接前文,我们继续说剩下的4个Materialization节点。
7.SetOp节点
SetOp节点用于处理集合操作,对应于SQL语句中的EXCEPT、INTERSECT两种集合操作,至于另一种集合操作UNION,可直接由Append节点来实现。
一个SetOp节点只能处理一个集合操作(由两个集合参与),如果有多个集合操作则需要组合多个SetOp节点来实现。SetOp节点仅有一个左子节点作为输人,其左子节点是一个Append节点或者是一个Sort节点(Sort节点的子节点是一个Append节点),其低层的Append节点中只放置两个子计划用于表示参与集合操作的左集合和右集合。由于进行集合操作时需要区分元组来自哪一个子査询,因此在低层Append节点的投影操作时会为每个子计划输出元组增加一个子计划标记属性(见下面的例子)。
postgres=# explain (select id from test_dm) except (select id from test_dm2);
QUERY PLAN
-----------------------------------------------------------------------------------------
HashSetOp Except (cost=0.00..383303.38 rows=1000000 width=4)
-> Append (cost=0.00..355803.34 rows=11000017 width=4)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..32346.00 rows=1000000 width=4)
-> Seq Scan on test_dm (cost=0.00..22346.00 rows=1000000 width=4)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..323457.34 rows=10000017 width=4)
-> Seq Scan on test_dm2 (cost=0.00..223457.17 rows=10000017 width=4)
(6 行)
SetOp有两种执行策略:排序(SETOP_SORTED)和Hash (SETOP_HASHED)。
-
排序策略下首先利用Sort节点对Append节点返回的元组集合进行排序,然后进行交、差的集合操作;
-
Hash策略下则通过SetOp节点提供Hash表对子査询元组进行Hash分组,然后进行集合操作。
在Hash策略下,SetOp节点的左子节点就是Append节点。在SetOp执行过程中需要附加子计划标记属性,这个属性在输人元组中的偏移位置被记录在SetOp节点的flagColIdx字段中。SetOp节点的定义如下:
typedef struct SetOp
{
Plan plan;
SetOpCmd cmd; /* what to do */
SetOpStrategy strategy; /* how to do it */
int numCols; /* number of columns to check for
* duplicate-ness */
AttrNumber *dupColIdx; /* their indexes in the target list */
Oid *dupOperators; /* equality operators to compare with */
AttrNumber flagColIdx; /* where is the flag column, if any */
int firstFlag; /* flag value for first input relation */
long numGroups; /* estimated number of groups in input */
} SetOp;
其中除了标志属性的位置外,还有用于去重的属性号数组(dupColIdx)和相应的操作符OID数组(dupOperators)等信息,这两个数组用于判断元组是否相同。
typedef struct SetOpStatePerGroupData
{
long numLeft; /* number of left-input dups in group */
long numRight; /* number of right-input dups in group */
} SetOpStatePerGroupData;
SetOp节点在执行时会对从左子节点中取到的每一个元组,会使用一个SetOpStatePerGroupData结构(该结构会在每次获取元组时复用)来存储每个元组的状态。具体地就是利用numLeft和numRight变量来记录该元组在左集合和右集合中出现的次数,然后根据集合操作命令的类型来确定该元组是否应该作为结果元组返回:
typedef enum SetOpCmd
{
