GlusterFS简介:
互联网四大开源分布式文件系统分别是:MooseFS、CEPH、Lustre、GusterFS.
GluterFS最早由Gluster公司开发,其目的是开发一个能为客户提供全局命名空间、分布式前端及高达数百PB级别扩展性的分布式文件系统。
相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器
的设计,让整个服务没有单点故障的隐患。
常见的分布式文件系统简介:
1、MooseFS
MooseFS主要由管理服务器(master)、元日志服务器(Metalogger)、数据存储服务器(chunkserver)构成。
管理服务器:主要作用是管理数据存储服务器,文件读写控制、空间管理及节点间的数据拷贝等。
元日志服务器:备份管理服务器的变化日志,以便管理服务器出问题时能恢复工作。
数据存储服务器:听从管理服务器调度,提供存储空间,接收或传输客户数据等。
MooseFS的读过程如图所示:
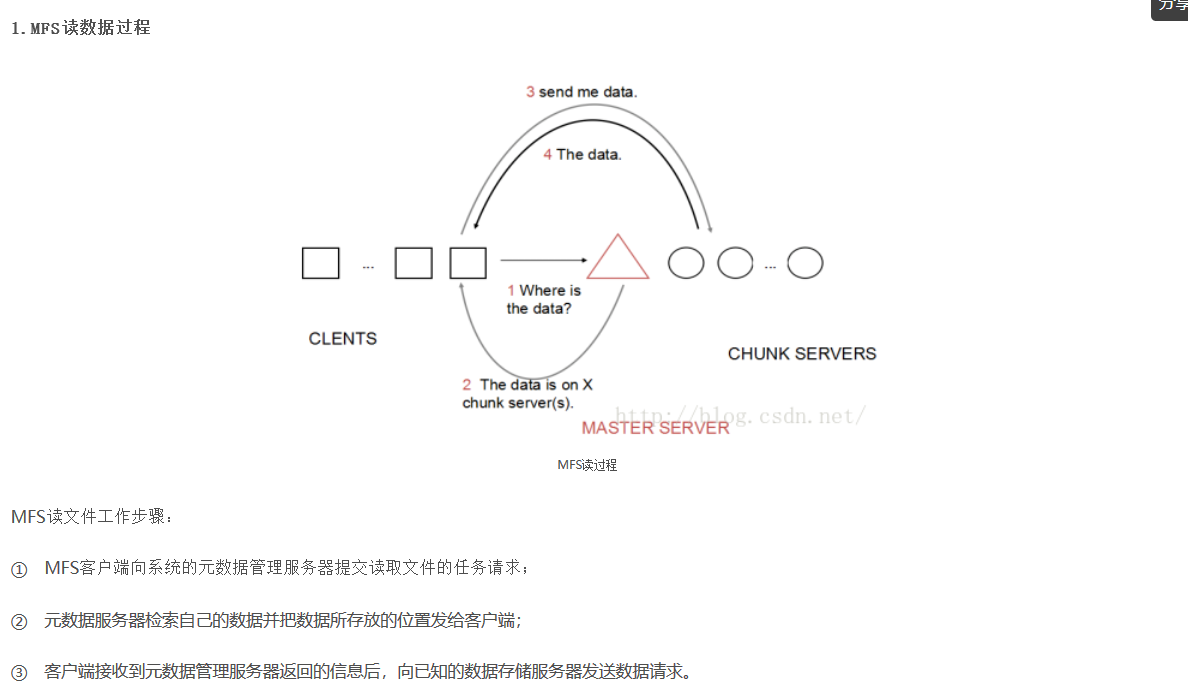

总结:MooseFS结构简单,适合初学者理解分布式文件系统的工作过程,但MooseFS具有单点故障隐患,一旦master无法工作,整个分布式文件系统
都将停止工作,因此需要实现master服务器的高可用(比如heartbeat+drbd实现)
2、Lustre
Lustre 是一个比较典型的高性能面向对象的文件系统,其结构相对比较复杂,如图所示:
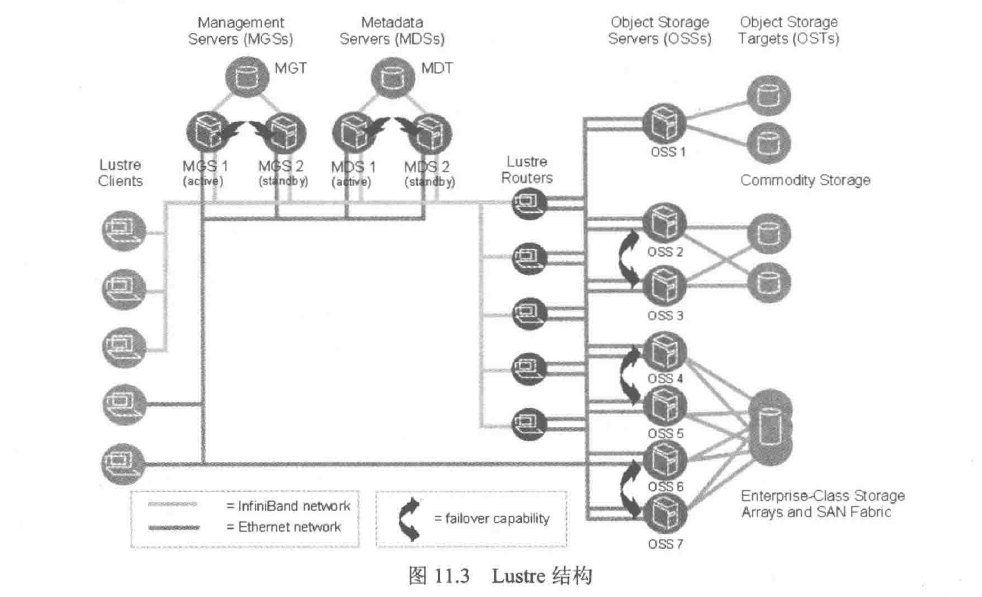
Lustre由元数据服务器(Metadata Servers,MDSs)、对象存储服务器(Object Storage Servers,OSSs)和管理服务器(Management
Servers,MGSs)组成。与MooseFS类似,当客户端读取数据时,主要集中在MDSs和OSSs间;写入数据时就需要MGS、MDSs及OSSs
共同参与操作。
总结:Lustre主要面对的是海量的数据存储,支持多达10000个节点、PB级的数据存储、100Gbit/s以上传输速度。在气象、石油等领域应用十分
广泛,是目前比较成熟的解决方案之一。
3、Ceph
请参考Ceph分布式存储篇。
二、GluserFS概述
1、无元数据设计
元数据是用来描述一个文件或给定区块在分布式文件系统中所在的位置,简而言之就是文件或某个区块存储的位置。
主要作用就是管理文件或数据区块之间的存储位置关系。
GlusterFS设计没有集中或分布式元数据,取而代之的是弹性哈希算法。集群中的任何服务器、客户端都可利用哈希算法、路径及文件名
进行计算,就可以对数据进行定位,并执行读写访问操作。
结论:无元数据设计带来的好处是极大地提高了扩展性,同时也提高了系统的性能和可靠性。如果需要列出文件或目录,性能会大幅下降,因为
列出文件或目录,需要查询所在的节点并对节点中的信息进行聚合。但是如果给定确定的文件名,查找文件位置会非常快。
2、服务器间的部署
GlusterFS集群服务器之间是对等的,每个节点服务器都掌握了集群的配置信息。所有信息都可以在本地查询。每个节点的信息更新都会
向其他节点通告,保证节点信息的一致性。但是集群规模较大后,信息同步效率会下降,非一致性概率会提高。
3、客户端访问
当客户端访问GlusterFS存储时,流程如图所示:
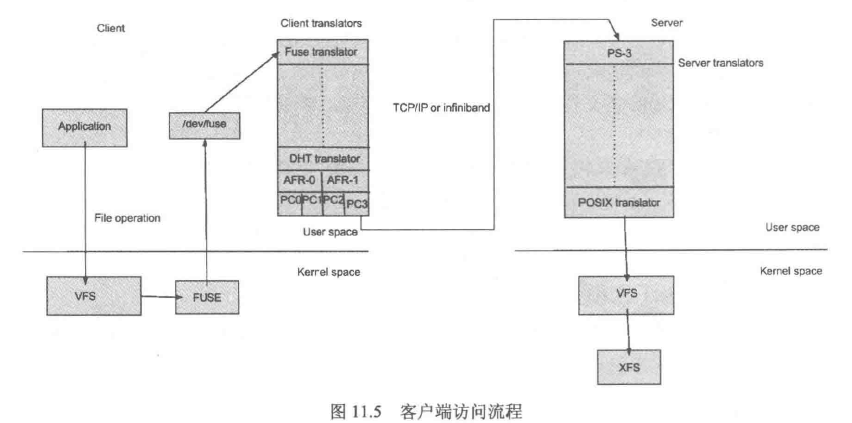
首先程序通过访问挂载点的形式读写数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感觉不到文件系统是本地
还是远端服务器上。读写操作会被交给VFS(Virtual File System,虚拟文件系统) 来处理,VFS会将请求交给FUSE内核模块,而FUSE又会
