1、树回归的提出背景
线性回归需要拟合所有的样本(除了局部加权性回归),实际生活中大部分的问题是非线性的。所以需要将数据集进行切分成很多份容易建模的数据,然后利用线性回归的方法进行建模。但是一般一两次的切分仍然不能满足要求,所以就提出了树回归的方法
2、CART(classification and regression trees) 分类回归树
该算法不仅能用于分类,还能用于回归。
2.1与决策树的比较
决策树:不断的将数据切分成小数据集,知道所有目标变量完全相同,或者数据不能再切分为止。决策树是一种贪心算法,需要在给定时间内做出最佳选择,但是并不关心能否达到全局最优
2.2构建树的算法
ID3:每次选择当前最佳的特征来分割数据,并按照该特征的所有可能取值来切分,也就是说,如果一个特征有4种取值,一旦按某特征切分之后,该特征之后的算法执行过程将不会再起作用。
缺点:不能处理连续性特征
二元法:每次把数据切分成两份,如果数据的某特征值等于切分所要求的值,那么这些数据进入左子树,反之进入树的右子树
优点:可以处理连续性特征
2.3构建树的伪代码
找到最佳的待切分的特征:
如果该节点不能再切分,将该节点存位叶节点
执行二元切分
在右子树调用createTree()方法
在左子树调用createTree()方法
2.4CART算法实现
- 按照指定列的某个值切割该矩阵
'''
dataSet:数据集
feature:待划分的特征
value:对应的特征值
'''
def binSplitDataSet(dataSet, feature, value):
#dataSet[:,feature]取出该列特征值
#dataSet[:,feature] > value将大于value的值筛选出来,得到的是true,false的矩阵
#然后利用nonzero选择为true的值所在的行,和列
#取出行,然后在dataset中取出对应的样本
mat0 = dataSet[nonzero(dataSet[:,feature] > value)[0],:]
mat1 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:]
return mat0,mat1>>> from numpy import *
>>> testMat=mat(eye(4))
>>> testMat
matrix([[ 1., 0., 0., 0.],
[ 0., 1., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.]])
>>> mat0,mat1=regtree.binSplitDataSet(testMat,1,0.5)>>> mat0
matrix([[ 0., 1., 0., 0.]])
>>> mat1
matrix([[ 1., 0., 0., 0.],
[ 0., 0., 1., 0.],
[ 0., 0., 0., 1.]])
>>>2.5将CART算法用于回归
- 伪代码
对每个特征:
对每个特征值:
将数据切分成两份
计算切分的误差
如果当前误差小于当前最小误差,将当前切分设定为最佳切分并更新最小误差
返回最佳切分的特征和特征值
- 回归树的切分函数代码实现
from numpy import *
#将所有的数据保存在一个矩阵中,并且将每个数转为浮点数
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split(' ')
#通过map映射将每行的内容保存为一组浮点数
fltLine = list(map(float,curLine)) #map all elements to float()
dataMat.append(fltLine)
return dataMat
'''
dataSet:数据集
feature:待划分的特征
value:对应的特征值
'''
def binSplitDataSet(dataSet, feature, value):
#dataSet[:,feature]取出该列特征值
#dataSet[:,feature] > value将大于value的值筛选出来,得到的是true,false的矩阵
#然后利用nonzero选择为true的值所在的行,和列
#取出行,然后在dataset中取出对应的样本
mat0 = dataSet[nonzero(dataSet[:,feature] > value)[0],:]
mat1 = dataSet[nonzero(dataSet[:,feature] <= value)[0],:]
return mat0,mat1
#生成叶节点,得到目标变量的均值
def regLeaf(dataSet):#returns the value used for each leaf
#最后一列的均值
return mean(dataSet[:,-1])
#计算目标变量的总误差=均方误差*样本个数
def regErr(dataSet):
return var(dataSet[:,-1]) * shape(dataSet)[0]
#找到数据最佳二元切分方式
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):
#容许的误差下降值
tolS = ops[0]
#切分的最小样本数
tolN = ops[1]
#if all the target variables are the same value: quit and return value
#如果剩余特征数位1,则不再切分,同时调用leaftype产生叶节点
if len(set(dataSet[:,-1].T.tolist()[0])) == 1: #exit cond 1