SETOPCMD_INTERSECT,
SETOPCMD_INTERSECT_ALL,
SETOPCMD_EXCEPT,
SETOPCMD_EXCEPT_ALL
} SetOpCmd;
-
1)SETOPCMD_INTERSECT:对应INTERSECT操作,最后的结果集合中不会有重复元组。其实现方式是,如果一个元组的numLeft和mimRight都大于0,则只输出一次该元组。
-
2)SETOPCMD_INTERSECT_ALL:对应于INTERSECT ALL操作,最后的结果集中允许有重复元组。其实现方式是,输出该元组的次数以rmmLeft和mimRight的较小者为准。
-
3)SETOPCMD_EXCEPT:对应于EXCEPT操作,表示要求返回只出现在左集合中的元组,且结果集合中不存在重复元组。如果一个元组的mimLeft大于0而mimRight等于0,则输出一次该元组。
-
4)SETOPCMD_EXCEPT_ALL:对应于EXCEPT ALL操作,结果集合中允许存在重复元组。如果一个元组的numLeft不小于numRight,则输出numLeft - numRight次该元组。
SETOP_SORTED策略的下层节点已经将需要执行的集合的操作合并在一起并进行了排序,SetOp 节点需要做的事情类似于 Group 节点:首先从下层节点获取一个分组的元组,仅缓存第一条元组,然后统计它在左右集合中的出现次数,然后通过集合操作的命令类型来决定如何返回元组。
SETOP_HASHED策略的下层节点会依次返回两个子计划(对应于左右两个集合)中的元组。首先计算左集合中每个元组的Hash值,如果Hash表中没有,则插人Hash表中,否则,将其中Hash项内mimLeft计数加1。然后扫描右集合,计算Hash值后在Hash表中査找,找到则对numRight计数加1,否则,不进行任何操作。扫描完成后,会依次从Hash表中获取元组和其对应的numLeft和numRight,根据集合操作的命令类型来决定如何返回元组。
8.Limit节点
Limit节点主要用来处理LIMIT/OFFSET子句,它从下层节点的输出中挑选处于一定范围内的元组(见下面的例子)。该节点只有一个左子节点。
postgres=# explain select id from test_new limit 5 ;
QUERY PLAN
------------------------------------------------------------------
Limit (cost=0.00..0.07 rows=5 width=4)
-> Seq Scan on test_new (cost=0.00..35.50 rows=2550 width=4)
(2 行)
Limit节点定义如下所示,它在Plan的基础上扩展定义了limitOffset和limitCount两个表达式,用于计算偏移量和需要返回元组的数量。
typedef struct Limit
{
Plan plan;
Node *limitOffset; /* OFFSET parameter, or NULL if none */
Node *limitCount; /* COUNT parameter, or NULL if none */
} Limit;
在初始化过程中,会对Limit节点的limitOffset和limitCount两个表达式进行初始化,结果保存于LimitState节点的limitOffset和limitCount 字段中。
typedef struct LimitState
{
PlanState ps; /* its first field is NodeTag */
ExprState *limitOffset; /* OFFSET parameter, or NULL if none */
ExprState *limitCount; /* COUNT parameter, or NULL if none */
int64 offset; /* current OFFSET value */
int64 count; /* current COUNT, if any */
bool noCount; /* if true, ignore count */
LimitStateCond lstate; /* state machine status, as above */
int64 position; /* 1-based index of last tuple returned */
TupleTableSlot *subSlot; /* tuple last obtained from subplan */
} LimitState;
在执行过程中,需要首先计算LimitState中的limitOffset和limitCount表达式,将结果保存于offset和count中,然后开始从下层节点获取元组,通过portion记录已获取的元组数目,跳过前offset个元组,从offset + 1个元组开始返回,并在offset + count处直接返回空元组。