通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client计算,并最终通过网络将请求或数据发送到GlusterFS Servers上。
4、可管理性
GlusterFS在提供了一套基于Web GUI的基础上,还提供了一套基于分布式体系协同合作的命令行工具,两者相结合就可以完成
GlusterFS的管理工作。
三、GlusterFS集群模式
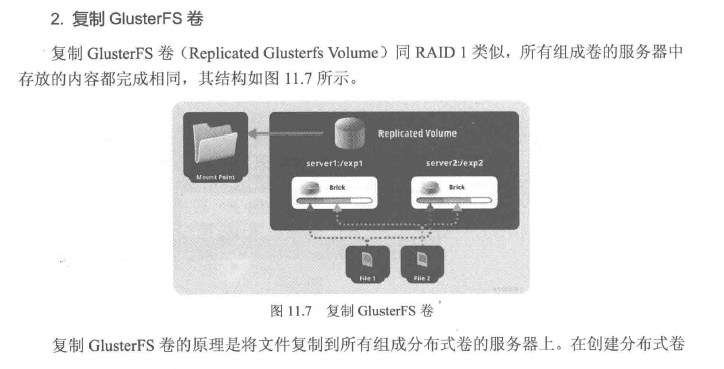
GlusterFS集群模式是指数据在集群中的存放结构,类似于磁盘阵列中的级别。GlusterFS支持多种集群模式,具体如下:




四、集群部署:
GlusterFS安装部署
1.安装glusterfs依赖的包
yum install -y centos-release-gluster37.noarch yum --enablerepo=centos-gulster*-test install gluster-server gluster-cli gluster-geo-replication
二、GlusterFS安装部署实践
2.1GlusterFS安装环境准备
#准备好4台Centos6-x86_64虚拟机 内存1G 数据盘10G 网络选择nat;
每台机器,关闭 selinux iptables并做每台好主机名解析:
192.168.10.101 mystorage1 192.168.10.102 mystorage2 192.168.10.103 mystorage3 192.168.10.104 mystorage4
补充说明:
#修改主机名2个位置
1. 修改 /etc/sysconfig/network 另外一个是 /etc/hosts vi /etc/sysconfig/network 里面有一行 HOSTNAME=localhost.localmain修改成localhost.localdomain作为主机名 /etc/hosts里面有一行 127.0.0.1 localhost.localdomain(主机名hostname)
2.2关闭selinux及iptables
#关闭selinux sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux或 sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config #关闭iptables /etc/init.d/iptables stop #永久关闭 chkconfig iptables off
2.3安装epel源(4台主机分别执行)
GlusterFS yum 源有部分包依赖epel源 yum -y install epel-release
2.4安装glusterfs源(4台主机分别执行)
wget -P /etc/yum.repos.d/ https://download.gluster.org/pub/gluster/glusterfs/3.7/LATEST/RHEL/glusterfs-epel.repo
或者gluster的相关包下载到本地目录
主要包括
glusterfs-3.7.4-2.e16.x86_64.rpm glusterfs-cli-3.7.4-2.e16.x86_64.rpm glusterfs-debuginfo-3.7.4-2.e16.x86_64.rpm glusterfs-geo-replication-3.7.4-2.e16.x86_64.rpm glusterfs-rdma-3.7.4-2.e16.x86_64.rpm glusterfs-api-3.7.4-2.e16.x86_64.rpm glusterfs-client-xlators-3.7.4-2.e16.x86_64.rpm glusterfs-fuse-3.7.4-2.e16.x86_64.rpm glusterfs-libs-3.7.4-2.e16.x86_64.rpm glusterfs-server-3.7.4-2.e16.x86_64.rpm
