1、加载训练数据集,用于训练分类器
#加载数据集,用于训练分类器
def loadDataSet():
# 分词后的数据,一共有六个向量
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
#每个向量对应的类别标签
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec2、去除训练数据集的重复词,并且添加到一个列表中
#处理数据集,去除所有分词向量的重复词,添加到一个列表中
#先创建一个集合筛选出不重复的词向量,然后转为列表
def createVocabList(dataSet):
#这里的集合里面也是列表
vocabSet = set([]) #create empty set
for document in dataSet:
#利用并集将每个向量添加到set集合中
vocabSet = vocabSet | set(document) #union of the two sets
return list(vocabSet)
if __name__ == '__main__':
postingList,classVec = loadDataSet()
print(postingList,classVec)
vocaList = createVocabList(postingList)
print(vocaList)
'''
['food', 'garbage', 'to', 'has', 'my', 'maybe', 'stop', 'so', 'him', 'posting', 'cute', 'flea', 'quit', 'help', 'I', 'love', 'park', 'stupid', 'is', 'how', 'problems', 'dog', 'licks', 'dalmation', 'steak', 'take', 'please', 'worthless', 'mr', 'not', 'buying', 'ate']
'''
3、将输入文本转化为0/1向量
#统计待分类的词向量在词列表中是否出现
def setOfWords2Vec(vocabList, inputSet):
#初始化词列表的出现次数为0
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
#检查输入文本是否存在于词列表中
returnVec[vocabList.index(word)] = 1
else:
print ("the word: %s is not in my Vocabulary!" % word)
return returnVec
if __name__ == '__main__':
postingList,classVec = loadDataSet()
vocaList = createVocabList(postingList)
returnVec = setOfWords2Vec(vocaList,postingList[0])
print(returnVec)
'''[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0]'''
4、计算输入文档属于侮辱性文档的概率p(ci),以及在已知该文档属于侮辱性文档的情况下,计算每个单词属于侮辱性的概率P(w/ci)
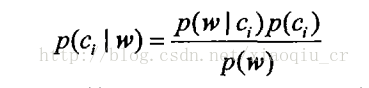
#朴素贝叶斯分类器训练函数,根据训练数据集训练得到分类器
#trainMatrix 所有文档的词条向量
#trainCategory 每篇文档对应的类别标签向量组成的矩阵
def trainNB0(trainMatrix, trainCategory):
#文档数目
numTrainDocs = len(trainMatrix)
#每篇文档的单词数
numWords = len(trainMatrix[0])
#侮辱性文档占总文档数的比例(因为侮辱性文档标签为1,加起来就是文档总数)
pAbusive = sum(trainCategory) / float(numTrainDocs)
p0Num = zeros(numWords)
p1Num = zeros(numWords) # change to ones()
p0Denom = 0.0
p1Denom = 0.0 # change to 2.0
for i in range(numTrainDocs):
#如果该文档属于类别1
if trainCategory[i] == 1:
#将该文档的词向量添加到向量p1Num中
#p1Num向量为1行numWords列
#最后p1Num为所有属于类别1的所有文档的词向量之和
#因为这里的输入文本trainMatrix[i]已经转换为了0/1向量
#eg:[0,0,0,0,0,0,0,0] + [1,0,1,1,0,0,0,0]+[1,1,1,1,0,0,0,0]+......
