嵌套交叉验证(nested cross validation)选择算法(外循环通过k折等进行参数优化,内循环使用交叉验证),对特定数据集进行模型选择。Varma和Simon在论文Bias in Error Estimation When Using Cross-validation for Model Selection中指出使用嵌套交叉验证得到的测试集误差几乎就是真实误差。
嵌套交叉验证外部有一个k折交叉验证将数据分为训练集和测试集,内部交叉验证用于选择模型算法,其中就是外部使用cross_val_score,内部使用 GridSearchCV调参
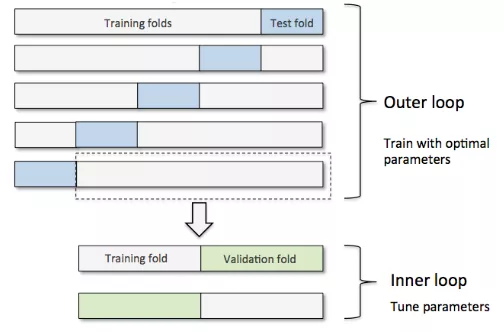
下图演示了一个5折外层交叉沿则和2折内部交叉验证组成的嵌套交叉验证,也被称为5*2交叉验证:
from sklearn.tree import DecisionTreeClassifier from sklearn import datasets #自带数据集 from sklearn.model_selection import train_test_split,cross_val_score #划分数据 交叉验证 import matplotlib.pyplot as plt iris = datasets.load_iris() #加载sklearn自带的数据集 x = iris.data #这是数据 y = iris.target #这是每个数据所对应的标签 gs = GridSearchCV(estimator=DecisionTreeClassifier(random_state=0), param_grid=[{'max_depth': [1, 2, 3, 4, 5, 6, 7, None]}], scoring='accuracy', cv=2) scores = cross_val_score(gs, x, y, scoring='accuracy', cv=5) print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))
CV accuracy: 0.967 +/- 0.030