下载地址:
https://download.gluster.org/pub/gluster/glusterfs/3.7/LATEST/CentOS/epel-6.8/x86_64/
例如:(4台主机分别执行)
mkdir -p /opt/glusterfs
执行yum -y install glusterfs-*
一直执行完毕,没有报错的话,glusterfs安装完毕;
2.5或者yum安装(4台主机分别执行)
yum install -y centos-release-gluster37.noarch yum --enablerepo=centos-gluster*-test install glusterfs-server glusterfs-cli glusterfs-geo-replication
2.6配置Glusterfs
#查看gluster版本信息
glusterfs -V
#启动停止服务(4台主机分别执行)
/etc/init.d/glusterd start /etc/init.d/glusterd stop
#添加开机启动(4台主机分别执行)
chkconfig glusterd on
#查看glusterfs的运行状态(4台主机分别执行)
/etc/init.d/glusterd status
2.7存储主机加入信任存储池配置(4台主机分别执行)
说明:每台主机上加入除本机以外对应的其他3台主机的存储池配置
gluster peer probe mystorage2 gluster peer probe mystorage3 gluster peer probe mystorage4
#查看配置连接存储池的状态(4台主机分别执行)
gluster peer status
三、GlusterFS配置实践
3.1 配置之前的准备工作
安装xfs支持包(4台主机分别执行)
yum -y install xfsprogs
fdisk -l #查看磁盘块设备,查看类似的信息
#磁盘分区(这步可以不做)
fdisk /dev/vdb n p 1(数字) 回车 w
再次执行fdisk -l查看
说明:如果格式话分区的磁盘大于4T使用 parted命令
生产环境中:磁盘的分区的分区暂时不做。直接对应格式化即可。
#分区格式化,每台机器上执行
mkfs.xfs -f /dev/sdb
#分别在4台机器上 执行
mkdir -p /storage/brick1 #建立挂在块设备的目录 mount /dev/sdb /storage/brick1
执行df -h查看
#开机自动挂载(4台机器中每台执行)
编辑/etc/fstab添加如下
/dev/sdb /storage/brick1 xfs defaults 0 0
或者执行命令:(4台机器中每台执行)
echo "/dev/sdb /storage/brick1 xfs defaults 0 0" >> /etc/fstab
#4台机器中机器分别执行挂载命令
mount -a
#每台机器执行查看挂载情况命令;(4台机器也都自动挂载了)
df -h
3.2创建volume及其操作
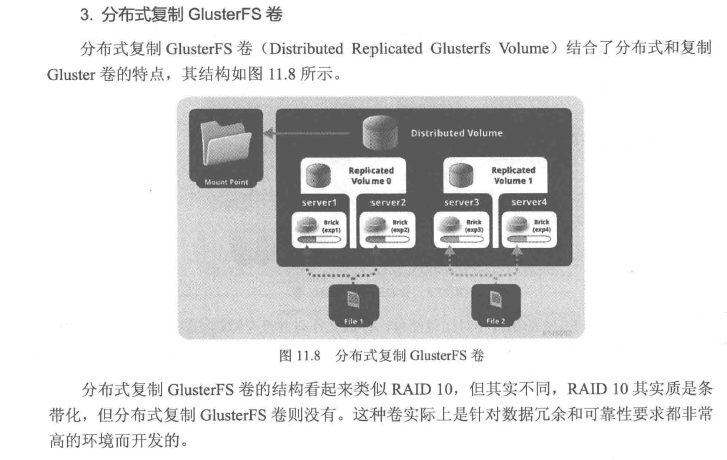
