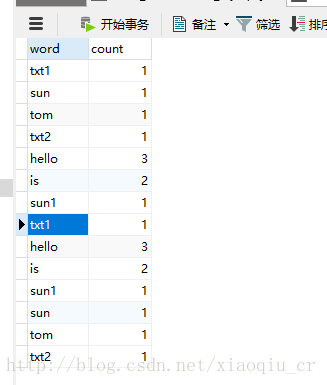
1、建立数据库表
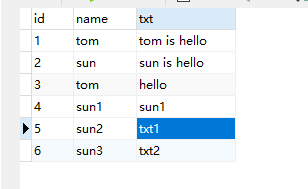
2、导入jar包
mysql-connector-java-5.1.38.jar
3、创建实体类
package com.cr.jdbc;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class MyDBWritable implements DBWritable,Writable{
private String id;
private String name;
private String txt;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getTxt() {
return txt;
}
public void setTxt(String txt) {
this.txt = txt;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyDBWritable that = (MyDBWritable) o;
if (id != null ? !id.equals(that.id) : that.id != null) return false;
if (name != null ? !name.equals(that.name) : that.name != null) return false;
return txt != null ? txt.equals(that.txt) : that.txt == null;
}
@Override
public int hashCode() {
int result = id != null ? id.hashCode() : 0;
result = 31 * result + (name != null ? name.hashCode() : 0);
result = 31 * result + (txt != null ? txt.hashCode() : 0);
return result;
}
//串行化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(name);
out.writeUTF(txt);
}
//反串行化
@Override
public void readFields(DataInput in) throws IOException {
id = in.readUTF();
name = in.readUTF();
txt = in.readUTF();
}
//写入DB
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setString(1,id);
ps.setString(2,name);
ps.setString(3,txt);
}
//从DB读取
@Override
public void readFields(ResultSet rs) throws SQLException {
id = rs.getString(1);
name = rs.getString(2);
txt = rs.getString(3);
}
}
4、mapper读取数据库内容,获取需要统计的字段,转换输出格式为text---intwritable
package com.cr.jdbc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class JDBCMapper extends Mapper<LongWritable, MyDBWritable,Text,IntWritable> {
@Override
protected void map(LongWritable key, MyDBWritable value, Context context) throws IOException, InterruptedException {
System.out.println("key--->"+key);
String line = value.getTxt();
System.out.println(value.getId() + "-->" + value.getName()+"--->"+value.getTxt());
String[] arr = line.split(" ");
for(String s : arr){
context.write(new Text(s),new IntWritable(1));
}
}
}
5、reducer进行聚合统计单词的个数
package com.cr.jdbc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class JDBCReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable iw:values){
count += iw.get();
}
context.write(key,new IntWritable(count));
}
}
6、设置主类app
package com.cr.jdbc;
import com.cr.skew.SkewMapper;
import com.cr.skew.SkewReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.mortbay.jetty.security.UserRealm;
import java.io.IOException;
public class JDBCApp {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//单例作业
Configuration conf = new Configuration();
conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance(conf);
System.setProperty("hadoop.home.dir","E:\hadoop-2.7.5");
//设置job的各种属性
job.setJobName("MySQLApp"); //设置job名称
job.setJarByClass(JDBCApp.class); //设置搜索类
job.setInputFormatClass(DBInputFormat.class);
String driverClass = "com.mysql.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/test_mysql";
String userName = "root";
String passWord = "root";
//设置数据库配置
DBConfiguration.configureDB(job.getConfiguration(),driverClass,url,userName,passWord);
//设置数据输入内容
DBInputFormat.setInput(job,MyDBWritable.class,"select id,name,txt from student","select count(*) from student");
//设置输出路径
Path path = new Path("D:\db\out");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job,path);
job.setMapperClass(JDBCMapper.class); //设置mapper类
job.setReducerClass(JDBCReducer.class); //设置reduecer类
job.setMapOutputKeyClass(Text.class); //设置之map输出key
job.setMapOutputValueClass(IntWritable.class); //设置map输出value
job.setOutputKeyClass(Text.class); //设置mapreduce 输出key
job.setOutputValueClass(IntWritable.class); //设置mapreduce输出value
job.setNumReduceTasks(3);
job.waitForCompletion(true);
}
}
7、运行结果
part-r-00000
txt1 1
part-r-00001
sun 1
tom 1
txt2 1
tom 1
txt2 1
part-r-00002
hello 3
is 2
sun1 1
is 2
sun1 1
8、将统计的结果写入数据库中
建立输出数据表
在实体类中添加字段
//导出字段
private String word = "";
private int count = 0;修改串行化和反串行化方法,以及修改数据库的写入方法
//串行化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(name);
out.writeUTF(txt);
out.writeUTF(word);
out.writeInt(count);
}
//反串行化
@Override
public void readFields(DataInput in) throws IOException {
id = in.readUTF();
name = in.readUTF();
txt = in.readUTF();
word = in.readUTF();
count = in.readInt();
}
//写入DB
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setString(1,word);
ps.setInt(2,count);
}
//从DB读取
@Override
public void readFields(ResultSet rs) throws SQLException {
id = rs.getString(1);
name = rs.getString(2);
txt = rs.getString(3);
}修改reducer,修改输出类型为dbwritable,nullwritable
public class JDBCReducer extends Reducer<Text,IntWritable,MyDBWritable,NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable iw:values){
count += iw.get();
}
MyDBWritable keyOut = new MyDBWritable();
keyOut.setWord(key.toString());
keyOut.setCount(count);
context.write(keyOut, NullWritable.get());
}
}在主类app中修改输出路径
//设置数据库输出
DBOutputFormat.setOutput(job,"word_count","word","count");运行
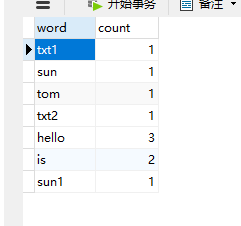
9、运行于Hadoop集群
1、导出jar包,放到集群
2、为每个节点分发MySQL-connector驱动jar包
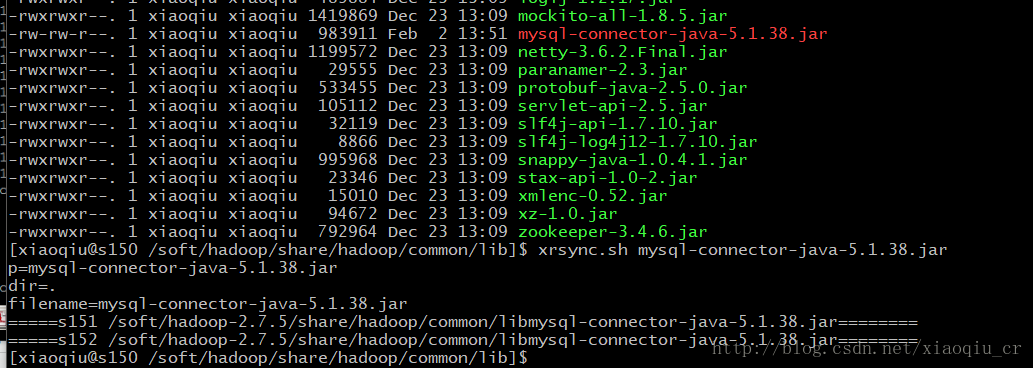
3、运行jar包
[xiaoqiu@s150 /home/xiaoqiu]$ hadoop jar wordcounter.jar com.cr.jdbc.JDBCApp
4、结果