机器字长
机器字长是指CPU一次运算所能处理的数据的位数,一般来说这个数的和CPU的通用寄存器长度、数据总线的宽度等相等,在8086中为16bit。由于历史原因,x86系列的CPU生产较早,所以这一系列的机器字长以8086的机器字长为代表,8086的机器字长为16bit,所以在x86系列中,所谈到的字长为16bit。相比较而言,MIPS系列的CPU则相对较晚才出现,这一系列的CPU一出现就是32位的CPU,所以MIPS系列中所谈的机器字长位32bit。
字节顺序
数据在内存中的存储顺序有两种,一种为小端(Little Endian)存储,这种 存储最为常见,因为我们生活中见到的x86系列以及MIPS系列的CPU全部是小端存储。与之相反的大端(Big Endian)则较少见到,在PowerPC系列的CPU中是使用这种存储方式,此外socket编程人员可能也容易遇见这种存储,因为在Internet上面数据的传输都是采用大端存储。
无符号数与有符号数
学过C语言的同学都知道整型数据类型分为无符号类型unsigned和有符号类型signed,其中无符号类型的范围为 [0, 2n-1] (这里的n表示这种类型的bit数,如short为16个bit,32位的CPU中的int位32个bit,下同) ,有符号类型的范围为 [-2n-1,2n-1-1] 。其实这在计算机的存储层面和汇编语言的处理层面是没有这部分的区别的,有符号和无符号都统一处理(无区别对待)。它们到了C语言层面表现的不同是因为上层对它们的解释不同而已。这部分可以自己做一个实验,用C语言输出两个相同的数。1、printf("%d", -1); 2、printf("%u", -1); 这两个数都是-1,但是输出的结果大相径庭(这部分代码我还未测试过,如果相同请通知我。。。让我好一探究竟)。主要原因是上层的解释不同。
就这部分,推荐大家在C语言中除非特别确定,否则尽量不要使用unsigned,尤其是以为这部分数据不会出现负数而使用unsignd,可能会出现严重的问题。比如下面的代码:
1、认为数组下标不会出现负数:
for(unsigned i=10; i>=0; --i) arr1[i] = arr2[i];
2、认为一个类型的大小不会出现负数:
unsigned x=sizeof(int);
for(int i=0; x-i>=0; ++i) ...;
上面这两个代码都会出现死循环的问题,因为unsigned始终是满足大于等于0。注意第二部分的代码中有一个隐式类型提升。
浮点数存储
浮点数在内存中的存储如右图所示,其中s表示符号,指明是正数还是负数,exp表示指数,frac是一个介于[1.0, 2.0)之间的一个小数。
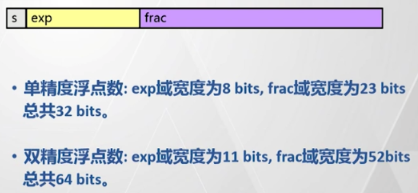
其中exp表示的指数并非简单的指数,而是要减去一个偏置量。这个偏置量在单精度中为127,在双精度中为1023。
frac可以通过调整exp保证其介于[1.0, 2.0)之间,比如将某数转换为二进制后其二进制表示为 111.0011 那么将exp加2后,这个数便可以写为1.110011。
下图是一个转化实例:

上面谈到的是规格化的表示,此外浮点数还有非规格化的表示:
1、+0和-0 :exp和frac全部为0;
2、+∞和-∞ :exp和frac全部为1;
3、不是一个数:exp全部为1, frac全部为0。
注:这里s、exp以及frac的顺序位置是精心安排的,因为这样为顺序可以保证浮点数之间的比较可以直接按二进制的大小进行比较,而不用先译码再比较。
关于浮点数的舍取问题,十进制时满足一般的四舍五入规则,但是对于 12.235000000.....(保留小数点后两位)这种参考位为5000000.....类型的,要满足向偶数取舍(round to even),即取舍完以后最低位为偶数。这样一来12.235000000.....和12.245000000.....保留小数点后两位都得到12.24。保证最后一位为偶数(4)。二进制同理,当参考位为10000.....时,也要向偶数取舍。
例如把下面的数舍入到小数点后两位:
1、10.00011 --> 参考位011 < 100... --> 直接舍掉 --> 10.00
2、10.00110 --> 参考位110 > 100... --> 直接进位 --> 10.01
3、10.11100 --> 参考位100 = 100... --> 向偶取舍 --> 11.00
4、10.10100 --> 参考位100 = 100... --> 向偶取舍 --> 10.10