Distributed,分布卷,算法随机分布到bricks组的卷上。 Replicated 复制试卷,类似raid1 replica数必须等于volume中brick所包含存储服务器数,可用性高。 Striped,带条带的卷,类似raid0 stripe数必须等于volume中brick所包含的存储服务器数,文件被分割数据模块,以RoundRobin的方式存储在bricks,并发颗粒度是数据块,大文件性能好. Distributed Striped分布式的条带卷,volume中的brick所包含的存储服务器数必须是stripe的倍数(>=2倍)兼顾分布式和条带的功能、(生产环境一般不使用,官方也不推荐) Distributed Relicated分布式的复制卷,volume中brick1所包含的存储服务器数必须是replica的倍数(>=2倍)兼顾分布式和复制的功能。(生产环境使用较多)
情景1:
3.3创建分布卷(任意一台主机执行即可)[意义是跨主机整合磁盘]
gluster volume create gv1 mystorage1:/storage/brick1 mystorage2:/storage/brick1 force
3.4创建启动卷(任意一台主机执行即可)
[root@ mystorage1brick1]# gluster volume start gv1
#查看配置卷的信息
[root@ mystorage1brick1]# gluster volume info
3.5挂载到目录(任意一台主机执行即可)
mount -t glusterfs 127.0.0.1:/gv1 /mnt
3.6#查看挂载后的磁盘(任意一台主机执行即可)
df -h
3.7创建文件查看测试结果
#mystorage1s上创建文件
[root@mystorage1 mnt]# touch a b c dd ddf
#mystorage3查看创建文件
[root@mystorage3 mnt]# ls a b c dd ddf
情景2:
3.8测试NFS方式挂载及查看数据
[root@mystorage4 /]# umount /mnt/ [root@mystorage4 /]# mount -o mountproto=tcp -t nfs 192.168.56.11:/gv1 /mnt/ [root@mystorage4 /]# df -h [root@mystorage4 /]# umount /mnt/
#测试挂载另外一台机器
[root@mystorage4 /]# mount -o mountproto=tcp -t nfs 192.168.56.12:/gv1 /mnt/ [root@mystorage4 /]# df -h [root@mystorage4 /]# umount /mnt/
情景3:
3.9创建分布式复制卷(storage3和storage4)[生产场景推荐使用此种方式]
[root@mystorage1 mnt]# gluster volume create gv2 replica 2 mystorage3:/storage/brick1 mystorage4:/storage/brick1 force [root@mystorage2 ~]# gluster volume start gv2 [root@mystorage1 mnt]# df -h [root@mystorage1 mnt]# mount -t glusterfs 127.0.0.1:/gv2 /opt [root@mystorage1 mnt]# df -h [root@mystorage1 mnt]# cd /opt/ [root@mystorage1 opt]# touch sdfsd sdf
3.10测试查看分布式复制的数据(storage3和storage4)
[root@mystorage3 mnt]# cd /storage/brick1 [root@mystorage3 brick1]# ls sdfsd sdf [root@mystorage4 mnt]# cd /storage/brick1 [root@mystorage4 brick1]# ls sdfsd sdf
