Problem
Many companies now have a requirement to keep data for long periods of time. While this data does have to be available if requested, it usually does not need to be accessible by the application for any current transactions. Data that falls into this category are a good candidate for archival. As we all know, the larger a database/table becomes the more challenges with performance and maintenance we start to encounter. This tip will look into how partitioning can be used in the archiving process to provide users with uninterrupted access to the other data in the table while at the same time making the archiving process as fast as possible.
Solution
For those of you that have not had much experience with partitioning, this tip provides you with some good information to get started.
For this tip you can use the code that follows to setup a partitioned table and load some data into it.
-- Create partition function and scheme
CREATE PARTITION FUNCTION myDateRangePF (datetime)
AS RANGE LEFT FOR VALUES ('20120401', '20120501','20120601',
'20120701', '20120801','20120901')
GO
CREATE PARTITION SCHEME myPartitionScheme AS PARTITION myDateRangePF ALL TO ([PRIMARY])
GO
-- Create table and indexes
CREATE TABLE myPartitionTable (i INT IDENTITY (1,1),
s CHAR(10) ,
PartCol datetime NOT NULL)
ON myPartitionScheme (PartCol)
GO
ALTER TABLE dbo.myPartitionTable ADD CONSTRAINT
PK_myPartitionTable PRIMARY KEY NONCLUSTERED (i,PartCol)
ON myPartitionScheme (PartCol)
GO
CREATE CLUSTERED INDEX IX_myPartitionTable_PartCol
ON myPartitionTable (PartCol)
ON myPartitionScheme(PartCol)
GO
-- Polulate table data
DECLARE @x INT, @y INT
SELECT @y=3
WHILE @y < 10
BEGIN
SELECT @x=1
WHILE @x < 20000
BEGIN
INSERT INTO myPartitionTable (s,PartCol)
VALUES ('data ' + CAST(@x AS VARCHAR),'20120' + CAST (@y AS VARCHAR)+ '15')
SELECT @x=@x+1
END
SELECT @y=@y+1
END
GO
Now that we have a partitioned table with some data in it, let's take a look at the underlying structure of this table.
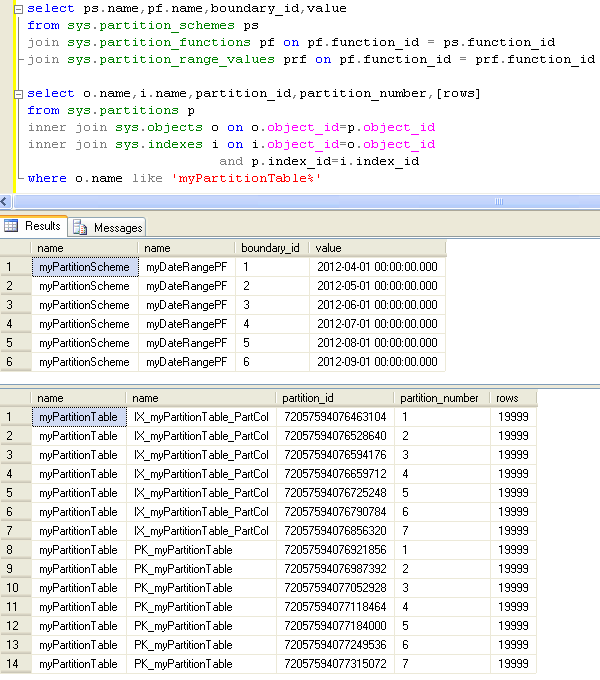
As you can see from the query results we have 7 partitions in this table and we would like to remove the oldest partition. To accomplish this we will use the SWITCH PARTITION clause of the ALTER TABLE statement. A good description of this statement can be found here. When using the SWITCH PARTITION clause there are some requirements that must be adhered to but the main point is that the source and target table schemas must match (with the exception of both needing to be partitioned).
Here is the code we can use to create our archive table.
CREATE TABLE myPartitionTableArchive (i INT NOT NULL,
s CHAR(10) ,
PartCol datetime NOT NULL)
GO
ALTER TABLE myPartitionTableArchive ADD CONSTRAINT
PK_myPartitionTableArchive PRIMARY KEY NONCLUSTERED (i,PartCol)
GO
CREATE CLUSTERED INDEX IX_myPartitionTableArchive_PartCol
ON myPartitionTableArchive (PartCol)
GO
Now that we have an empty archive table we can switch partition 1 from our partitioned table with the main partition of this table. Here is the code to do this.