#这里的p1Num为已知文档类型,求各个单词在词库中出现的总数
p1Num += trainMatrix[i]
#侮辱类的总单词数
p1Denom += sum(trainMatrix[i])
else:
#否则如果是类别0,则将该文档的词向量添加到向量p0Num
p0Num += trainMatrix[i]
#然后将该文档的所有词向量加起来给p0Num
p0Denom += sum(trainMatrix[i])
#p1Vect也是一个向量
p1Vect = p1Num / p1Denom # change to log()
p0Vect = p0Num / p0Denom # change to log()
#pAbusive 侮辱性文档占所有文档数的概率
#p0Vect 已知该文档属于侮辱性文档的情况下,词汇表中的每个单词属于侮辱性的概率
#p1Vect 已知该文档属于侮辱性文档的情况下,词汇表中的每个单词不属于侮辱性的概率
return p0Vect, p1Vect, pAbusive
5、针对第四步需要对两个地方进行优化
p0Num = ones(numWords)
p1Num = ones(numWords) # change to ones()
p0Denom = 2.0
p1Denom = 2.0 # change to 2.0采用拉普拉斯平滑,在分子上添加a(一般为1),分母上添加ka(k表示类别总数),即在这里将所有词的出现数初始化为1,并将分母初始化为2*1=2
p1Vect = [math.log(x) for x in (p1Num / p1Denom)]
p0Vect = [math.log(x) for x in (p0Num / p0Denom)]由于有的单词出现的概率很小,导致乘积在四舍五入的情况下导致下溢出
if __name__ == '__main__':
postingList,classVec = loadDataSet()
print(postingList,classVec)
vocaList = createVocabList(postingList)
print(vocaList)
returnVec = setOfWords2Vec(vocaList,postingList[0])
#trainMat 所有的文档矩阵
trainMat = []
for postDoc in postingList:
trainMat.append(setOfWords2Vec(vocaList,postDoc))
print(trainMat)
p0Vect, p1Vect, pAbusive = trainNB0(trainMat, classVec)
print('已知该文档属于侮辱性文档的情况下,词汇表中的每个单词属于侮辱性的概率:',p0Vect)
print('已知该文档属于侮辱性文档的情况下,词汇表中的每个单词不属于侮辱性的概率:', p1Vect)
print('侮辱性文档占所有文档数的概率:',pAbusive)
6、根据trainNB0()函数返回的p(wi|c0),p(wi/c1),p(c1) 判断待分类文档是否属于污蔑行文档
#@vec2Classify:待测试分类的词条向量
#@p0Vec:类别0所有文档中各个词条出现的频数p(wi|c0)
#@p1Vec:类别1所有文档中各个词条出现的频数p(wi|c1)
#@pClass1:类别为1的文档占文档总数比例p(c1)
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
# 根据朴素贝叶斯分类函数分别计算待分类文档属于类1和类0的概率
#vec2Classify * p1Vec得到的是p(w/ci)
#由于贝叶斯p(w/c)=p(w1,w2,w3..../c1)=p(w1)/p(c1) * p(w2)/p(c1) * .....
#由于这里的每一项p(w1)/p(c1)是一个对数,所以最后需要加起来
#最后由公式:p(w/c)*p(c) 还需要乘以p(c1) 对于对数而言,就是相加
#最后根据公式p(c/w) = p(w/c)*p(c) / p(w)
#p1就是该文档属于污蔑性文档的概率
p1 = sum(vec2Classify * p1Vec) + log(pClass1) # element-wise mult
#p0就是该文档不属于污蔑行文档的概率
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 07、封装函数的所有操作,便于分类测试
def testingNB():
#获取训练数据集的文档矩阵,和类标签矩阵
listOPosts, listClasses = loadDataSet()
#将文档矩阵转换为一个不重复的列表
myVocabList = createVocabList(listOPosts)
trainMat = []
for postinDoc in listOPosts:
#根据postinDoc是否在myVocabList,将postinDoc转换为0/1向量
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
#将文档矩阵和类标签向量转为数组,利用trainNB0()得到
'''#@p0Vec:类别0所有文档中各个词条出现的频数p(wi|c0)
#@p1Vec:类别1所有文档中各个词条出现的频数p(wi|c1)
#@pClass1:类别为1的文档占文档总数比例p(c1)'''
p0V, p1V, pAb = trainNB0(array(trainMat), array(listClasses))
#测试文档
testEntry = ['love', 'my', 'dalmation']
#将测试文档转换为0/1向量矩阵,并且转为数组的形式
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
#对测试文档进行分类
print (testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
#第二个测试文档
testEntry = ['stupid', 'garbage']
#转换为0/1词条向量
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print (testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
if __name__ == '__main__':
postingList,classVec = loadDataSet()
print(postingList,classVec)
vocaList = createVocabList(postingList)
print(vocaList)
returnVec = setOfWords2Vec(vocaList,postingList[0])
#trainMat 所有的文档矩阵
trainMat = []
for postDoc in postingList:
trainMat.append(setOfWords2Vec(vocaList,postDoc))
p0Vect, p1Vect, pAbusive = trainNB0(trainMat, classVec)
testingNB()
'''