说明:以上两种情况,一是创建分布卷,另外创建分布式复制卷,生产场景中一般使用1个卷(整合多个磁盘到一个卷)使用分布式复制卷场景(情景3)居多。
情景4:
3.11创建分布式条带卷
#创建卷目录(4台主机分别执行)
mkdir -p /storage/brick2
#添加开机启动自动挂载(4台主机分别执行)
echo "/dev/sdc /storage/brick2 xfs defaults 0 0" >>/etc/fstab
#执行挂载(4台主机分别执行)
mount -a
#查看挂载情况(4台主机分别执行)
df -h
#创建分布式条带卷(storage1上执行)
gluster volume create gv3 stripe 2 mystorage3:/storage/brick2 mystorage4:/storage/brick2 force
#启动卷(storage1上执行)
gluster volume start gv3
#查看配置卷信息
gluster volume info
#创建要挂载的目录(分别在4台机器的根上新建gv1 gv2 gv3)
mkdir /gv1 /gv2 /gv3
#执行挂载命令(storage4上执行)(4台机器也可都执行)
mount -t glusterfs 127.0.0.1:gv1 /gv1 mount -t glusterfs 127.0.0.1:gv2 /gv2 mount -t glusterfs 127.0.0.1:gv3 /gv3 df -h
#我们创建一个10M的目录测试(storage4上)
[root@mystorage4 gv3]# ls -a . .. .trashcan [root@mystorage4 gv3]# dd if=/dev/zero bs=1024 count=10000 of=/gv3/10M.file [root@mystorage4 gv3]# dd if=/dev/zero bs=2048 count=10000 of=/gv3/20M.file [root@mystorage4 gv3]# cd /storage/brick2 [root@mystorage4 brick2]# ls -lh
#进入到storage3上看下
[root@mystorage3 gv3]# cd /storage/brick2 [root@mystorage3 brick2]# ls -lh
对比两边的文件你会发现两个文件被打散分别存储在storage3和storage4上了、
[root@mystorage3 gv3]# ls -lh #也会看到刚我们创建的两个文件。
#我们在storage3上 gv2目录测试
[root@mystorage3 gv2]# dd if=/dev/zero bs=1024 count=10000 of=/gv2/10M.file [root@mystorage3 gv2]# dd if=/dev/zero bs=2048 count=10000 of=/gv2/20M.file
#进入到storage3 brick1和storage4 brick1对比查看
[root@mystorage3 brick1]# ls -lh [root@mystorage4 brick1]# ls -lh
3.12 添加磁盘操作
#停止gv2 数据服务
gluster volume stop gv2
#添加新加的磁盘的到存储池
gluster volume add-brick gv2 replica 2 mystorage1:/storage/brick2 mystorage2:/storage/brick2 force
#启动启动卷