ALTER TABLE myPartitionTable SWITCH PARTITION 1 TO myPartitionTableArchive GO
After running the statement above if we take a look at the sys.partitions catalog view we can see that the first partition in our partitioned table is now empty and the archive table holds these records.
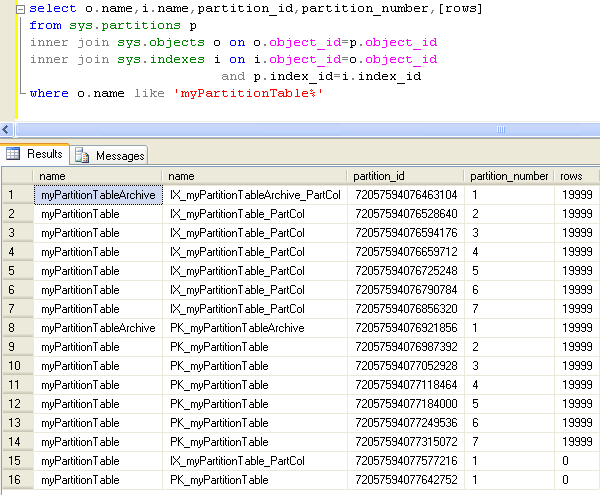
We can now merge this first empty partition with the second partition using the following command.
ALTER PARTITION FUNCTION myDateRangePF () MERGE RANGE ('20120401')
GO
Taking a look at the sys.partitions catalog view after this statement is executed we can see that we no longer have the empty partition.
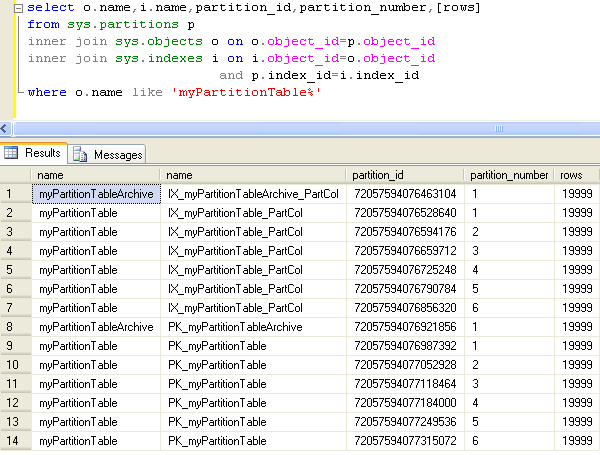
Now that we have the data we would like to archive in a separate table we can use bcp to export the data to a text file. There is a great tip here that describes how you can do this using TSQL. For our example you can run the following command and a sample output can be found here. Note: you have to replace the text between the # symbols. Once you have exported the data you can back it up to tape or leave it on your server for fast access, whichever works best for your situation.
EXEC xp_cmdshell 'bcp "select * from myPartitionTableArchive" queryout "C:\myPartitionTableArchive_#DATEHERE#.txt" -T -S#SERVERNAME# -c -t,' GO DROP TABLE myPartitionTableArchive GO
One final thing that also has to be done when working with partitioned tables is adding new partitions. Now that we have archived the oldest month of data let's assume we are moving into October and we would like to create a new partition for any new data that is added to the table this month. We can accomplish this by altering the partition function and splitting the last partition. Please note that this could also be done even if there was October data already loaded into the table. The TSQL to do this is as follows.
-- Split last partition by altering partition function
-- Note: When splitting a partition you need to use the following command before issuing the
ALTER PARTITION command however this is not needed for the first split command issued.
-- ALTER PARTITION SCHEME myPartitionScheme NEXT USED [PRIMARY]
ALTER PARTITION FUNCTION myDateRangePF () SPLIT RANGE ('20121001')
GO
Next Steps
- Read herefor more information regarding partitioning
- Evaluate your database systems to see if any would benefit from having data archived
- Create TSQL script and SQL job to automate this archival process