return None, leafType(dataSet)
m,n = shape(dataSet)
#the choice of the best feature is driven by Reduction in RSS error from mean
#计算样本的总误差
S = errType(dataSet)
#总误差定义为 正无穷
bestS = inf;
bestIndex = 0;
bestValue = 0
#遍历所有的特征除了最后一列
for featIndex in range(n-1):
#遍历该特征的所有特征值
for splitVal in set((dataSet[:,featIndex].T.tolist())[0]):
#根据每个特征值对dataset进行二元划分
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
#如果划分的子集的样本数小于最小样本数,停止本次循环
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continue
#计算切分后两个子集的总误差之和
newS = errType(mat0) + errType(mat1)
#将新误差之和与最好误差进行比较
if newS < bestS:
bestIndex = featIndex
bestValue = splitVal
bestS = newS
#if the decrease (S-bestS) is less than a threshold don't do the split
#计算划分前后样本的均方误差值之差,如果小于误差下降值
if (S - bestS) < tolS:
#则不再切分,产生叶节点
return None, leafType(dataSet) #exit cond 2
#根据最佳特征和最佳特征值进行切分
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
#分别计算两个子集的样本数如果小于最小样本数,就不再切分
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): #exit cond 3
return None, leafType(dataSet)
#返回最佳切分特征和特征值
return bestIndex,bestValue#returns the best feature to split on
#and the value used for that split
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):#assume dataSet is NumPy Mat so we can array filtering
#找到最佳的特征以及特征值
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)#choose the best split
#如果特征为none,返回特征值
if feat == None: return val #if the splitting hit a stop condition return val
#给回归树建立一个空字典
retTree = {}
#添加特征和特征值到字典中
retTree['spInd'] = feat
retTree['spVal'] = val
#根据最佳特征和特征值进行划分左子树和右子树
#递归调用
lSet, rSet = binSplitDataSet(dataSet, feat, val)
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree>>> reload(regtree)
<module 'regtree' from 'E:\Python36\regtree.py'>
>>> data=regtree.loadDataSet('E:\Python36\ex00.txt')
>>> data=mat(data)
>>> regtree.createTree(data)
{'spInd': 0, 'spVal': 0.48813, 'left': 1.0180967672413792, 'right': -0.044650285714285719}
>>>>>> data1=regtree.loadDataSet('E:\Python36\ex0.txt')
>>> data1=mat(data1)
>>> regtree.createTree(data1)
{'spInd': 1, 'spVal': 0.39435, 'left': {'spInd': 1, 'spVal': 0.582002, 'left': {'spInd': 1, 'spVal': 0.797583, 'left': 3.9871631999999999, 'right': 2.9836209534883724}, 'right': 1.980035071428571}, 'right': {'spInd': 1, 'spVal': 0.197834, 'left': 1.0289583666666666, 'right': -0.023838155555555553}}
>>>- 画出切割后的两个子集
def plotBestFit(lSet,rSet):
import matplotlib.pyplot as plt
#将自身转为一个多维数组
lSet=array(lSet)
rSet=array(rSet)
#取出数据集的行数
nl = shape(lSet)[0]