gluster volume start gv2
#取消挂载gv2,重新挂载
umount /gv2 mount -t glusterfs 127.0.0.1:/gv2 /gv2
#查看挂载结果(gv2已经变成20G了)
df -h
#查看gv2卷信息
gluster volume info gv2
注意说明:
当你给分布式复制卷和分布式条带卷中增加bricks时,你增加的bricks的数目必须是复制卷和条带卷数目的倍数。例如:
你给一个分布式复制卷的replica为2 你在增加bricks的时候数量必须为2.4.6.8等。
3.13磁盘存储的平衡:
注意;平衡布局是很有必要的,因为布局结构是静态的,当新的bricks加入现有卷,新建的文件会分布在旧的brick中,所以需要平衡布局结构,使新加入的bricks生效,布局只是使新布局生效。并不会在新的布局上移动老的数据,如果想在新布局生效后,重新平衡卷中的数据,还需要对卷中的数据进行平衡。
执行命令:(可在storage1上执行)
gluster volume rebalance gv2 start
#查看执行平衡后同步的状态
gluster volume rebalance gv2 status
3.14移除brick
注意:你可能想在线缩小卷的大小。例如:当硬件损坏或者网络故障的时候,你可能想在卷中移除相关的bricks注意,当你移除bricks的时候,你在gluster的挂载点不能继续访问数据,只有配置文件中的信息移除后你才能继续访问bricks的数据。当移除分布式复制卷或者分布式条带卷的时候,移除的bricks数目必须是replica或者stripe的倍数。例如:一个分布式条带卷的stripe是2 当你移除bricks的时候必须是2、4、6、8等。
执行操作:
gluster volume stop gv2
#移除操作
gluster volume remove-brick gv2 replica 2 mystorage3:/storage/brick1 mystorage4:/storage/brick1 force
3.15删除卷
#storege4上看下挂载情况
df -h
#卸载gv1
umount /gv1
#停止卷
gluster volume stop gv1
#删除卷
gluster volume
#查看卷信息
gluster volume info gv1
GlusterFS在企业中应用场景
理论和实践分析,GlusterFS目前主要使用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能都表现不佳,海量小文件LOSF问题是工业界和学术界的人工难题,GlusterFS作为通用的分布式文件系统,并没有对小文件额外的优化措施,性能不好也是可以理解的。
Media -文档、图片、音频、视频 *Shared storage -云存储、虚拟化存储、HPC(高性能计算) *Big data -日志文件、RFID(射频识别)数据
###########################################################################################
一、构建高性能分布式存储基本条件和要求
1.1硬件要求:
一般选择2U的机型,磁盘STAT盘4T,如果I/O要求比较高,可以采购SSD固态硬盘。为了充分保证系统的稳定性和性能,要求所有的Glusterfs服务器硬件配置尽量一致,尤其是硬盘数量和大小。机器的RAID卡需要带电池,缓存越大,性能越好,一般情况下建议做RAID10,如果出于空间要求的考虑,需要做RAID5,建议最好能有1-2块硬盘的热备盘。
1.2系统要求和分区划分
