简介
我们知道计算机最先兴起是在国外,出于当时计算机性能的考虑和外国常用字符的考虑,最开始计算机使用的是ASCII,ASCII编码能够表示的字符毕竟是有限的,随着计算机的发展和全世界范围的流行,需要更多的能够表示世界各地字符的编码方式,这种编码方式就是unicode。
当然在unicode出现之前,各个国家或者地区根据本国的字符需求都制定过本国的编码标准,当然这些编码标准都是本地化的,不适用于全世界,所以并没有得到普及。
今天我们来讨论一下unicode编码的字符进行排序和正则匹配的问题。
ASCII字符的排序
ASCII的全称叫做American Standard Code for Information Interchange,也就是美国信息交换标准代码,到目前为止,ASCII只有128个字符。这里不详细讨论ASCII字符的构成。感兴趣的同学可以查看我之前写的关于unicode的文章。
ASCII字符包含了26个字母,我们看下在javaScript中怎么对ASCII字符编码的:
const words = ['Boy', 'Apple', 'Bee', 'Cat', 'Dog'];
words.sort();
// [ 'Apple', 'Bee', 'Boy', 'Cat', 'Dog' ]
可以看到,这些字符是按照我们想要的字典的顺序进行排序的。
但是如果你将这些字符修改成中文,再进行排序,那么就得到的并不是我们想要的结果:
const words = ['爱', '我', '中', '华'];
words.sort();
// [ '中', '华', '我', '爱' ]
这是为什么呢?
其实默认的这种sort是将字符串转换成字节,然后按照字节进行字典顺序排序。如果是中文,那么并不会将其进行本地文字的转换。
本地字符的排序
既然使用ASCII字符不能对中文进行排序,那么我们其实是想将汉字转换为拼音,然后按照拼音字母的顺序来对其排序。
所以上面的”爱我中华“实际上是要比较”ai“、”wo“、”zhong“、”hua“ 这几个拼音的顺序。
有什么简单的方法来进行比较吗?
在一些浏览器中提供了Intl.Collator和String.prototype.localCompare两种方法来进行本地字符的比较。
比如我在chrome 91.0版本中:

使用Intl.Collator是可以得到结果的,而使用String.prototype.localCompare并不行。
再看下在firfox 89.0版本中:

结果和chrome是一致的。
下面是在nodejs v12.13.1版本的执行结果:
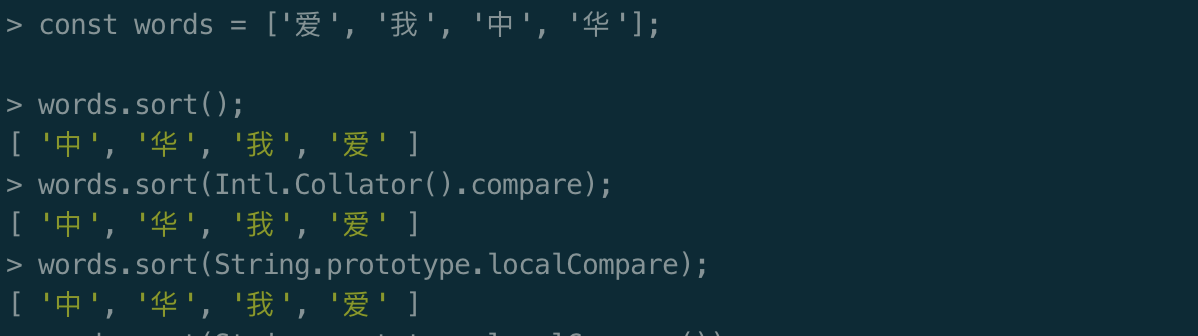
可以看到在nodejs中,并没有进行本地字符的转换和排序。
所以,上述的两个方法是和浏览器有关系的,也就是说和具体的实现是相关的。我们并不能完全对其信任。
所以,要给字符串进行排序是一件非常傻的事情!
为什么不使用unicode进行排序
那么为什么不使用unicode进行排序呢?
首先,对于普通用户来说,他们并不知道unicode,他们所需要的也就是将字符串转换为本地语言进行字典排序。
其次,即使使用本地字符进行排序也是非常困难的一件事情,因为浏览器需要对不同的语言进行本地化排序支持。这使得工作量变得巨大。
emoji的正则匹配
文章最后,我们来讲一下emoji的正则匹配问题。
emoji是一系列的表情,我们可以使用unicode来对其表示,但是emoji表情非常多,差不多有3521个,如果要对emoji进行正则匹配,我们需要写出下面的代码:
(?:ud83euddd1ud83cudffbu200du2764ufe0fu200dud83dudc8bu200dud83euddd1ud83cudffc|ud83euddd1ud83cudffbu200du2764ufe0fu200dud83d
[... 后面省略很多]
以一个图像来直观的看一下emoji表情有多少:
这么多的emoji,有没有简单的办法对其进行正则匹配呢?答案是有的。
早在ECMAScript的TC39提议里面,就已经把emoji的正则匹配加入了标准之中,我们可以使用{Emoji_Presentation}来表示。
p{Emoji_Presentation}
是不是很简单?
总结
本文简单介绍了本地字符的排序规则和emoji表情的正则匹配。希望能够给大家在实际工作中带来帮助。
本文已收录于 http://www.flydean.com/04-unicode-sorting/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!