nr = shape(rSet)[0]
xcord1=lSet[:,0]
ycord1=lSet[:,1]
xcord2=rSet[:,0]
ycord2=rSet[:,1]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(0,1, 0.1)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()这里的rset,lset来自createTree
>>> reload(regtree)
<module 'regtree' from 'E:\Python36\regtree.py'>
>>> data=regtree.loadDataSet('E:\Python36\ex00.txt')
>>> data=mat(data)
>>> rettree,lset,rset=regtree.createTree(data)
>>> regtree.plotBestFit(lset,rset)
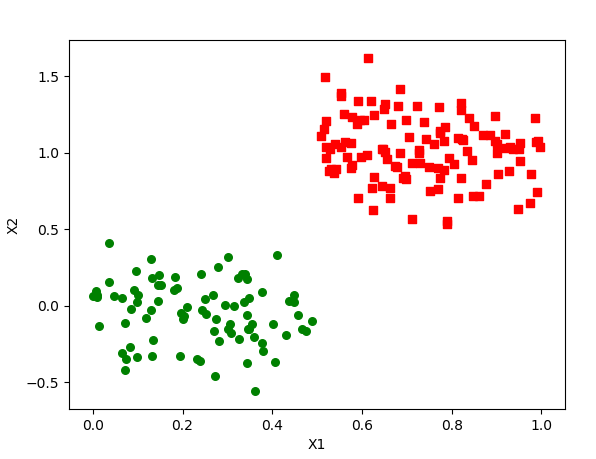
- 画出ex0.txt的切分图
myDat1=regtree.loadDataSet('E:\Python36\ex0.txt')>>> import numpy as np
>>> myDat1=np.array(myDat1)
>>> import matplotlib.pyplot as plt
>>> plt.scatter(myDat1[:,0],myDat1[:,1])
<matplotlib.collections.PathCollection object at 0x0000027C56C643C8>
>>> plt.show()
>>> plt.scatter(myDat1[:,1],myDat1[:,2])
<matplotlib.collections.PathCollection object at 0x0000027C565D87F0>
>>> plt.show()
>>>
效果如图
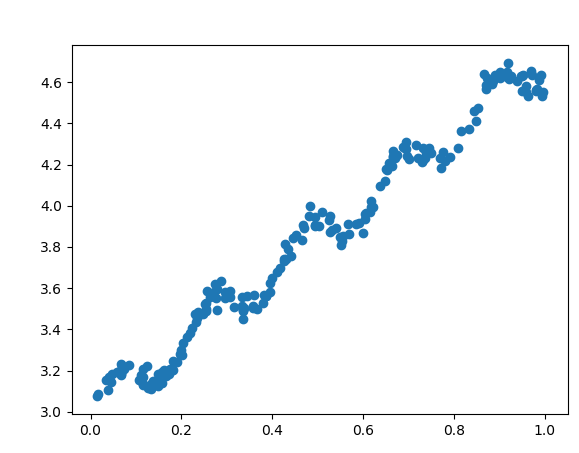
画出最后的切分图,下面贴上我自己的一点点想法,但是仍然有些bug还没有解决,也不知道自己的思路是不是正确的
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)):#assume dataSet is NumPy Mat so we can array filtering
#找到最佳的特征以及特征值
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)#choose the best split
#如果特征为none,返回特征值
if feat == None: return val #if the splitting hit a stop condition return val
#给回归树建立一个空字典
retTree = {}
#添加特征和特征值到字典中
retTree['spInd'] = feat
retTree['spVal'] = val
#根据最佳特征和特征值进行划分左子树和右子树
#递归调用
lSet, rSet = binSplitDataSet(dataSet, feat, val)
import matplotlib.pyplot as plt
# firstr = retTree.keys()[0]
secondDict=retTree['left']
for key in secondDict.keys():
if type(secondDict[key])._name_!='dict':
spindex=secondDict['spInd']
spvalue=secondDict['spVal']
lSet1, rSet1 = binSplitDataSet(lSet, spindex, spvalue)
lSet2, rSet2 = binSplitDataSet(rSet, spindex, spvalue)
lSet=array(lSet1)
rSet=array(rSet1)
lSet_1=array(lSet2)
rSet_1=array(lSet2)
xcord1=lSet[:,1]
ycord1=lSet[:,2]
xcord2=rSet[:,1]
ycord2=rSet[:,2]
xcord3=lSet_1[:,1]
ycord3=lSet_1[:,2]
xcord4=rSet_1[:,1]
ycord4=rSet_1[:,2]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
ax.scatter(xcord3, ycord3, s=30, c='green')
ax.scatter(xcord4, ycord4, s=30, c='green')
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree ,lSet,rSet
3、CRAT树的优化-剪枝
到现在为止我们已经创建好了回归树,但是具体创建的好不好,我们也不清楚,如果树的节点过多,会导致过拟合的现象,如果节点过少,又会导致欠拟合,
为了避免过拟合的现象,我们需要对决策树进行一个剪枝的过程。也就是降低决策树的复杂度
3.1预剪枝
我们在前面寻找最佳的二元切分方式的函数中,需要用户指定参数
#容许的误差下降值
tolS = ops[0]
#切分的最小样本数
tolN = ops[1]
事实上,这里就是一个预剪枝的过程,设置循环中止条件,创建叶节点
但是预剪枝受用户指定参数的影响很大