系统要求: 建议使用Centos6.x安装完成后升级到最新版本。 分区划分: 安装的时候,不要选择LV,建议/boot分区200M分区100G,swap分区和内存一样的大小,剩余空间给gluster使用,划分单独的硬盘空间,系统安装软件没有特殊要求,建议出了开发工具和基本的管理软件,其他软件一律安装。
1.3网络环境
网络要求全部千兆环境,gluster服务器至少有2块网卡,1块网卡绑定供gluster使用,另外1块管理网络ip用于系统管理。如果有条件购买万兆交换机,服务器可配置万兆网卡,存储性能会更好,网络方面如果安全性要求较高,可以多网卡绑定。
1.4服务器摆放分布
服务器主备要求放在不同的机柜,连接不同的交换机,即使一个机柜出现问题,还有一份数据能够正常访问。

1.5构建高性能高可用存储
一般在企业中,采用的是分布式复制卷,因为有数据备份,数据相对安全,分布式条带卷目前对gulsterfs来说没有完全成熟,存储一定的数据安全风险。
补充说明:
开启防火墙端口
一般在企业中linux的防火墙是打开的,部署gluster服务服务器需要开通如下端口:
命令如下:
iptables -I INPUT -p tcp --dport 24007:24011 -j ACCEPT iptables -I INPUT -p tcp --dport 38465:38485 -j ACCEPT
部署安装GlusterFS见前面文章https://www.liuliya.com/archive/733.html
二、构建高性能分布式存储实践优化
2.1GlusterFS文件系统优化
Auth_allow #IP访问授权;缺省值(*.allow all);合法值:Ip地址 Cluster.min-free-disk #剩余磁盘空间阀值;缺省值(10%);合法值:百分比 Cluster.stripe-block-size #条带大小;缺省值(128KB);合法值:字节 Network.frame-timeout #请求等待时间;缺省值(1800s);合法值:1-1800 Network.ping-timeout #客户端等待时间;缺省值(42s);合法值:0-42 Nfs.disabled #关闭NFS服务;缺省值(Off);合法值:Off|on Performance.io-thread-count #IO线程数;缺省值(16);合法值:0-65 Performance.cache-refresh-timeout #缓存校验时间;缺省值(1s);合法值:0-61 Performance.cache-size #读缓存大小;缺省值(32MB);合法值:字节 Performance.quick-read: #优化读取小文件的性能 Performance.read-ahead: #用预读的方式提高读取的性能,有利于应用频繁持续性的访问文件,当应用完成当前数据块读取的时候,下一个数据块就已经准备好了。 Performance.write-behind:先写入缓存内,在写入硬盘,以提高写入的性能。 Performance.io-cache:缓存已经被读过的、
2.2优化参数调整方式
命令格式: gluster.volume set <卷><参数>
例如:
#打开预读方式访问存储
[root@mystorage gv2]# gluster volume set gv2 performance.read-ahead on
#调整读取缓存的大小
[root@mystorage gv2]# gluster volume set gv2 performance.cache-size 256M
2.3监控及日常维护
使用zabbix自带的模板即可,CPU、内存、磁盘空间、主机运行时间、系统load。日常情况要查看服务器监控值,遇到报警要及时处理。
#看下节点有没有在线
gluster volume status nfsp
#启动完全修复
gluster volume heal gv2 full