Limit节点的执行函数ExecLimit主要地就是根据子查询过滤获取元组,根据LIMIT节点当前的状态(LimitStateCond)做出不同的处理。
typedef enum
{
LIMIT_INITIAL, /* initial state for LIMIT node */
LIMIT_RESCAN, /* rescan after recomputing parameters */
LIMIT_EMPTY, /* there are no returnable rows */
LIMIT_INWINDOW, /* have returned a row in the window */
LIMIT_SUBPLANEOF, /* at EOF of subplan (within window) */
LIMIT_WINDOWEND, /* stepped off end of window */
LIMIT_WINDOWSTART /* stepped off beginning of window */
} LimitStateCond;
我们需要注意的是,当下层节点是Sort时,要做一个小小的“优化”(pass_down_bound函数):即如果指定了limit数和offset数,那么我们就知道我们到底需要多少个排序好的元组,那么Sor节点就可以采取相应的策略,选取合适的排序方法(bounded sort),详情见Sort节点中的puttuple_common函数,同样在这篇里面有。
9.WindowAgg节点
先上例子:
postgres=# explain select avg(id) OVER ( PARTITION BY xxx) from test_dm;
QUERY PLAN
------------------------------------------------------------------------------
WindowAgg (cost=122003.84..139503.84 rows=1000000 width=23)
-> Sort (cost=122003.84..124503.84 rows=1000000 width=23)
Sort Key: xxx
-> Seq Scan on test_dm (cost=0.00..22346.00 rows=1000000 width=23)
(4 行)
WindowAgg节点用于处理窗口函数,窗口函数用于在与当前元组相关的一组元组上执行相关函数计算(包括在GROUP BY中使用的聚集函数)。窗口函数的使用类似于“SELECT ..., avg (x) OVER (PARTITION BY y) FROM x;” 的方式。
通常,GROUP BY子句存在时,查询无法投影非分组属性,非分组属性只能出现在聚集函数中。在实际应用中可能需要投影非分组属性,例如,表class记录了班级(cno)、民族(nation)、人数(mim),若需要统计班级中的各民族所占比例,使用GROUP BY就无法实现,如果使用窗口函数,可以使用如下语句:
SELECT cnof nation, mim/sum(nuin) OVER (PARTITION BY cno)AS present FROM class;
上面的SQL语句中,将sum函数运用在与当前元组具有相同cno的一组元组上,并利用此聚合得到的总人数,计算出当前人数在总人数中的比例。这样能够实现更加灵活的函数操作,提供了更加丰富的査询方法。
窗口函数与在GROUP分组中进行聚集计算的不同主要体现在SQL语义上,在聚集函数的计算上两者是相似的。窗口函数需要处理与当前元组相关联的一组元组,在实现中要保留同一划分内的所有元组,计算得到聚集函数值后,再进行相关的投影操作。因此,在实现方法上,不论是PARTITION还是GROUP都需要先将元组在分组属性上进行划分,在分组过程和聚集函数计算的实现上是相似的。
WindowAgg节点实现的功能类似于Agg节点,但不同点在于窗口函数不会造成同一分组中的元组被合并为一个,因此每个元组都可以生成一个结果元组,并可包含相关的聚集运算结果。WindowAgg节点只有一个左子节点,用于提供已经在分组属性(PARTITION BY所指定的属性)上排序的元组。
如下图所示,WindowAgg节点定义中包含用于存储分区函数和所对应属性号的数组 partOperalors 和 partColIdx、数组长度partNumCds以及在排序属性上判断是否相等的函数和相应的属性号数组ordlOperators 和 ordColIdx,数组长度用 ordNumCols记录。
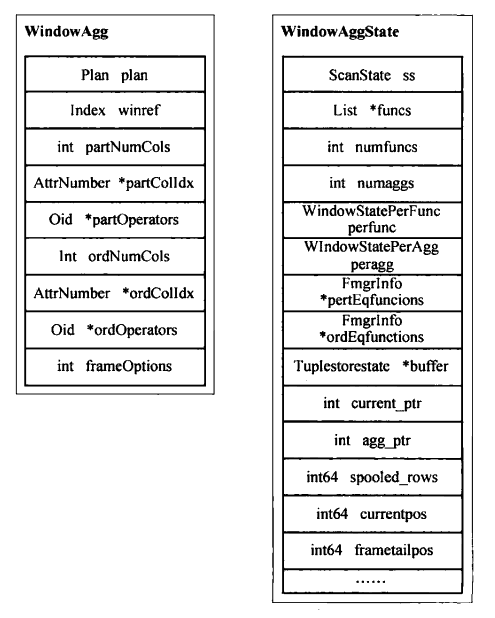