3.2后剪枝
使用后剪枝方法需要将数据集分成测试集和训练集。首先指定参数,使得构建出的树足够大、足够复杂,便于剪枝。接下来从上而下找到叶节点,用测试集来判断将这些叶节点合并是否能降低测试误差。如果是的话就合并。
3.2.1后剪枝伪代码
基于已有的树切分测试数据:
如果存在任一子集是一棵树,则在该子集递归剪枝过程
计算将当前两个叶节点合并后的误差
计算不合并的误差
如果合并会降低误差的话,就将叶节点合并
3.2.2后剪枝代码实现
#判断当前处理的节点是否是叶节点,返回布尔值
def isTree(obj):
return (type(obj).__name__=='dict')
#计算两个叶节点的均值
def getMean(tree):
#如果右节点是树继续递归
if isTree(tree['right']):
tree['right'] = getMean(tree['right'])
if isTree(tree['left']):
tree['left'] = getMean(tree['left'])
#如果找到叶节点,返回两个节点的均值
return (tree['left']+tree['right'])/2.0
'''
tree:待剪枝的树
testData:剪枝所需要的测试数据
'''
def prune(tree, testData):
#如果测试数据为空
if shape(testData)[0] == 0:
#对树进行塌陷处理,返回树的平均值
return getMean(tree) #if we have no test data collapse the tree
#如果测试数据不为空,并且待剪枝的树的左孩子或者右孩子是一颗树
if (isTree(tree['right']) or isTree(tree['left'])):#if the branches are not trees try to prune them
#对该树进行一个二元切分
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
#如果左孩纸是一颗树,就对左孩子进行剪枝,并且将左子集作为测试集
if isTree(tree['left']):
tree['left'] = prune(tree['left'], lSet)
#如果右孩子是一颗树,就对右孩子进行剪枝,并且将右子集作为测试集
if isTree(tree['right']):
tree['right'] = prune(tree['right'], rSet)
#if they are now both leafs, see if we can merge them
#如果都不是树,比较合并前后的误差大小
if not isTree(tree['left']) and not isTree(tree['right']):
#对数据集二元划分
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) +
sum(power(rSet[:,-1] - tree['right'],2))
treeMean = (tree['left']+tree['right'])/2.0
errorMerge = sum(power(testData[:,-1] - treeMean,2))
if errorMerge < errorNoMerge:
print ("merging")
return treeMean
else: return tree
else: return tree在命令行里面测试
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "E:Python36
egtree.py", line 161, in prune
errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) + sum(power(rSet[:,-1] - tree['right'],2))
TypeError: unsupported operand type(s) for -: 'float' and 'dict'然后我们将tree['left']打印出来
===
({'spInd': 0, 'spVal': 0.729397, 'left': ({'spInd': 0, 'spVal': 0.952833, 'left': ({'spInd': 0, 'spVal': 0.965969, 'left': ({'spInd': 0, 'spVal': 0.968621, 'left': 86.399636999999998, 'right': 98.648346000000004}, matrix([[ 0.98198 , 86.399637]]), matrix([[ 0.968621, 98.648346]])), 'right': ({'spInd': 0, 'spVal': 0.956951, 'left': ({'spInd': 0, 'spVal': 0.958512, 'left': ({'spInd': 0, 'spVal': 0.960398, 'left': 112.386764, 'right': 123.559747}, matrix([[ 0.965969, 112.386764]]), matrix([[ 0.960398, 123.559747]])), 'right': 135.83701300000001}, matrix([[ 0.965969, 112.386764],