#查看需要修复的文件
gluster volume heal gv2 info
#查看修复成功的文件
gluster volume heal gv2 info healed
#查看修复失败的文件
gluster volume heal gv2 heal-failed
#查看主机的状态
gluster peer status
#查看脑裂的文件
gluster volume heal gv2 info split-brain
#激活quota功能
gluster volume quota gv2 enable
#关闭quota功能
gulster volume quota gv2 disable
#目录限制(卷中文件夹的大小)
gluster volume quota limit-usage /data/30MB --/gv2/data
#quota信息列表
gluster volume quota gv2 list
#限制目录的quota信息
gluster volume quota gv2 list /data
#设置信息的超时时间
gluster volume set gv2 features.quota-timeout 5
#删除某个目录的quota设置
gluster volume quota gv2 remove /data
备注:
quota功能,主要是对挂载点下的某个目录进行空间限额。如:/mnt/gulster/data目录,而不是对组成卷组的空间进行限制。
三、Gluster日常维护及故障处理
3.1硬盘故障
因为底层做了raid配置,有硬件故障,直接更换硬盘,会自动同步数据。
如果没有做raid处理方法:
1)正常node 执行gluster volume status 记录故障节点uuid 2)执行getfattr -d -m '.*' /brick 3)记录trusted.glusterfs.volume-id 及trusted.gfid
例如:
[root@mystorage1 gv2]# getfattr -d -m '.*' /storage/brick2
在机器上更换新磁盘,挂载目录
执行如下命令:
setfattr -n trusted.glusterfs.volume-id -v 记录值 brickpath setfattr -n trusted.gfid -v 记录值 brickpath /etc/init.d/glusterd restart
3.2主机故障
一台节点故障的情况包括以下情况:
a)物理故障; b)同时有多快硬盘故障,造成数据丢失; c)系统损坏不可修复
解决方法:
1)找一台完全一样的机器,至少要保证数量和大小一致,安装系统,配置和故障机器同样的ip安装gluster软件,保证配置都一样,在其他健康的节点上执行命令gluster peer status,查看故障服务器的uuid。
2)修改新加机器的/var/lib/glusterd/glusterd.info和故障机器的一样。
cat /var/lib/glusterd/glusterd.info
UUID=2e3B51aa-45b2-4cc0-bc44-457d42210ff1
在新机器挂在目录上执行磁盘故障的操作,在任意节点上执行
[root@mystorage1 gv2]# gluster volume heal gv1 full
就会自动开始同步,但是同步的时候会影响整个系统的性能。
3)查看状态
[root@drbd01~]# gluster volume heal gv2 info
工作Glusterfs还有很多优化的位置点。具体细节官方文档最详细哈。
http://gluster.readthedocs.io/en/latest/Contributors-Guide/Guidelines-For-Maintainers/