['love', 'my', 'dalmation'] classified as: 0
['stupid', 'garbage'] classified as: 1
'''
8、优化特征的标准:从根据每个词是否出现为特征(文档词集模型)转为---》统计每个词出现的次数为特征
#文档词袋模型,从根据每个词是否出现为特征(文档词集模型)转为---》统计每个词出现的次数为特征
def bagOfWords2VecMN(vocabList, inputSet):
#建立一个和词集列表等长的行向量,初始化每个词的出现次数为0
returnVec = [0] * len(vocabList)
#遍历输入集统计输入集中的单词在词列表中出现的次数
for word in inputSet:
if word in vocabList:
#vocabList.index(word)返回word在vocablist的索引值
returnVec[vocabList.index(word)] += 1
return returnVec为此朴素贝叶斯分类器就完全实现了
接下来利用我们构建的分类器过滤垃圾邮件
9、准备数据,切分文本
def textParse(bigString): # input is big string, #output is word list
import re
#这里的r表示原生字符串 分隔规则:匹配任意字母数字下划线 进行分隔
listOfTokens = re.split(r'W*', bigString)
#选出长度大于2的字符串并且转化为小写
return [tok.lower() for tok in listOfTokens if len(tok) > 2]10、垃圾邮件测试函数
def spamTest():
docList = [];
classList = [];
fullText = []
for i in range(1, 26):
#依次打开spam目录下的每个txt文件,并且读取内容
#按照分隔规则,将文本进行切割,得到一个列表
wordList = textParse(open('email/spam/%d.txt' % i).read())
#将每个切割后的文本作为一个整体的列表添加到doclist列表里面
docList.append(wordList)
#将所有切割后的文本添加具体的元素内容到fullText
fullText.extend(wordList)
#标签列表添加标签1
classList.append(1)
#打开ham文件夹下的所有txt文件,读取内容
#进行切割文本
wordList = textParse(open('email/ham/%d.txt' % i).read())
#将每个文本作为整体加入到wordlist
docList.append(wordList)
#将每个文本的内容加入到wordlist
fullText.extend(wordList)
#标签列表添加标签0
classList.append(0)
#处理数据集doclist,去除重复,并且将所有的文本单词向量添加到一个列表
vocabList = createVocabList(docList) # create vocabulary
#0-49
trainingSet = range(50);
testSet = [] # create test set
#0-9
#从trainingset集合里面随机选择10个数添加到testset列表里面
for i in range(10):
#uniform() 方法将随机生成下一个实数,它在 [x, y) 范围内。
#random.uniform()返回一个浮点数
#获取随机下标
randIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
#删除选出的随机数,防止下次再次选出
del (trainingSet[randIndex])
trainMat = [];
trainClasses = []
#遍历剩下的trainingSet的40个整数
for docIndex in trainingSet: # train the classifier (get probs) trainNB0
#遍历doclist的40个文本,统计他们在词典vocabList每个单词出现的次数
#将每个文本对应的词典次数向量添加到trainmat
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
#将40个文本对应标签也添加到trainClasses标签列表里面
trainClasses.append(classList[docIndex])
#将所有文本对应的词袋向量以及标签矩阵转为数组计算概率
p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses))
errorCount = 0
#遍历选出的10个测试整数
for docIndex in testSet: # classify the remaining items
#同样的将对应的文本添转为词袋向量
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
#利用测试集进行分类
if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1
print ("classification error", docList[docIndex])
print ('the error rate is: ', float(errorCount) / len(testSet))
# return vocabList,fullText
到这里垃圾邮件的过滤也已经完成了
下面展示贝叶斯另外一个功能根据个人广告获取区域倾向
1、统计高频词
#统计高频词
def calcMostFreq(vocabList,fullText):
import operator
#创建一个空字典,用于装取词典里面每个单词在fulltext里面出现的次数
freqDict = {}
for token in vocabList:
#直接使用count()函数统计文本fulltext中具体单词出现的次数
freqDict[token]=fullText.count(token)
#freqDict.iteritems()返回一个迭代器
#key=operator.itemgetter(1)根据字典的第二个域排序:也就是单词出现的次数
#参考博客:http://blog.csdn.net/dongtingzhizi/article/details/12068205
'''orted(iterable[, cmp[, key[, reverse]]])
参数解释:
(1)iterable指定要排序的list或者iterable,不用多说;
(2)cmp为函数,指定排序时进行比较的函数,可以指定一个函数或者lambda函数
reverse参数就不用多说了,是一个bool变量,表示升序还是降序排列,默认为false(升序排列),定义为True时'''
sortedFreq = sorted(freqDict.iteritems(), key=operator.itemgetter(1), reverse=True)
#返回前30个单词
return sortedFreq[:30]