[ 0.960398, 123.559747]]), matrix([[ 0.958512, 135.837013]])), 'right': ({'spInd': 0, 'spVal': 0.953902, 'left': ({'spInd': 0, 'spVal': 0.954711, 'left': 82.016541000000004, 'right': 100.935789}, matrix([[ 0.956951, 82.016541]]), matrix([[ 0.954711, 100.935789]])), 'right': 130.92648}, matrix([[ 0.954711, 100.935789],
[ 0.956951, 82.016541]]), matrix([[ 0.953902, 130.92648 ]]))}, matrix([[ 0.965969, 112.386764],
[ 0.958512, 135.837013],
[ 0.960398, 123.559747]]), matrix([[ 0.954711, 100.935789],
[ 0.953902, 130.92648 ],发现这里的tree['left']是一颗树,所以判断条件
#if not isTree(tree['left']) and not isTree(tree['right']):根本就没用
所以我改成了下面的还是没用
if isTree(tree['left']) == False and isTree(tree['right']) == False:resolution:https://github.com/crr121/CART/blob/master/Post-Pruning.ipynb
参考博客:
4、模型树
4.1什么是模型树
叶节点为分段线性函数
4.2代码实现
#为节点生成线性函数
#将数据集格式化为目标变量x和目标变量y
def linearSolve(dataSet): #helper function used in two places
m,n = shape(dataSet)
#构建m行n列的值为1的矩阵
X = mat(ones((m,n)));
#构建m行1列的矩阵
Y = mat(ones((m,1)))#create a copy of data with 1 in 0th postion
#数据集去除最后一列 赋值给矩阵X的后n-1列
X[:,1:n] = dataSet[:,0:n-1];
#将数据集最后一列赋值给Y
Y = dataSet[:,-1]#and strip out Y
xTx = X.T*X
#计算矩阵X的行列式
if linalg.det(xTx) == 0.0:
raise NameError('This matrix is singular, cannot do inverse,
try increasing the second value of ops')
#计算回归系数ws
ws = xTx.I * (X.T * Y)
return ws,X,Y
#当数据集不再需要切分的时候负责生成叶节点模型
def modelLeaf(dataSet):#create linear model and return coeficients
ws,X,Y = linearSolve(dataSet)
return ws
def modelErr(dataSet):
ws,X,Y = linearSolve(dataSet)
yHat = X * ws
return sum(power(Y - yHat,2))>>> from imp import reload
>>> reload(regtree)
<module 'regtree' from 'E:\Python36\regtree.py'>
>>> m2 = mat(regtree.loadDataSet('E:Python36exp2.txt'))
>>> regtree.createTree(m2,regtree.modelLeaf,regtree.modelErr,(1,10))
({'spInd': 0, 'spVal': 0.285477, 'left': matrix([[ 1.69855694e-03],
[ 1.19647739e+01]]), 'right': matrix([[ 3.46877936],
[ 1.18521743]])}, matrix([[ 0.534076, 6.377132],
[ 0.747221, 8.949407],由结果可知该模型产生了两个线性模型:
matrix([[ 1.69855694e-03],
[ 1.19647739e+01]]), 'right': matrix([[ 3.46877936],
[ 1.18521743]])}y = 0.00169856 + 11.9647 * x
y = 3.46877936 + 1.18521743 * x
那么我们画出原始的模型
>>> plt.plot(m2[:,0],m2[:,1],'b*')
[<matplotlib.lines.Line2D object at 0x000001B317137160>]
>>> plt.show()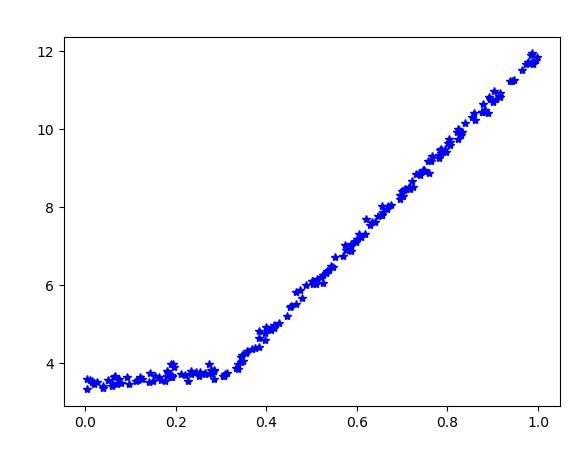
发现和我们利用模型树模拟的方程十分相似,实际上该模型是由y = 3.5 + 1*x 和 y = 0 + 12 * x 加上高斯噪声引起的
5、树回归与标准回归的比较
#输入单个数据点或者行向量,返回一个浮点数
#在给定树结构的情况下,对于单个数据点,该函数会给出一个预测值
def regTreeEval(model, inDat):
return float(str("".join(model[0])))