窗口函数也使用了 Agg节点的聚集函数迭代计算方法,其实现方式是在Agg节点的AGG_SORTED策略的执行中增加了缓存分组内所有元组的tuplestore结构,保存于状态节点中的buffer字段中。由于窗口函数不仅包含Agg中支持的聚集函数,还有新的窗口函数模式(能够支持随机的在分组内获取元组等),因此,在从Plan的targellist中获取WindowFimc,并将其信息初始化为perfunc指向的WindowStatePerFunc数组后,需要将传统的聚集函数构造成新的WindowSlatePerAgg链表,以便在调用聚集函数处理过程中使用与Agg节点相同的方式。
初始化过程中,通过WindowAgg节点的targetlist构造funcs链表,其中包含窗口函数的表达式树。然后对funcs指向的表达式树进行初始化,构造函数相关调用信息存放于perfunc指向的数组中。对于传统的聚集函数,将在peragg中另外多初始化一个与Agg节点处理聚集函数时相同的数据结构,用于执行聚集计算。然后要对于分区判断函数和排序属性是否相等的操作函数进行初始化,分别保存于 perEqfuctions 和 ordEqfuntions 中。
在执行过程中,首先初始化一个tuplestore结构用于缓存元组,使用perEqfunctions判断是否在分区内:
-
1)如果有传统的聚集类函数,获取分区内的所有元组缓存于tuplestore中。然后计算其聚集函数值,并将该值保存在对应函数信息WindowStatePerAgg结构的resultValue中。依次获取分区每条元组,计算窗口函数,使用缓存的聚集函数结果进行投影。
-
2)否则,直接扫描分区每条元组,计算该窗口函数,并对结果元组进行投影后返回。
10.LockRows节点
关于这个节点,我查了下用户手册,发现它是用来支持Postgres中的行级锁,详情见http://www.postgres.cn/docs/9.5/explicit-locking.html
上例子:
postgres=# explain select id from test_new where id < 5 for share;
QUERY PLAN
------------------------------------------------------------------
LockRows (cost=0.00..50.38 rows=850 width=10)
-> Seq Scan on test_new (cost=0.00..41.88 rows=850 width=10)
Filter: (id < 5)
(3 行)
LockRows节点在Plan节点的基础上扩展了两个字段,rowMarks记录的是该rowMarks节点所锁定的关系(relation)的列表;epqParam参数我们不会陌生了,它是和EvalPlanQual函数相关的,以后我们看到参数名里面有EPQ的我们就知道他就是做recheck相关的工作的参数。
(关于EvalPlanQual函数,我们可以看src/backend/executor/README文件的EvalPlanQual (READ COMMITTED Update Checking)部分,或者直接EvalPlanQual的源码。)
typedef struct LockRows
{
Plan plan;
List *rowMarks; /* a list of PlanRowMark's */
int epqParam; /* ID of Param for EvalPlanQual re-eval */
} LockRows;
这样我们就知道,这个节点的事情很简单,就是以指定的方式(FOR SHARE/FOR UPDATE)锁住Postgres表中的一些行的操作。
在初始化时,初始化LockRowsState结构。为其创建outer plan,创建为锁表而使用的工作空间(初始化lr_curtuples和lr_ntables)。根据全局状态Estate中es_rowMarks的字段,定位到每个ExecRowMark结构并为其构造ExecAuxRowMark结构,最后调用EvalPlanQualInit为其初始化EPQ(又是EPQ).
typedef struct LockRowsState
{
PlanState ps; /* its first field is NodeTag */
List *lr_arowMarks; /* List of ExecAuxRowMarks */
EPQState lr_epqstate; /* for evaluating EvalPlanQual rechecks */
HeapTuple *lr_curtuples; /* locked tuples (one entry per RT entry) */
int lr_ntables; /* length of lr_curtuples[] array */
} LockRowsState;
在执行时,简而言之就是根据所要求的锁定的方式,锁定子节点输出的元组并将该元组返回到上层。
在结束时,由于初始化了EPQ,所以结束时要额外调用EvalPlanQualEnd结束EPQ结构。
Materialization节点就是这么多~