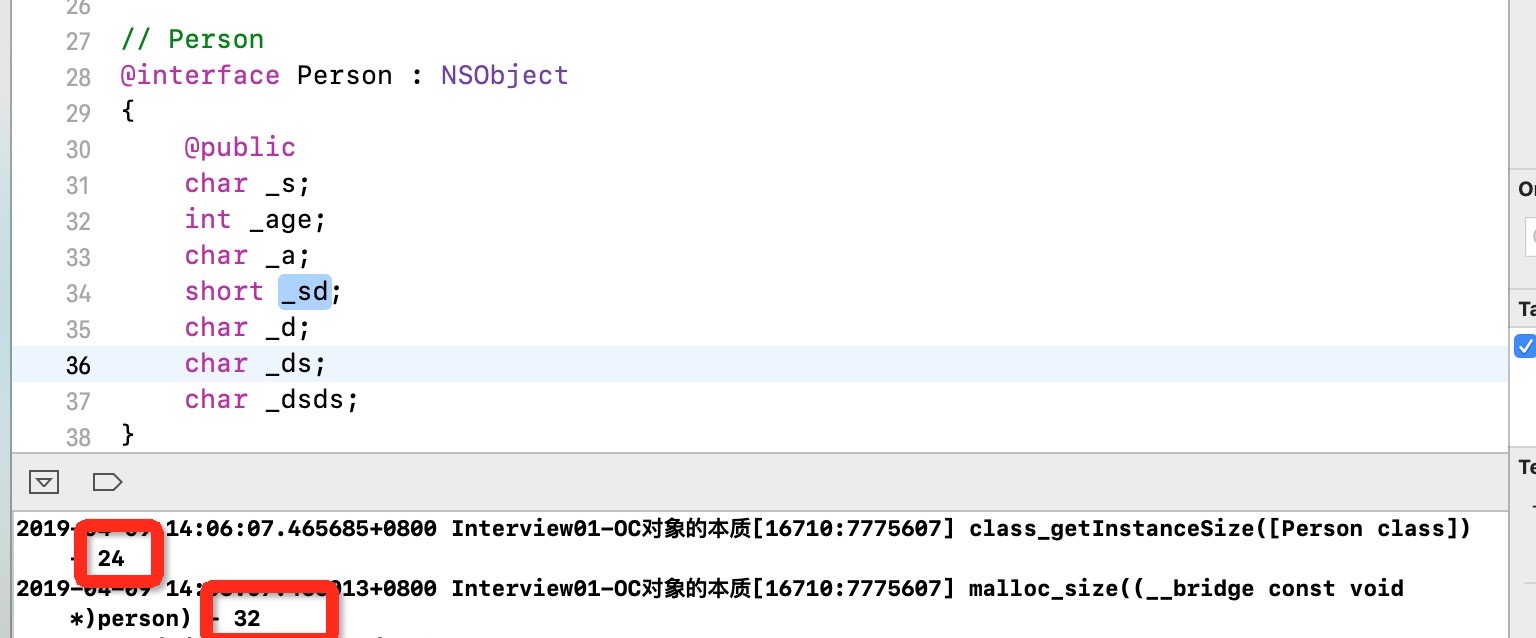
所以即使同样的结构体 同样的成员变量 不同的位置也会造成不一样的内存开销 这也就是app的优化空间
B、操作系统的内存对齐
在mac系统中 ,操作系统在分配内存的时候只会分配16的整倍数的内存空间 比如你有15字节的东西存储到内存中 会分配给你16个字节的内存空间 你有17个字节的东西分配到内存空间 就会给你分配32个字节的内存空间
就好比操作系统的内存池中只有16 32 48 64 80 96 112 这些固定大小的桶 会分配给你一个能放下你东西的最小规格的桶
#define NANO_MAX_SIZE 256 /* Buckets sized {16, 32, 48, 64, 80, 96, 112, ...} */
另外 结构体的内存地址就是它第一个成员变量的地址 isa永远都是结构体中的第一个成员变量 所以结构体的地址也就是其isa指针的地址(不确定)