# try:
# return float(model)
# except ValueError:
# return model
# except TypeError:
# print(model,'TypeError')
# return float(model)
# return float(model[0].get('spInd'))
# return float(model[0].get('spVal'))
def modelTreeEval(model, inDat):
n = shape(inDat)[1]
X = mat(ones((1,n+1)))
# X[:,1:n+1]=inDat
X[:,1:n]=inDat[:,:-1]
return float(X*model)
#treeforecast自顶向下遍历整棵树,直到命中叶节点为止,然后返回当前叶节点的预测值
def treeForeCast(tree, inData, modelEval=regTreeEval):
#如果当前树不是一棵树,是叶节点,对该节点进行预测
if not isTree(tree):
return modelEval(tree, inData)
#如果当前树是一棵树,非叶节点
#并且输入数据的特征值》当前树的特征值
if float(inData[:,tree['spInd']])>tree['spVal']:
# if inData[tree['spInd']] > tree['spVal']:
#并且当前树的左节点是一棵树,非叶节点
if isTree(tree['left']):
#递归调用treeforecast
return treeForeCast(tree['left'], inData, modelEval)
#如果当前树的左节点是叶节点
else:
#返回当前叶节点的预测值
return modelEval(tree['left'], inData)
#如果输入数据的特征值《当前树的特征值
else:
#如果右分支为非叶节点
if isTree(tree['right']):
#递归调用treeforecast
return treeForeCast(tree['right'], inData, modelEval)
#如果为叶节点
else:
#返回当前叶节点的预测值
return modelEval(tree['right'], inData)
#创建预测树
def createForeCast(tree, testData, modelEval=regTreeEval):
#测试集的样本数
m=len(testData)
#初始化每个样本的预测值为1
yHat = mat(zeros((m,1)))
#遍历所有样本
for i in range(m):
#计算当前样本的预测值
yHat[i,0] = treeForeCast(tree, mat(testData[i]), modelEval)
#返回所有样本数的预测值
return yHat
def test():
trainMat = mat(loadDataSet("E:\Python36\bikeSpeedVsIq_train.txt"))
testMat = mat(loadDataSet("E:\Python36\bikeSpeedVsIq_test.txt"))
myTree = createTree(trainMat, ops=(1,20))
yHat = createForeCast(myTree, testMat[:,0])
print ("回归树的皮尔逊相关系数:",corrcoef(yHat, testMat[:,1], rowvar=0)[0,1])
myTree = createTree(trainMat, modelLeaf, modelErr,(1,20))
yHat = createForeCast(myTree, testMat[:,0], modelTreeEval)
print ("模型树的皮尔逊相关系数:",corrcoef(yHat, testMat[:,1], rowvar=0)[0,1])
ws, X, Y = linearSolve(trainMat)
print ("线性回归系数:",ws)
for i in range(shape(testMat)[0]):
yHat[i] = testMat[i,0]*ws[1,0] + ws[0,0]
print ("线性回归模型的皮尔逊相关系数:",corrcoef(yHat, testMat[:,1], rowvar=0)[0,1])
def run():
import matplotlib.pyplot as plt
dataSet=loadDataSet('E:\Python36\bikeSpeedVsIq_train.txt')
testSet=loadDataSet('E:\Python36\bikeSpeedVsIq_test.txt')
tree=createTree(mat(dataSet),ops=(1,20))
yHat=createForeCast(tree,mat(testSet))
print (corrcoef(yHat.T,mat(testSet)[:,1].T))
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(array(dataSet)[:,0],array(dataSet)[:,1],c='cyan',marker='o')
plt.show()这里测试的时候存在问题:TypeError: float() argument must be a string or a number, not 'tuple',还未解决