数据操作
1.创建12个数的张量
import torch x=torch.arange(12) x
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
x.shape #张量的大小
torch.Size([12])
2.调用reshape函数可以改变张量的形状
X=x.reshape(3,4)
X
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
3.创建一个数组
x=torch.zeros(2,3,4,,dtype=torch.float32)#zeros,ones x
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
x=torch.tensor([1.0,2,4,8]) x#浮点型
tensor([1., 2., 4., 8.])
y=torch.tensor([2,2,2,2])#整型 y
tensor([2, 2, 2, 2])
x+y,x-y,x*y,x**y #对应元素一一计算
(tensor([ 3., 4., 6., 10.]), tensor([-1., 0., 2., 6.]), tensor([ 2., 4., 8., 16.]), tensor([ 1., 4., 16., 64.]))
4.cat()函数可以把多个向量连在一起,dim为0时按照行堆叠,dim为1时按列堆叠,默认是0
X=torch.arange(12,dtype=torch.float32).reshape(3,4) Y=torch.tensor([[2.0,1,3,4],[1,2,3,4],[4,3,2,1]]) torch.cat((X,Y)),torch.cat((X,Y),dim=0),torch.cat((X,Y),dim=1)
(tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 3., 4.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]]),
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 3., 4.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]]),
tensor([[ 0., 1., 2., 3., 2., 1., 3., 4.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
5.可以进行张量的逻辑运算,对应元素之间一一对应
X==Y
tensor([[False, True, False, False],
[False, False, False, False],
[False, False, False, False]])
6.可以进行整个张量进行求和运算,产生只有一个元素的张量
X.sum()
tensor(66.)
7.张量的广播机制,对于不同形状的张量,可以通过广播机制对元素进行操作。注意广播机制维度必须一样,比如这里都是二维
a=torch.arange(3).reshape(3,1) b=torch.arange(2).reshape(1,2) a,b
(tensor([[0],
[1],
[2]]),
tensor([[0, 1]]))
a+b
tensor([[0, 1],
[1, 2],
[2, 3]])
8.访问张量。
X[-1] #访问最后一行 X[1:3] #访问第一行和第二行
tensor([ 8., 9., 10., 11.])
tensor([[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
9.内存优化相关问题。
before=id(Y)#相当于c++中的指针 Y=Y+X #Y是新生成的变量 # Y+=X 则不会生成新的变量,还是原来的变量 id(Y)==before #所以与原来的指针地址不一样
False
Z=torch.zeros_like(Y) #执行原地操作 print('id(Z)',id(Z)) Z[:]=X+Y #Z=X+Y则是生成新的变量 print('id(Z)',id(Z))
id(Z) 2409706329864 id(Z) 2409706329864
10.tensor变量变为numpy变量。
A=X.numpy()#转为numpy
A
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]], dtype=float32)
B=torch.tensor(A) #numpy转化为张量 B type(A),type(B)
(numpy.ndarray, torch.Tensor)
11.将维度为1的张量变成标量。
a=torch.tensor([3.5])
a,a.item(),float(a),int(a)
(tensor([3.5000]), 3.5, 3.5, 3)
数据预处理
1.先建立一个csv文件,csv指的是逗号分隔数据的文件,然后在csv写入数据。
import os os.makedirs(os.path.join('/Users/cumtljz/Desktop','date'),exist_ok=True) #os.makedirs()用于递归创建目录,如果exist_ok是False(默认),当目标目录(即要创建的目录)已经存在,会抛出一个OSError, data_file=os.path.join('/Users/cumtljz/Desktop','date','1.csv') #os.path.join是路径拼接 with open(data_file,'w')as f: f.write('NumRooms,Alley,Price\n') f.write('NA,Pave,127500\n') f.write('2,NA,106000\n') f.write('4,NA,178100\n') f.write("NA,NA,140000\n")
2.pandas是专门处理文件的包,所以先导入一下pandas
import pandas as pd data=pd.read_csv(data_file) data #不用print则html格式输出
| NumRooms | Alley | Price | |
|---|---|---|---|
| 0 | NaN | Pave | 127500 |
| 1 | 2.0 | NaN | 106000 |
| 2 | 4.0 | NaN | 178100 |
| 3 | NaN | NaN | 140000 |
print(data)
NumRooms Alley Price 0 NaN Pave 127500 1 2.0 NaN 106000 2 4.0 NaN 178100 3 NaN NaN 140000
3.如果有数据缺失,则需要补全,一般需要差值和删除操作
(1)对数值域的处理
inputs,outputs=data.iloc[:,0:2],data.iloc[:,2] # 取第0,1列 取第2列 inputs=inputs.fillna(inputs.mean()) #对于NA的值替代成对应列的均值 print(inputs)
NumRooms Alley 0 3.0 Pave 1 2.0 NaN 2 4.0 NaN 3 3.0 NaN
(2)对非数值域的处理
get_dummies官方文档
#get_dummies 是利用pandas实现one hot encode的方式(举例:pandas.get_dummies 的用法) print(pd.get_dummies(inputs,dummy_na=False)) print(pd.get_dummies(inputs,dummy_na=True)) #dummy_na表示是否不忽略值为NaN的,false时忽略
NumRooms Alley_Pave 0 3.0 1 1 2.0 0 2 4.0 0 3 3.0 0 NumRooms Alley_Pave Alley_nan 0 3.0 1 0 1 2.0 0 1 2 4.0 0 1 3 3.0 0 1
4.
import pandas as pd df = pd.DataFrame([ ['green' , 'A'], ['red' , 'B'], ['blue' , 'A']]) df.columns = ['color', 'class'] pd.get_dummies(df) #都转化为one-hot
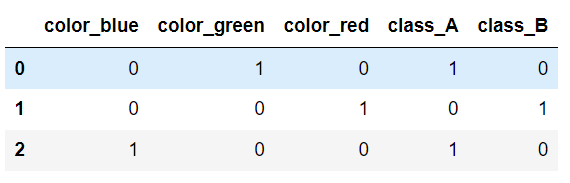
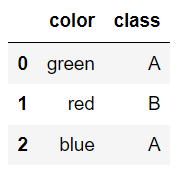
df
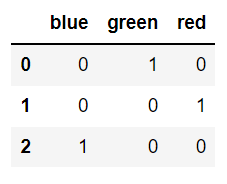
pd.get_dummies(df.color) #指定列进行one-hot操作,这里对color进行操作
df=df.join(pd.get_dummies(df.color)) #将操作后的与原来的合并在一起
